
Chapter 5: Ethics and Responsible AI Development
Chapter Objectives
Upon completing this chapter, students will be able to:
- Understand the fundamental ethical principles in AI, including fairness, accountability, and transparency (FAT).
- Analyze the sources of bias in AI systems, from data collection to model deployment, and their societal impact.
- Implement technical and procedural frameworks for developing responsible AI within an organizational context.
- Design AI systems with ethical considerations integrated throughout the development lifecycle, from initial concept to post-deployment monitoring.
- Assess the ethical risks and potential harms of AI applications in various business domains using structured evaluation methods.
- Deploy strategies for effective stakeholder communication, change management, and governance to foster a culture of responsible AI.
Introduction
In the rapidly advancing field of artificial intelligence, the pursuit of technical capability—creating models that are more accurate, faster, and more powerful—has often overshadowed a more fundamental question: what is the impact of these systems on individuals and society? As AI moves from research labs into the core of our global infrastructure, powering everything from financial lending and medical diagnostics to criminal justice and autonomous transportation, its ethical dimension is no longer a peripheral concern but a central engineering challenge. The development of AI is not merely a technical exercise; it is a socio-technical one, laden with profound responsibilities.
This chapter confronts this challenge directly, positioning ethical considerations as an indispensable component of modern AI engineering. We will explore how well-intentioned systems can perpetuate and even amplify historical biases, leading to discriminatory outcomes that undermine fairness and equality. We will investigate the “black box” problem, where the opacity of complex models erodes trust and complicates accountability. This exploration is not an abstract philosophical debate but a practical necessity for any organization seeking to deploy AI sustainably and successfully. In an era of increasing regulatory scrutiny (e.g., the EU AI Act) and heightened public awareness, a failure to address AI ethics is not just a moral lapse—it is a significant business, legal, and reputational risk.
This chapter provides a comprehensive introduction to the principles and practices of Responsible AI. We will move beyond theory to provide actionable frameworks, technical methodologies, and strategic guidance for building AI systems that are not only intelligent but also fair, transparent, and accountable. You will learn to identify, measure, and mitigate bias, design for transparency, and establish governance structures that ensure human values remain at the heart of technological progress. For the modern AI engineer, mastering these concepts is as critical as understanding neural network architectures or optimization algorithms; it is the key to building technology that is trusted, adopted, and ultimately, beneficial to humanity.
Technical Background
The foundation of responsible AI development rests on a deep understanding of the ethical challenges inherent in the technology. These are not abstract problems but technical issues with identifiable sources and, increasingly, with technical and procedural solutions. This section delves into the core principles of fairness, accountability, and transparency, exploring their theoretical underpinnings, historical context, and the technical mechanisms through which they manifest in AI systems.
The Triad of Responsible AI: Fairness, Accountability, and Transparency (FAT)
The discourse around AI ethics is often anchored by three interconnected concepts: Fairness, Accountability, and Transparency. Known collectively as FAT, this triad provides a robust framework for analyzing and mitigating the ethical risks of AI systems. While they are distinct, they are deeply codependent; a lack of transparency can make it impossible to assess fairness or assign accountability.
Fairness in AI is perhaps the most complex and contested of the three principles. At its core, it is concerned with ensuring that an AI system’s outcomes do not create or reinforce unjust, prejudiced, or discriminatory results against individuals or groups, particularly those from historically marginalized populations. The challenge, however, lies in defining “fairness” itself. What seems fair in one context may be unjust in another. Computer science has attempted to formalize this through various mathematical definitions. For example, group fairness seeks to ensure that different demographic groups (e.g., defined by race, gender) receive similar outcomes on average. This can be measured through metrics like demographic parity, which requires the probability of a positive outcome to be the same for all groups, or equal opportunity, which requires the true positive rate to be equal across groups. In contrast, individual fairness posits that similar individuals should be treated similarly. The technical implementation of these metrics often reveals a fundamental tension: it is mathematically impossible to satisfy all fairness metrics simultaneously, a concept known as the “impossibility theorem of fairness.” This forces engineering teams to make explicit, value-laden decisions about which type of fairness to prioritize based on the specific application and its societal context.
