
Chapter 9: Raspberry Pi 5 Hardware Overview: SoC and Memory
Chapter Objectives
Upon completing this chapter, you will be able to:
- Understand the architecture and components of the Broadcom BCM2712 System-on-Chip (SoC).
- Explain the key features of the Arm Cortex-A76 CPU cores and the VideoCore VII GPU.
- Describe the characteristics and importance of LPDDR4X SDRAM in an embedded system.
- Analyze system hardware information on a running Raspberry Pi 5 using command-line tools and system files.
- Implement simple C and Python programs that query and interact with core hardware components.
- Identify and troubleshoot common issues related to CPU performance, memory management, and thermal throttling.
Introduction
Welcome to the heart of the machine. In previous chapters, we established the foundational concepts of embedded Linux and set up our development environment. Now, we peel back the layers of abstraction to examine the silicon that powers the Raspberry Pi 5. Understanding the hardware, specifically the System-on-Chip (SoC) and its memory subsystem, is not merely an academic exercise. For an embedded systems engineer, this knowledge is paramount. It is the difference between writing code that simply works and engineering a solution that is efficient, powerful, and reliable. The performance of your real-time control system, the fluidity of your graphical user interface, or the speed of your data processing application are all fundamentally constrained by the capabilities of the underlying hardware.

In this chapter, we will embark on a detailed exploration of the Broadcom BCM2712 SoC, the custom-designed brain of the Raspberry Pi 5. We will dissect its major functional units: the powerful quad-core Arm Cortex-A76 processor and the capable VideoCore VII graphics processor. We will also investigate the system’s memory, the LPDDR4X SDRAM, and discuss why its speed and architecture are critical for overall performance. By the end of this chapter, you will not just see the Raspberry Pi 5 as a small computer; you will understand it as an integrated system of specialized components. You will learn how to query the system to reveal its hardware identity and write programs that are aware of the resources they are consuming, setting the stage for advanced topics like performance optimization, power management, and custom hardware interfacing.
Technical Background
The remarkable capability of modern embedded devices like the Raspberry Pi 5 is a testament to the power of integration. Decades ago, the components we are about to discuss—CPU, GPU, memory controllers, and I/O peripherals—would have existed as separate, discrete chips on a large motherboard. The modern approach, known as the System-on-Chip (SoC), combines all this functionality onto a single piece of silicon.
The System-on-Chip (SoC) Philosophy
An SoC is best imagined not as a single processor, but as a bustling city of interconnected, specialized components. The Broadcom BCM2712, a custom 16-nanometer SoC designed specifically for the Raspberry Pi 5, is a prime example. This integration is the cornerstone of the embedded revolution, enabling smaller, more powerful, and more energy-efficient devices. Within this single package resides the central processing unit (CPU), the graphics processing unit (GPU), controllers for memory and peripherals (like USB and Ethernet), and dedicated hardware for video decoding and image processing. These components communicate over an internal high-speed bus, much like a city’s road network. This tight integration minimizes latency—the time it takes for components to communicate—and dramatically reduces the physical footprint and power consumption compared to a system built from discrete chips.
