
Chapter 82: Process Address Space: Kernel Space vs. User Space Layout
Chapter Objectives
By the end of this chapter, you will be able to:
- Understand the concept of virtual memory and its role in modern operating systems like Embedded Linux.
- Explain the fundamental division between kernel space and user space and the security implications of this design.
- Identify and describe the key segments of a process’s user space address layout: text, data, BSS, heap, and stack.
- Implement C programs that demonstrate the use of each memory segment and use command-line tools to inspect the memory layout of executables and running processes.
- Debug common memory-related issues such as stack overflows and heap corruption in an embedded context.
- Analyze the memory map of a running process on a Raspberry Pi 5 using the
/procfilesystem.
Introduction
In the world of embedded systems, efficiency and stability are paramount. An embedded device, whether a smart thermostat, an automotive control unit, or an industrial sensor, is expected to run reliably for extended periods, often with limited resources. Understanding how a program manages memory is not merely an academic exercise; it is a critical skill for any embedded Linux developer. This chapter delves into one of the most fundamental concepts of the Linux operating system: the process address space.
We will explore the elegant abstraction of virtual memory, which provides every single process with its own private, standardized view of the system’s memory. This architecture is the bedrock upon which process isolation, security, and stability are built. We will dissect the layout of this virtual space, drawing a clear line between the privileged kernel space, where the operating system’s core resides, and the restricted user space, where our applications run. You will learn how the system carefully orchestrates the transition between these two realms through system calls.
Using the Raspberry Pi 5 as our practical development platform, we will move from theory to practice. You will learn to identify the distinct segments within a user process—the text, data, BSS, heap, and stack—and understand the purpose of each. By compiling code and using standard Linux inspection tools, you will see firsthand how your source code translates into a structured memory layout. This knowledge is indispensable for writing efficient code, optimizing memory usage, and debugging some of the most challenging bugs you will encounter in your career.
Technical Background
The Illusion of Private Memory: Virtual Address Spaces
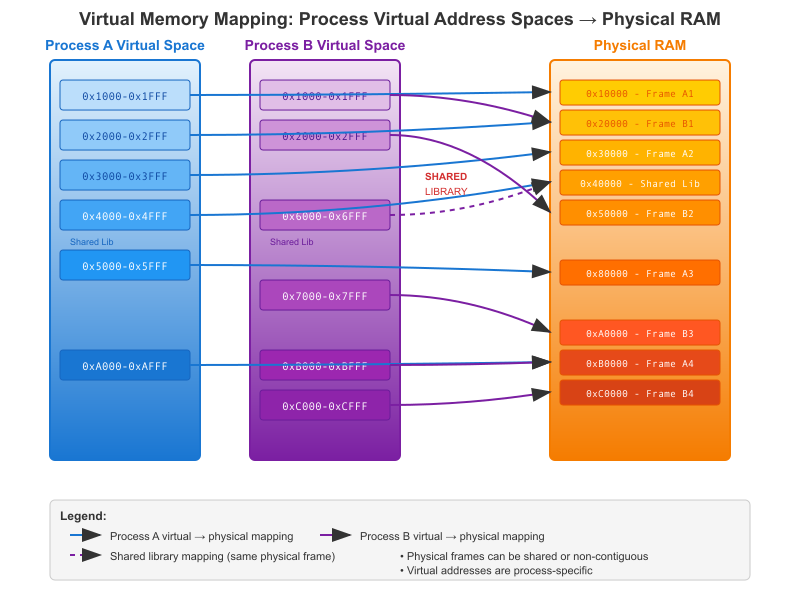
Every time you run a program on a Linux system, from a simple “Hello, World!” application to a complex graphical interface, the operating system performs a remarkable feat of abstraction. It grants the program, now a process, its own private and contiguous view of the system’s memory. This is known as the virtual address space. The process operates under the illusion that it has exclusive access to a vast, linear range of memory addresses, typically starting from address 0 and extending up to a very large number (e.g., 248 or 264 on 64-bit systems).