Technical Definitions of Fairness Metrics
| Fairness Metric | Core Question | Technical Definition | Limitation / Trade-off |
|---|---|---|---|
| Demographic Parity | Are all groups receiving positive outcomes at the same rate? | The likelihood of a positive outcome P(Ŷ=1) is the same regardless of group membership (A). P(Ŷ=1 | A=0) = P(Ŷ=1 | A=1) |
Can lead to penalizing qualified candidates from a high-performing group to achieve parity. Ignores whether individuals actually deserved the outcome. |
| Equal Opportunity | Among people who qualify for a positive outcome, do all groups have an equal chance of receiving it? | The True Positive Rate (TPR) is the same across groups. P(Ŷ=1 | Y=1, A=0) = P(Ŷ=1 | Y=1, A=1) |
Only considers fairness for the advantaged group (those who qualify, Y=1). Says nothing about fairness for those who don’t qualify. |
| Equalized Odds | Do all groups have an equal True Positive Rate AND an equal False Positive Rate? | Satisfies Equal Opportunity and also requires the False Positive Rate (FPR) to be equal across groups. P(Ŷ=1 | Y=0, A=0) = P(Ŷ=1 | Y=0, A=1) |
Very strict criterion. Often impossible to satisfy without harming model accuracy. Can reduce the overall number of positive outcomes. |
| Individual Fairness | Are similar individuals treated similarly? | For any two individuals xᵢ and xⱼ that are similar (according to a task-specific metric), the model’s outputs should also be similar. d(M(xᵢ), M(xⱼ)) ≤ d(xᵢ, xⱼ) |
Extremely difficult to define a meaningful “similarity” metric. Computationally expensive to enforce for all pairs of individuals. |
Accountability addresses the question of “who is responsible when an AI system fails?” It is about establishing clear lines of responsibility for the outcomes of an AI system throughout its lifecycle. This extends beyond the data scientists who built the model to include the data providers, the business leaders who defined its objectives, the engineers who deployed it, and the operators who manage it in production. True accountability requires robust governance structures, clear documentation of decisions, and mechanisms for redress when individuals are harmed by an AI-driven decision. It necessitates a shift from a purely technical view of system failure (e.g., low accuracy) to a socio-technical one that considers the human impact. For instance, if a loan application is unfairly denied by an AI, an accountability framework would define the process for the applicant to appeal the decision, have it reviewed by a human, and receive a clear explanation—a concept often referred to as the “right to an explanation.”
Transparency, often intertwined with explainability and interpretability, is the principle that the inner workings of an AI system should be understandable to the extent necessary to hold it accountable and assess its fairness. A highly interpretable model is one whose mechanics are simple enough for a human to comprehend without additional tools (e.g., a linear regression model or a small decision tree). Most modern AI systems, particularly deep neural networks, are not inherently interpretable. This has given rise to the field of Explainable AI (XAI), which focuses on developing techniques to generate post-hoc explanations for the decisions of these “black box” models. Techniques like LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations) work by approximating the complex model’s behavior around a specific prediction with a simpler, interpretable model.

These tools can produce feature-importance charts or highlight which parts of an input (e.g., pixels in an image, words in a text) were most influential in a decision. Transparency is not just for developers; it’s crucial for regulators who need to audit systems, for business users who need to trust them, and for the end-users who are affected by their decisions.
graph TD
subgraph Responsible AI Framework
direction LR
A[<b>Fairness</b><br><i>Ensuring equitable outcomes<br>and mitigating bias.</i>]
B[<b>Accountability</b><br><i>Establishing responsibility<br>for AI system outcomes.</i>]
C[<b>Transparency</b><br><i>Making AI systems<br>understandable and explainable.</i>]
end
A -- "Requires understanding of model decisions to assess" --> C
C -- "Enables the auditing needed for" --> A
B -- "Depends on clear understanding of system to assign" --> C
C -- "Is necessary to know who is responsible" --> B
A -- "Cannot be enforced without clear lines of" --> B
B -- "Includes responsibility for ensuring" --> A
style A fill:#9b59b6,stroke:#9b59b6,stroke-width:2px,color:#ebf5ee
style B fill:#283044,stroke:#283044,stroke-width:2px,color:#ebf5ee
style C fill:#78a1bb,stroke:#78a1bb,stroke-width:2px,color:#283044
Unpacking Bias: Sources and Consequences
Bias in AI is not a monolithic problem; it is a multifaceted issue that can be introduced at any stage of the machine learning lifecycle. Understanding these sources is the first step toward mitigation. The consequences of unchecked bias can be severe, ranging from reputational damage and regulatory fines to profound societal harm.
Data-Driven Bias: The World as It Is, Not as It Should Be
The most common source of bias is the data used to train the model. AI systems learn patterns from historical data, and if this data reflects existing societal biases, the model will learn and codify them. This is often referred to as representation bias or sampling bias. For example, if a facial recognition system is trained predominantly on images of light-skinned individuals, its performance on dark-skinned individuals will be significantly worse. This is not a malicious act but a statistical one; the model optimizes for accuracy on the majority class in its training data. Similarly, historical bias occurs when the data itself is factually accurate but reflects a prejudiced world. A model trained on historical hiring data from a company that predominantly hired men for engineering roles will learn that being male is a strong predictor of being a successful engineering hire, even if gender is explicitly excluded as a feature. The model will pick up on proxy variables (e.g., attendance at certain universities, participation in certain hobbies) that correlate with gender, perpetuating the historical inequality.