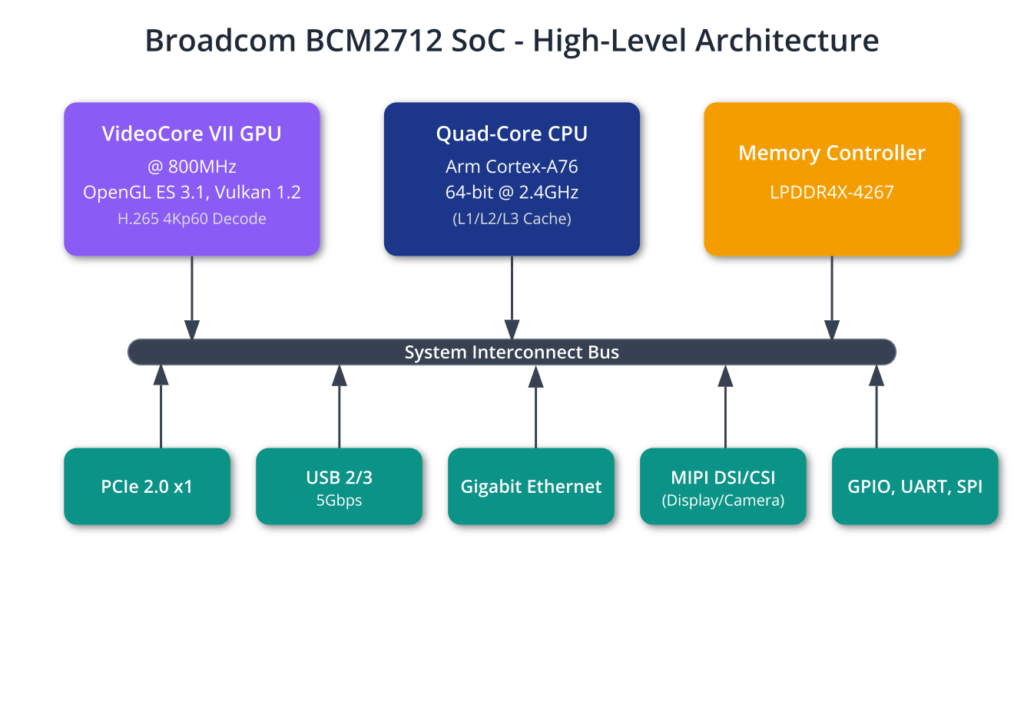
The Brains: Arm Cortex-A76 CPU Cores
At the center of this silicon city are the main thinkers: the Quad-core 64-bit Arm Cortex-A76 CPU cores, clocked at 2.4GHz. The term “quad-core” means there are four independent processing units, allowing the system to execute four separate instruction streams simultaneously. This is the foundation of modern parallel computing. The architecture is the ARMv8.2-A, a 64-bit instruction set architecture (ISA) that defines the fundamental commands the processor can execute. The move to a 64-bit architecture is significant; it allows the CPU to address a much larger memory space (well beyond the 4GB limit of 32-bit systems) and process larger chunks of data in a single operation, which is crucial for data-intensive applications.
Each of these Cortex-A76 cores is a sophisticated superscalar, out-of-order processor. “Superscalar” means it can execute more than one instruction per clock cycle, while “out-of-order” means it can intelligently reorder instructions to keep its internal execution units busy, rather than waiting for slow operations like memory access to complete. This results in a massive improvement in Instructions Per Clock (IPC) compared to the in-order cores used in previous Raspberry Pi models. For the embedded developer, this translates directly to faster application performance, from quicker boot times to more responsive user interfaces and faster algorithm execution. The Cortex-A76 cores also include the Arm Cryptographic Extension (CE). These are special instructions built into the processor that are designed to accelerate encryption and decryption algorithms like AES and SHA. In a world where embedded device security is paramount, hardware-accelerated cryptography is a vital feature.
Feeding the Cores: The Cache Hierarchy

To feed these hungry cores, the BCM2712 employs a sophisticated cache hierarchy. Caching is a crucial concept in computer architecture. Accessing the main system memory (RAM) is relatively slow compared to the speed of the CPU. A cache is a small, extremely fast, and expensive piece of memory located directly on the CPU die. It stores frequently used data and instructions, allowing the CPU to access them almost instantaneously. The BCM2712 provides each Cortex-A76 core with its own private Level 1 (L1) cache (64KB for instructions and 64KB for data) and a larger private Level 2 (L2) cache (512KB). There is also a shared Level 3 (L3) cache (2MB) that is accessible by all four cores. When a core needs data, it checks the L1 cache first. If it’s not there (a “cache miss”), it checks L2, then L3, and only as a last resort does it fetch the data from the much slower main system RAM. An efficient cache system is the secret to unlocking the raw potential of a fast processor.
The Visual Powerhouse: VideoCore VII GPU
While the CPU cores are the general-purpose workhorses, the VideoCore VII GPU is a highly specialized co-processor designed for parallel processing tasks, most notably rendering graphics. The “VII” denotes the seventh generation of Broadcom’s VideoCore architecture. Clocked at 800MHz, its primary role is to drive the dual 4Kp60 HDMI display outputs. It handles tasks like rendering 2D and 3D graphics using the OpenGL ES 3.1 and Vulkan 1.2 standards, which are APIs that software developers use to command the GPU. This offloading is critical; if the CPU had to manually calculate the color of every pixel on a 4K display 60 times per second, it would have no time for anything else.