This illusion is crucial for two primary reasons: simplicity and security. From a programmer’s perspective, you don’t need to worry about where your code will physically reside in RAM. You can write code that assumes a standardized memory layout, making programs portable and easier to develop. From a security and stability standpoint, this virtualization is non-negotiable. Because each process lives in its own sandboxed address space, one misbehaving process cannot read or corrupt the memory of another process, nor can it directly interfere with the core operating system.
The magic behind this is the Memory Management Unit (MMU), a piece of hardware present in most modern processors, including the ARM Cortex-A76 cores in the Raspberry Pi 5. The MMU, in conjunction with the Linux kernel, acts as a translator. When a process accesses a virtual address, the MMU looks up this address in a set of translation tables (called page tables) maintained by the kernel. These tables map the virtual address to a physical address in the system’s RAM. If a valid mapping exists, the hardware fetches the data from the physical RAM. If not, the MMU triggers a page fault, an exception that transfers control to the kernel to resolve the situation. This might involve loading the required data from a storage device into RAM, or, if the address is invalid, terminating the process with a segmentation fault.
The Great Divide: Kernel Space and User Space
The virtual address space of every process is not a monolithic block. It is split into two distinct regions: user space and kernel space. This division is a fundamental security mechanism enforced by the processor’s privilege levels.
User space is the portion of the address space where the application’s code and data reside. This is the unprivileged world. Code executing in user space has restricted access to the system’s hardware and resources. It cannot directly manipulate hardware devices, modify the page tables, or interfere with other processes. Your application code, the C standard library, and other shared libraries all live and execute within this space.
Kernel space, on the other hand, is the privileged domain of the operating system itself. This region of the virtual address space is mapped into every process’s memory map, but it is only accessible when the processor is in a privileged state (kernel mode). It contains the core kernel code and data structures that manage the entire system, including the process scheduler, memory manager, device drivers, and networking stack. When a user process needs the operating system to perform a privileged operation—such as reading a file, sending data over the network, or allocating more memory—it cannot do so directly. Instead, it must make a request to the kernel.
This request is made through a highly controlled and well-defined mechanism called a system call. A system call is a special instruction (like SVC on ARM architectures) that causes the processor to trap into kernel mode, transferring control to a specific entry point in the kernel. The kernel then validates the request, performs the required operation on behalf of the user process, and finally returns control back to the user process, switching the processor back to the unprivileged user mode. This user/kernel boundary is the cornerstone of Linux’s stability. A crash in a user-space application will typically only terminate that single process, while the kernel and the rest of the system continue to run unaffected.
sequenceDiagram
actor User as User Process
participant libc as C Library (libc)
participant Kernel
actor HW as Hardware (CPU)
User->>+libc: Calls function (e.g., read(fd, buf, n))
libc->>libc: Prepares for system call <br> (loads args into registers)
libc->>+HW: Executes TRAP instruction (e.g., SVC)
Note over HW: CPU switches to Kernel Mode
HW->>+Kernel: Transfers control to syscall handler
Kernel->>Kernel: Verifies arguments
Kernel->>Kernel: Executes corresponding kernel function <br> (e.g., sys_read())
Kernel->>HW: Accesses device/data
HW-->>-Kernel: Returns data/status
Note over HW: CPU switches back to User Mode
Kernel-->>HW: Executes return-from-trap instruction
HW-->>libc: Returns control to C library
libc-->>User: Returns result of read() call
On a typical 64-bit Linux system, the virtual address space is often split such that the lower addresses constitute user space (e.g., from address 0 up to a certain high boundary) and the highest addresses constitute kernel space. The exact split can vary, but the principle remains the same.

Anatomy of the User Space
While the kernel’s layout is complex and dynamic, the layout of the user space portion of a process’s address space follows a conventional and predictable structure. When you compile and run a program, the loader arranges its code and data into several distinct segments. Let’s examine these segments, typically visualized as starting from the lowest addresses and moving up.