graph TD
subgraph Application Layer
A[Start: Complex Workload];
end
subgraph Workload Dispatcher
B{Is task highly parallel?};
end
subgraph Processing Units
C["<b>CPU (Cortex-A76)</b><br><i>Optimized for Latency</i><br>Handles sequential tasks, control flow, and complex logic."];
D["<b>GPU (VideoCore VII)</b><br><i>Optimized for Throughput</i><br>Handles massive parallel data processing."];
end
subgraph Task Examples
C_Tasks(
. Running Operating System<br>
- File System Operations<br>
- Application Logic
);
D_Tasks(
. 3D Graphics Rendering<br>
- 4K Video Decoding<br>
- Machine Learning Inference<br>
- Signal Processing
);
end
subgraph Final Output
E[Application Result];
end
A --> B;
B -- No --> C;
B -- Yes --> D;
C --> C_Tasks;
D --> D_Tasks;
C_Tasks --> E;
D_Tasks --> E;
%% Styling
classDef primary fill:#1e3a8a,stroke:#1e3a8a,stroke-width:2px,color:#ffffff;
classDef decision fill:#f59e0b,stroke:#f59e0b,stroke-width:1px,color:#ffffff;
classDef process fill:#0d9488,stroke:#0d9488,stroke-width:1px,color:#ffffff;
classDef system fill:#8b5cf6,stroke:#8b5cf6,stroke-width:1px,color:#ffffff;
classDef success fill:#10b981,stroke:#10b981,stroke-width:2px,color:#ffffff;
classDef tasks fill:#f8fafc,stroke:#64748b,color:#1f2937;
class A primary;
class B decision;
class C process;
class D system;
class C_Tasks,D_Tasks tasks;
class E success;
However, the GPU’s utility extends beyond just putting pretty pictures on a screen. Its architecture, composed of many simple processing units, makes it exceptionally good at General-Purpose GPU (GPGPU) computing. Any problem that can be broken down into many small, independent, parallel calculations—such as machine learning inference, signal processing, or physics simulations—can often be run far more efficiently on a GPU than on a CPU. This is a transformative capability for an embedded device, opening the door to on-device AI and other advanced computational tasks. The VideoCore VII also includes a hardware video decoder that supports H.265 (HEVC) at 4Kp60, again offloading a computationally intensive task from the CPU to ensure smooth video playback while conserving power.
The Lifeblood: LPDDR4X System Memory
All these powerful processing components would be useless without fast access to data. This is the role of the system’s main memory, or RAM (Random Access Memory). The Raspberry Pi 5 uses LPDDR4X SDRAM. Let’s break down this acronym. “LP” stands for Low Power, a critical consideration for embedded and mobile devices. “DDR” stands for Double Data Rate, meaning data is transferred on both the rising and falling edges of the clock signal, effectively doubling the data transfer speed without increasing the clock frequency. “4X” is an evolution of the LPDDR4 standard that achieves even lower power consumption through a reduced I/O voltage. Finally, “SDRAM” stands for Synchronous Dynamic RAM, meaning its operation is synchronized with the system’s clock, and it’s “dynamic” because it must be constantly refreshed to retain its data, unlike “static” RAM (SRAM) used in caches.
The Raspberry Pi 5 is available with either 4GB or 8GB of this memory. This RAM is a shared resource for the entire SoC. The CPU stores the operating system, running applications, and their data there. The GPU uses a portion of it as its framebuffer to compose the image that will be sent to the display. The speed of the LPDDR4X memory, running at 4267 MT/s (MegaTransfers per second), is equally important. This high bandwidth is essential to keep the quad-core Cortex-A76 CPU and the VideoCore VII GPU fed with data. A slow memory bus would create a bottleneck, leaving the powerful processors idle while they wait for data to arrive.
Practical Examples
Theory provides the foundation, but true understanding comes from practice. In this section, we will bridge the gap between the architectural concepts we’ve discussed and the tangible reality of a running embedded Linux system. We will use standard Linux command-line tools and simple programs to probe the hardware, verifying the specifications of the CPU and memory. These exercises are not just about confirming what the datasheet says; they are about learning the fundamental techniques you will use daily as an embedded developer to diagnose issues, monitor performance, and understand the environment in which your code executes.
Tip: All the following commands should be run in a terminal on your Raspberry Pi 5 running Raspberry Pi OS or a similar Linux distribution. You can open a terminal directly on the desktop or connect remotely via SSH.
Probing the CPU with Command-Line Tools
The Linux kernel exposes a vast amount of information about the system’s hardware through a virtual filesystem called /proc. It’s not a real filesystem on the storage device, but a window into the kernel’s data structures. One of the most useful files for a developer is /proc/cpuinfo.
Command Sequence and Explanation:
You can display its contents using the cat or less command.
less /proc/cpuinfo
Expected Output (Abbreviated):
You will see a block of text repeated for each CPU core. Since the BCM2712 has four cores, you will see entries for processor : 0 through processor : 3.
processor : 0
BogoMIPS : 108.00
Features : fp asimd evtstrm crc32 cpuid
CPU implementer : 0x41
CPU architecture: 8
CPU variant : 0x0
CPU part : 0xd08
CPU revision : 3
processor : 1
...
processor : 2
...
processor : 3
...
Hardware : BCM2712
Revision : d04170
Serial : 10000000deadbeef
Model : Raspberry Pi 5 Model B Rev 1.0
Analysis:
- processor: This is the logical CPU core number, indexed from 0.
- CPU part:
0xd08is the primary part number for the Arm Cortex-A76. This confirms the core’s architecture. - Features: This lists supported CPU features.
asimdrefers to the Advanced SIMD architecture (NEON), which provides hardware acceleration for vector operations.crc32indicates hardware support for CRC calculations. - Hardware: This explicitly identifies the SoC as
BCM2712. - Model: This confirms you are running on a Raspberry Pi 5.
Another powerful tool is lscpu, which parses information from /proc/cpuinfo and presents it in a more readable format.
lscpu
Expected Output (Abbreviated):
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Vendor ID: ARM
Model name: Cortex-A76
Model: 1
Thread(s) per core: 1
Core(s) per cluster: 4
Socket(s): -
Cluster(s): 1
Stepping: r4p1
CPU(s) scaling MHz: 62%
CPU max MHz: 2400.0000
CPU min MHz: 1500.0000
BogoMIPS: 108.00
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fph
p asimdhp cpuid asimdrdm lrcpc dcpop asimddp
Caches (sum of all):
L1d: 256 KiB (4 instances)
L1i: 256 KiB (4 instances)
L2: 2 MiB (4 instances)
L3: 2 MiB (1 instance)
NUMA:
NUMA node(s): 1
NUMA node0 CPU(s): 0-3
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: Not affected
L1tf: Not affected
Mds: Not affected
Meltdown: Not affected
Mmio stale data: Not affected
Reg file data sampling: Not affected
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prct
l
Spectre v1: Mitigation; __user pointer sanitization
Spectre v2: Mitigation; CSV2, BHB
Srbds: Not affected
Tsx async abort: Not affected
Analysis:
- Architecture:
aarch64is the official name for the 64-bit Arm architecture. - CPU(s): 4: Confirms the quad-core configuration.
- Model name: Cortex-A76: Explicitly identifies the CPU core type.
- CPU max MHz: Shows the maximum clock speed of 2.4GHz.
- Cache Information: This section clearly lays out the cache hierarchy we discussed. It shows the total size of each cache level and correctly notes that the L1 and L2 caches are per-core instances, while the L3 cache is a single shared instance.
Checking System Memory
Similarly, the /proc filesystem provides a detailed view of memory usage in the /proc/meminfo file.
Command Sequence and Explanation:
less /proc/meminfo
Expected Output (for a 4GB Model):
MemTotal: 4137520 kB
MemFree: 2959056 kB
MemAvailable: 3562816 kB
Buffers: 31568 kB
Cached: 681328 kB
SwapCached: 0 kB
Active: 638224 kB
Inactive: 352928 kB
Active(anon): 356896 kB
Inactive(anon): 0 kB
Active(file): 281328 kB
Inactive(file): 352928 kB
Unevictable: 25680 kB
Mlocked: 16 kB
SwapTotal: 524272 kB
SwapFree: 524272 kB
Zswap: 0 kB
Zswapped: 0 kB
Dirty: 96 kB
Writeback: 0 kB
AnonPages: 304032 kB
Mapped: 200000 kB
Shmem: 78640 kB
KReclaimable: 30336 kB
Slab: 65584 kB
SReclaimable: 30336 kB
SUnreclaim: 35248 kB
KernelStack: 4720 kB
PageTables: 10240 kB
SecPageTables: 0 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 2593024 kB
Committed_AS: 1682480 kB
VmallocTotal: 68447887360 kB
VmallocUsed: 19072 kB
VmallocChunk: 0 kB
Percpu: 1344 kB
CmaTotal: 65536 kB
CmaFree: 49056 kB
Analysis:
- MemTotal: The total amount of usable RAM in the system. Note that this is slightly less than the advertised 8GB (which is 8,388,608 kB) because a portion is reserved by the kernel and the GPU.