1. The Text Segment (.text)
At the very bottom of the user space layout is the text segment, also known as the code segment. This segment contains the compiled, machine-code instructions of your program. When the CPU executes your program, its program counter points to addresses within this segment. To prevent a program from accidentally or maliciously modifying its own instructions, the text segment is marked by the kernel as read-only and executable. Any attempt to write to this region of memory will result in a segmentation fault. This is a critical security feature that helps protect against certain types of attacks.
2. The Data Segment (.data)
Immediately following the text segment is the data segment. This segment stores all the initialized global and static variables from your program. These are variables that are declared outside of any function (global) or with the static keyword, and which have an explicit initial value in your source code. For example, the variable int max_retries = 10; declared globally would have its value, 10, stored in the data segment. The size of this segment is fixed at compile time and is loaded directly from the executable file into memory when the program starts.
3. The BSS Segment (.bss)
The BSS segment (named after an old assembler operator, “Block Started by Symbol”) is a close cousin of the data segment. It holds all the uninitialized global and static variables. In C, if you declare a global variable like int sensor_readings[1024]; without providing initial values, the C standard dictates that it must be initialized to zero (or null for pointers). Instead of storing a large block of zeros in the executable file on disk, which would be wasteful, the compiler simply records the size of the BSS segment. When the program is loaded, the Linux kernel allocates a block of memory of this size and fills it with zeros. This is an optimization that keeps executable files smaller. Therefore, the BSS segment occupies memory at runtime but contributes almost nothing to the size of the executable file itself.
4. The Heap
Moving up in the address space, we encounter the heap. The heap is the region of memory used for dynamic memory allocation. Unlike the static and global variables in the .data and .bss segments, whose size is fixed at compile time, the heap provides memory that can be requested and released by the program at runtime. In C, this is managed through library functions like malloc(), calloc(), realloc(), and free().
The heap is typically located above the BSS segment and grows upwards towards higher memory addresses as more memory is requested. The kernel manages the top of the heap via a pointer often called the program break. When you call malloc(), the C library might be able to satisfy your request from a pool of already-allocated memory it manages. If not, it will perform a system call (like brk() or sbrk()) to ask the kernel to move the program break upwards, thus expanding the heap and making more memory available to the process. Managing heap memory is entirely the programmer’s responsibility. Failing to free() memory that is no longer needed leads to memory leaks, a severe problem in long-running embedded systems where memory is a finite resource.
5. The Memory Mapping Segment
Between the heap and the stack, there is a large, variable region of the address space used for memory-mapped files and shared libraries. When your program uses a shared library (like libc.so), the loader doesn’t copy the library’s code into your process’s text segment. Instead, it uses the mmap() system call to map the library’s file from disk directly into this middle region of the process’s virtual address space. The beauty of this is that if multiple processes on the system are using the same library, they can all map the same physical RAM pages containing the library’s code into their own distinct virtual address spaces. This is a highly efficient use of system memory. This region can also be used to map regular files into memory for easier access.
6. The Stack
At the very top of the user space is the stack. The stack is a crucial segment used for managing function calls. Every time a function is called, a new stack frame is pushed onto the stack. This frame contains the function’s local variables, its arguments, and the return address—the location in the text segment where execution should resume after the function completes.
Unlike the heap, which grows upwards, the stack on most architectures (including ARM) grows downwards from the top of the user address space towards the lower addresses. This downward growth provides a large, flexible space between the stack and the upward-growing heap, allowing both to expand without colliding (unless the program uses an extreme amount of memory). When a function returns, its stack frame is popped off the stack, automatically freeing the memory used by its local variables. This automatic management is why you don’t need to free() local variables. However, this also means the stack has a finite size. If a program has a function that calls itself infinitely (infinite recursion) or declares a very large local variable (e.g., char buffer[20000000];), it can exhaust the available stack space. This condition is called a stack overflow, which usually results in the program crashing.

Practical Examples
Theory is best understood through practice. In this section, we will use a Raspberry Pi 5 to explore the process address space of a real C program. We will compile the code, inspect the executable, and then analyze the running process.
Hardware and Software Setup
- Hardware: Raspberry Pi 5
- Operating System: Raspberry Pi OS (64-bit) or a custom embedded Linux build.
- Tools: GCC compiler,
make,size,objdump,readelf, and access to the command line.
Step 1: The Sample C Program (memory_layout.c)
Let’s create a C program that explicitly uses variables in each of the key memory segments. This will allow us to see how the compiler and loader treat each one.
// memory_layout.c
// A program to demonstrate the process memory layout in Linux.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
// Initialized global variable -> Stored in the .data segment
int initialized_global = 123;
// Uninitialized global variable -> Stored in the .bss segment
int uninitialized_global;
// Initialized static global variable -> Also in .data
static const char* message = "Hello, Embedded World!";
// Uninitialized static global variable -> Also in .bss
static char bss_buffer[1024];
void function_with_locals() {
// Local variable -> Stored on the stack
int local_variable = 456;
printf("--- Inside function_with_locals() ---\n");
printf("Address of local_variable (stack): %p\n", &local_variable);
printf("-------------------------------------\n");
}
int main() {
// Local variable in main -> Stored on the stack
int main_local = 789;
// Dynamically allocated memory -> Stored on the heap
char *heap_buffer = (char *)malloc(256);
if (heap_buffer == NULL) {
perror("malloc failed");
return 1;
}
// Copy a string into the heap buffer
sprintf(heap_buffer, "This is a dynamic string on the heap.");
printf("Process ID: %d\n", getpid());
printf("--- Memory Addresses ---\n");
// Addresses of functions are in the text segment
printf("Address of main function (text): %p\n", &main);
printf("Address of function_with_locals (text): %p\n", &function_with_locals);
// Addresses of initialized globals are in the data segment
printf("Address of initialized_global (data): %p\n", &initialized_global);
printf("Address of message (data): %p\n", &message);
// Addresses of uninitialized globals are in the bss segment
printf("Address of uninitialized_global (bss): %p\n", &uninitialized_global);
printf("Address of bss_buffer (bss): %p\n", &bss_buffer);
// Address of heap allocation
printf("Address of heap_buffer (heap): %p\n", heap_buffer);
// Address of a local variable on the stack
printf("Address of main_local (stack): %p\n", &main_local);
// Call another function to see its stack frame address
function_with_locals();
printf("\n--- Content ---\n");
printf("Value of initialized_global: %d\n", initialized_global);
printf("Value of uninitialized_global: %d (should be 0)\n", uninitialized_global);
printf("Message: %s\n", message);
printf("Content of heap_buffer: %s\n", heap_buffer);
// Free the dynamically allocated memory
free(heap_buffer);
heap_buffer = NULL;
printf("\nTo inspect the memory map, run 'cat /proc/%d/maps' in another terminal.\n", getpid());
printf("Press Enter to exit...\n");
getchar();
return 0;
}
Step 2: Compiling and Inspecting the Executable
First, compile the program on your Raspberry Pi 5. We don’t need to cross-compile since we are building and running on the same machine.
# Compile the C program
gcc -o memory_layout memory_layout.c
# The command should complete without errors.
Now, let’s use the size utility to get a quick overview of the main segments. The size command displays the sizes (in bytes) of the text, data, and bss sections.