- MemFree: The amount of memory that is currently completely unused.
- MemAvailable: This is often a more useful metric. It’s an estimate of how much memory is available for starting new applications without swapping. It includes
MemFreeplus memory currently used for reclaimable caches (BuffersandCached). In a healthy Linux system, it’s normal forMemFreeto be low, as the kernel uses free RAM for disk caching to speed up file access.MemAvailabletells you the true “free” memory.
The free command provides a more human-friendly summary of this information.
free -h
The -h flag stands for “human-readable,” displaying the values in units like KiB, MiB, and GiB.
Expected Output (for an 4GB Model):
total used free shared buff/cache available
Mem: 3.9Gi 565Mi 2.8Gi 76Mi 725Mi 3.4Gi
Swap: 511Mi 0B 511Mi
This table presents the most important metrics from /proc/meminfo in a compact format, confirming the total memory and its current utilization.
Programmatic Hardware Inspection with C
While command-line tools are useful for interactive sessions, your applications may need to query hardware resources programmatically. Here is a simple C program that determines the number of available CPU cores. This is a common requirement for multi-threaded applications that want to scale their workload to the available hardware.
Code Snippet: get_cpu_cores.c
#include <stdio.h>
#include <unistd.h> // For sysconf
/*
* This program demonstrates how to programmatically determine the
* number of available CPU cores on a Linux system.
*
* It uses the sysconf() function, which is part of the POSIX standard,
* to query system configuration variables at runtime.
*/
int main() {
long num_cores;
// _SC_NPROCESSORS_ONLN is the POSIX variable for the number of
// online processors (cores).
num_cores = sysconf(_SC_NPROCESSORS_ONLN);
if (num_cores < 1) {
// Handle potential error from sysconf()
fprintf(stderr, "Could not determine the number of CPU cores.\n");
return 1;
}
printf("This system has %ld CPU core(s) online.\n", num_cores);
// An application could now use this value to, for example,
// create an optimal number of worker threads.
printf("This would be a good number of threads for a thread pool.\n");
return 0;
}
Build and Run Steps:
- Save the code as
get_cpu_cores.c. - Compile it using GCC:
gcc get_cpu_cores.c -o get_cpu_cores - Execute the compiled program:
./get_cpu_cores
Expected Output:
This system has 4 CPU core(s) online.
This would be a good number of threads for a thread pool.
This simple example demonstrates a robust, portable method for making your C applications hardware-aware.
Hardware Integration: Reading the Device Tree
The Device Tree is a data structure for describing hardware. In the context of embedded Linux, it’s a way to tell the Linux kernel what hardware components are on the board and how they are connected, without having to hard-code that information into the kernel source. The Raspberry Pi 5 uses a device tree to configure its peripherals.
We can inspect the compiled device tree that the kernel is using, which is also exposed through the /proc filesystem.
File Structure Example:
The source files for the device tree are text files (.dts), which are compiled into a binary blob (.dtb). The running system exposes this information in a human-readable format under /proc/device-tree. Let’s look at the entry for the SoC itself.
ls -l /proc/device-tree/
This will list the top-level nodes of the device tree. You can explore it like a regular directory.
Command Sequence and Explanation:
Let’s find the compatible property for the root node, which identifies the main board and SoC.
cat /proc/device-tree/compatible
Expected Output:
The output will be a series of null-terminated strings. You can use tr to make it more readable.
cat /proc/device-tree/compatible | tr '\0' '\n'
raspberrypi,5-model-b
brcm,bcm2712
Analysis:
This confirms, from the kernel’s own hardware description, that it is running on a Raspberry Pi 5 Model B, which uses the BCM2712 SoC. This is the mechanism the kernel uses to load the correct drivers and configure the system. For example, a driver for a specific audio codec might check for a compatible string in the device tree to know if its target hardware is present before it attempts to initialize. As an embedded developer, you will frequently interact with the device tree when adding new hardware, like sensors or displays, to the system.
Common Mistakes & Troubleshooting
Navigating the intricacies of embedded hardware can be challenging. Newcomers often encounter a set of common pitfalls related to the CPU and memory. Understanding these issues proactively can save hours of frustrating debugging.
graph TD
subgraph System State
A[Start: CPU Under Load];
B{Temp > 85°C?};
C[Maintain Max Frequency<br>e.g., 2.4GHz];
D[Initiate Throttling];
E[Reduce CPU Clock Speed];
F{Temp < Safe Threshold?};
G[Restore Max Frequency];
end
subgraph Monitoring
M1(vcgencmd measure_temp);
M2(vcgencmd measure_clock arm);
end
A --> B;
B -- No --> C;
C --> A;
B -- Yes --> D;
D --> E;
E --> F;
F -- No --> E;
F -- Yes --> G;
G --> A;
A -.-> M1;
A -.-> M2;
E -.-> M1;
E -.-> M2;
%% Styling
classDef primary fill:#1e3a8a,stroke:#1e3a8a,stroke-width:2px,color:#ffffff;
classDef decision fill:#f59e0b,stroke:#f59e0b,stroke-width:1px,color:#ffffff;
classDef process fill:#0d9488,stroke:#0d9488,stroke-width:1px,color:#ffffff;
classDef check fill:#ef4444,stroke:#ef4444,stroke-width:1px,color:#ffffff;
classDef success fill:#10b981,stroke:#10b981,stroke-width:2px,color:#ffffff;
classDef monitor fill:#64748b,stroke:#334155,stroke-width:1px,color:#ffffff,stroke-dasharray: 5 5;
class A,G primary;
class B,F decision;
class C,E process;
class D check;
class M1,M2 monitor;
Exercises
These exercises are designed to reinforce the concepts presented in this chapter. They encourage you to actively explore the hardware and observe its behavior under different conditions.
- CPU Load and Temperature Monitoring Script:
- Objective: Write a shell script that continuously monitors and logs the CPU’s temperature and current operating frequency. This will help you visualize the relationship between load and thermal management.
- Guidance:
- Create a file named
monitor_cpu.sh. - Use a
whileloop to run the commands indefinitely (while true; do ... done). - Inside the loop, use
vcgencmd measure_tempto get the temperature andvcgencmd measure_clock armto get the ARM core frequency. - Use
echoto print the timestamp (using thedatecommand) along with the temperature and frequency. - Use the
sleepcommand (e.g.,sleep 2) at the end of the loop to control the update interval. - Run a CPU-intensive task in another terminal (like
stress -c 4) and observe how the frequency and temperature change in your script’s output.
- Create a file named
- Verification: Your script should print a new line of data every few seconds. When you run the
stresscommand, you should see the temperature rise and the frequency stay at its maximum (around 2400MHz), assuming you have adequate cooling.
- Exploring Cache Hierarchy with
lscpu:- Objective: Use the
lscpucommand with advanced options to get a detailed map of the CPU cache architecture. - Guidance:
- Run
lscpu --helpto see its available options. - Execute
lscpu --extendedorlscpu -e. This provides a detailed view showing which caches are associated with which specific CPU cores. - Execute
lscpu --cachesorlscpu -C. This provides a summary of the cache sizes, types, and the cores they are shared by.
- Run
- Verification: Compare the output of these commands with the cache architecture described in the “Technical Background” section. You should be able to identify the L1d (data), L1i (instruction), L2, and L3 caches and see how they are mapped to the four Cortex-A76 cores (CPU0-CPU3).
- Objective: Use the
- Memory Allocation in C:
- Objective: Write a C program that attempts to allocate a large amount of memory and observe the system’s response.
- Guidance:
- Write a C program that uses a loop and the
malloc()function to allocate memory in large chunks (e.g., 100MB at a time). - Inside the loop, after each successful allocation, print a message indicating the total memory allocated so far.
- Use the
free()function in a corresponding loop to release the memory before the program exits. - In another terminal, run
free -hrepeatedly while your C program is running.
- Write a C program that uses a loop and the
- Verification: Observe how the “used” and “available” memory reported by
free -hchanges as your program runs. See how large an allocation you can make beforemalloc()returnsNULL, indicating the system is out of memory. This provides a practical feel for the memory limits of your device.