# Use the size command to inspect the executable
size memory_layout
You will see output similar to this (the exact numbers may vary slightly):
text data bss dec hex filename
4033 744 1040 5817 16b9 memory_layout
Analysis of the size output:
- text (1731 bytes): This is the size of our executable code (
main,function_with_locals) plus the code from the C standard library that gets statically linked. - data (640 bytes): This size comes from our initialized global variables (
initialized_globalandmessage). The size is larger than the variables themselves because of padding and other metadata. - bss (1048 bytes): This is primarily from our uninitialized variables (
uninitialized_globaland the 1024-bytebss_buffer). Note that this adds over 1KB to the memory footprint at runtime, but very little to the file size on disk. - dec (3419): The total size in decimal (
text + data + bss). - hex (d5b): The total size in hexadecimal.
For a more detailed view, we can use objdump to see the symbol table, which lists the variables and functions and which section they belong to.
# Use objdump to view the symbol table, filtering for our variables
objdump -t memory_layout | grep -E 'initialized_global|uninitialized_global|message|bss_buffer'
The output will be more verbose, but you should be able to find lines like these:
0000000000020018 l O .data 0000000000000008 message
0000000000020030 l O .bss 0000000000000400 bss_buffer
0000000000020028 g O .bss 0000000000000004 uninitialized_global
0000000000020010 g O .data 0000000000000004 initialized_global
This confirms our understanding: initialized_global and message are in the .data section, while uninitialized_global and bss_buffer are in the .bss section.
Step 3: Running the Program and Analyzing its Live Memory
Now, let’s run the compiled program.
./memory_layout
The program will print the addresses of its variables and then pause. The output will look something like this:
Process ID: 23451
--- Memory Addresses ---
Address of main function (text): 0x558c8b48a9
Address of function_with_locals (text): 0x558c8b4865
Address of initialized_global (data): 0x558c8b58e8
Address of message (data): 0x558c8b58f0
Address of uninitialized_global (bss): 0x558c8b5904
Address of bss_buffer (bss): 0x558c8b5910
Address of heap_buffer (heap): 0x558c9c62a0
Address of main_local (stack): 0x7ffc9a8f3b4c
--- Inside function_with_locals() ---
Address of local_variable (stack): 0x7ffc9a8f3b2c
-------------------------------------
--- Content ---
Value of initialized_global: 123
Value of uninitialized_global: 0 (should be 0)
Message: Hello, Embedded World!
Content of heap_buffer: This is a dynamic string on the heap.
To inspect the memory map, run 'cat /proc/23451/maps' in another terminal.
Press Enter to exit...
Analysis of the Address Output:
- Text Addresses (
0x55...): The function addresses are relatively low. - Data/BSS Addresses (
0x55...): These follow the text segment, at slightly higher addresses. - Heap Address (
0x55...): The heap address is higher still, showing that it resides above the BSS segment. - Stack Addresses (
0x7f...): The stack addresses are at a much, much higher memory location, confirming that the stack resides at the top of the user address space and grows downwards. Notice thatlocal_variableinside the function has a lower address thanmain_local, which is consistent with the stack growing downwards as new frames are pushed.
While the program is paused, open a second terminal to your Raspberry Pi 5. Use the Process ID (PID) printed by the program to inspect its virtual memory map in the /proc filesystem.
# In a second terminal, replace 23451 with the actual PID
cat /proc/23451/maps
The output is a detailed breakdown of every memory region mapped into the process’s address space. You will see many lines, but you can find the ones corresponding to our program:
# The output will look similar to this (simplified for clarity)
# Address Range Perms Offset Dev Inode Pathname
558c8b4000-558c8b5000 r-xp 00000000 103:02 12345 /home/pi/memory_layout <-- Text Segment (r-x)
558c8b5000-558c8b6000 rw-p 00001000 103:02 12345 /home/pi/memory_layout <-- Data & BSS (rw-)
558c9c6000-558c9e7000 rw-p 00000000 00:00 0 [heap] <-- Heap
... (many lines for shared libraries) ...