- Device Tree Investigation:
- Objective: Use the
/proc/device-treefilesystem to find the configured clock frequency for the main UART (serial port). - Guidance:
- The primary serial port on the Raspberry Pi is typically
uart0. The device tree nodes for peripherals are often found under thesocnode. - Navigate the
/proc/device-tree/soc/directory. You will likely find a node related to the serial port (it might have “serial” or “uart” in its name). - Once you find the correct node, look for a property named
clock-frequency. - Use
catto display its value. Note that it might be a 32-bit integer stored in big-endian format. Thehexdumpcommand can be useful for inspecting binary data (hexdump -C your_file).
- The primary serial port on the Raspberry Pi is typically
- Verification: This is an exploratory exercise. The goal is to successfully navigate the device tree and find hardware parameters. Finding the property and attempting to interpret its value demonstrates a key skill for custom hardware integration.
- Objective: Use the
sequenceDiagram
participant PowerOn as Power On
participant BootROM as Boot ROM (SoC)
participant Bootloader as Bootloader (U-Boot)
participant Kernel as Linux Kernel
participant Init as User Space (init/systemd)
PowerOn->>BootROM: System is powered on
activate BootROM
BootROM-->>Bootloader: Load bootloader from<br>storage (SD/eMMC)
deactivate BootROM
activate Bootloader
Bootloader->>Bootloader: Initialize DRAM,<br>configure hardware
Bootloader->>Kernel: Load kernel image &<br>Device Tree Blob (DTB) into RAM
deactivate Bootloader
activate Kernel
Kernel->>Kernel: Decompress, initialize subsystems<br>(drivers, memory mgmt)
Kernel->>Kernel: Mount root filesystem (readonly)
Kernel->>Init: Execute /sbin/init (PID 1)
deactivate Kernel
activate Init
Init->>Init: Mount filesystems (read/write)
Init->>Init: Start system services<br>(networking, sshd, etc.)
Init-->>PowerOn: System Ready for Login
Summary
This chapter provided a deep dive into the core hardware components of the Raspberry Pi 5. We have moved from a high-level view of an embedded board to a detailed understanding of the silicon that powers it.
- System-on-Chip (SoC): The Raspberry Pi 5 is powered by the Broadcom BCM2712 SoC, which integrates the CPU, GPU, memory controller, and I/O peripherals onto a single chip for efficiency and performance.
- CPU Architecture: The SoC features a Quad-core 64-bit Arm Cortex-A76 processor complex running at 2.4GHz. This out-of-order architecture provides a significant performance uplift over previous models.
- Cache Hierarchy: A multi-level cache system (private L1/L2 caches per core and a shared L3 cache) is crucial for keeping the powerful CPU cores supplied with data and minimizing latency.
- GPU Capabilities: The VideoCore VII GPU handles graphics rendering for the dual 4Kp60 display outputs and can be used for general-purpose parallel computing (GPGPU), enabling on-device AI and computational workloads.
- Memory Subsystem: The system uses high-bandwidth, low-power LPDDR4X SDRAM, which is a shared resource critical for both CPU and GPU performance.
- Hardware Inspection: We learned to use standard Linux tools like
lscpu,free, and the/procfilesystem (/proc/cpuinfo,/proc/meminfo,/proc/device-tree) to inspect and verify hardware specifications from the command line. - Practical Application: Understanding the hardware is essential for writing efficient code, diagnosing performance issues like thermal throttling, managing memory effectively, and interfacing with custom hardware via the Device Tree.
With this foundational knowledge of the Raspberry Pi 5’s hardware, you are now better equipped to write software that makes full use of its capabilities. In the following chapters, we will build upon this by exploring how to interact with the GPIO pins and connect a new world of external sensors and actuators.
Further Reading
- Raspberry Pi 5 Product Brief: Raspberry Pi Foundation. (Provides a high-level overview and key specifications).
- BCM2712 Datasheet (Peripheral Specification): Broadcom / Raspberry Pi Foundation. (The definitive guide to the peripherals, registers, and memory maps).
- Arm Cortex-A76 Technical Reference Manual: Arm Holdings. (Detailed architectural information about the CPU core).
- Device Tree for Dummies: Thomas Petazzoni, Bootlin. (A classic, highly-regarded presentation that clearly explains the concepts behind the Device Tree).
- Vulkan and OpenGL ES Documentation: Khronos Group. (Official specifications for the graphics APIs supported by the VideoCore VII).
- Linux Kernel Documentation – The /proc filesystem:
- Available at
docs.kernel.org.
- Available at