7ffc9a8d4000-7ffc9a8f5000 rw-p 00000000 00:00 0 [stack] <-- Stack
This live view perfectly matches our theoretical model. We can see the memory_layout executable mapped in with read/execute permissions (the text segment) and again with read/write permissions (the data/BSS segments). We can clearly see the regions explicitly labeled [heap] and [stack] by the kernel, located at the addresses we observed from our program’s output.
Common Mistakes & Troubleshooting
A solid understanding of memory layout is your best defense against subtle and frustrating bugs. Here are some common pitfalls and how to approach them.
Exercises
- Analyze Your Own Program: Write a simple C program that declares one initialized global integer, one uninitialized global char array of 50 bytes, and one local integer in
main. Compile the program and use thesizecommand to predict which segment contributes the most to its size. Verify your prediction. Then, run the program and print the addresses of the variables to confirm they reside in the expected regions (data, BSS, stack). - Create a Stack Overflow: Write a C program with a function that calls itself recursively without a base case (an exit condition). Compile and run it. Observe that it crashes with a segmentation fault. Run the program under the GDB debugger (
gdb ./my_program), typerun, let it crash, and then use thebt(backtrace) command. Observe the massive call stack that indicates the infinite recursion. - Watch the Heap Grow: Write a program that enters a loop. Inside the loop, it should allocate a small chunk of memory (e.g., 1MB) using
malloc(), print the address of the allocated block, and then pause for user input (getchar()). Do not free the memory. Run the program and note the PID. In another terminal, usecat /proc/<PID>/maps | grep heapto view the heap’s size. Each time you press Enter in the first terminal, the program will allocate more memory. Re-run thecatcommand to see the heap’s address range expand. This visually demonstrates how the heap grows and how memory leaks consume system resources.
Summary
- Virtual Memory: Linux provides each process with its own private virtual address space, creating process isolation and simplifying programming. The MMU hardware translates these virtual addresses to physical RAM addresses.
- Kernel vs. User Space: The address space is split. User space is for the application, and is unprivileged. Kernel space is for the OS core, is privileged, and is accessed via system calls.
- Text Segment (.text): Contains the executable code. It is read-only.
- Data Segment (.data): Contains initialized global and static variables.
- BSS Segment (.bss): Contains uninitialized global and static variables. It is zero-filled by the loader at runtime.
- Heap: Provides memory for dynamic allocation (
malloc). It is managed by the programmer and grows upwards. Failure tofreememory causes leaks. - Stack: Manages function calls, local variables, and return addresses. It is managed automatically and grows downwards. Exceeding its size causes a stack overflow.
- Inspection Tools: Utilities like
size,objdump, and the/procfilesystem are essential for analyzing and debugging a program’s memory layout.
Further Reading
- Linux Kernel Documentation – The
/procFilesystem: The official documentation for theprocfilesystem, which provides the/proc/<pid>/mapsinterface. (Accessible viaman 5 procon a Linux system). - System V Application Binary Interface (ABI): The formal specification that defines the layout of executable files and process address spaces on many Unix-like systems, including Linux. A search for “System V ABI” will lead to the latest documents.
- “Understanding The Linux Kernel, 3rd Edition” by Daniel P. Bovet & Marco Cesati: While covering an older kernel version, Chapter 9 (“Process Address Space”) provides an exceptionally detailed and clear explanation of the concepts discussed here.
- “Linux System Programming, 2nd Edition” by Robert Love: A modern and accessible book that covers system calls, memory management, and process interactions in great detail.
- Valgrind Official Documentation: The user manual for the Valgrind tool suite is the best resource for learning how to use it for memory debugging. (https://valgrind.org/docs/manual/index.html)
- LWN.net – “What every programmer should know about memory” by Ulrich Drepper: A comprehensive and deep series of articles covering everything from RAM hardware to OS memory management. It is a challenging but highly rewarding read.
- ARM Developer Documentation: For platform-specific details, the documentation for the ARMv8-A architecture provides the definitive reference on its memory management model and privilege levels. (https://developer.arm.com/architectures/cpu-architecture/a-profile/documentation)