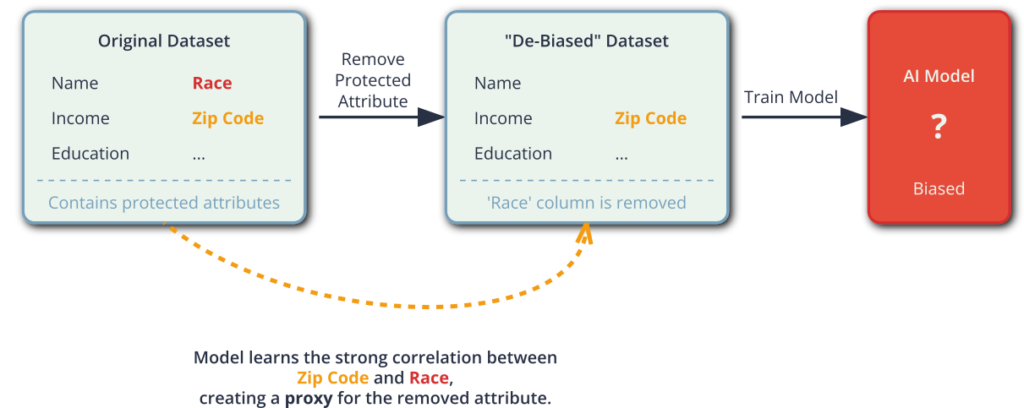
Warning: Simply removing protected attributes like race or gender from a dataset is not sufficient to prevent bias. Models are adept at finding proxy variables—other features that are highly correlated with the protected attribute—and using them to make discriminatory predictions.
Algorithmic and Model-Induced Bias
Bias can also be introduced or amplified by the algorithms and modeling choices themselves. Algorithmic bias arises when an algorithm is designed in a way that inherently favors certain outcomes. For example, an optimization algorithm for a ride-sharing service might prioritize efficiency by routing drivers away from low-income neighborhoods if historical data shows that trips originating there are less profitable. While the goal is profit maximization, the outcome is a discriminatory reduction in service for a specific community. Furthermore, the very process of model development involves choices that can introduce bias. The selection of a model architecture, the choice of a loss function to optimize, and the regularization techniques used can all have differential impacts on a model’s performance across different subgroups. For instance, a model optimized for overall accuracy might achieve that goal by performing exceptionally well on the majority group while failing catastrophically on a minority group.
Human-in-the-Loop Bias
The final, and perhaps most insidious, source of bias comes from human interaction with the AI system. Evaluation bias occurs when the benchmarks used to assess a model’s performance are themselves biased. If a test dataset for a skin cancer detection model underrepresents lesions on darker skin tones, the model’s reported high accuracy will be misleading and create a false sense of security. Confirmation bias can occur when human operators of an AI system selectively trust its outputs when they align with their pre-existing beliefs and scrutinize or dismiss them when they do not. For example, a loan officer might quickly approve an AI-recommended loan for an applicant who fits their traditional idea of a good candidate but spend significant time looking for reasons to deny an AI-recommended loan for an unconventional applicant. This feedback loop can further poison the data used for future model retraining, creating a vicious cycle where the AI and human biases reinforce each other.
graph TD
subgraph AI Development Lifecycle
direction TB
DataCollection["<b>Data Collection &<br>Preparation</b>"]
ModelDev["<b>Model Development &<br>Training</b>"]
Evaluation["<b>Evaluation &<br>Validation</b>"]
Deployment["<b>Deployment &<br>Monitoring</b>"]
end
subgraph Bias Injection Points
direction TB
Bias1["<b>Representation Bias</b><br>(e.g., skewed samples)<br><b>Historical Bias</b><br>(e.g., reflecting past prejudice)"]
Bias2["<b>Algorithmic Bias</b><br>(e.g., optimization choices)<br><b>Model-Induced Bias</b><br>(e.g., choice of architecture)"]
Bias3["<b>Evaluation Bias</b><br>(e.g., flawed benchmarks)"]
Bias4["<b>Confirmation Bias</b><br>(e.g., user interpretation)<br><b>Feedback Loop Bias</b><br>(e.g., biased interactions retrain model)"]
end
DataCollection --> ModelDev --> Evaluation --> Deployment
DataCollection -- Introduces --> Bias1
ModelDev -- Introduces --> Bias2
Evaluation -- Introduces --> Bias3
Deployment -- Introduces & Amplifies --> Bias4
style DataCollection fill:#9b59b6,stroke:#9b59b6,stroke-width:2px,color:#ebf5ee
style ModelDev fill:#e74c3c,stroke:#e74c3c,stroke-width:2px,color:#ebf5ee
style Evaluation fill:#f39c12,stroke:#f39c12,stroke-width:2px,color:#283044
style Deployment fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee
style Bias1 fill:#f1c40f,stroke:#f1c40f,stroke-width:1px,color:#283044
style Bias2 fill:#f1c40f,stroke:#f1c40f,stroke-width:1px,color:#283044
style Bias3 fill:#f1c40f,stroke:#f1c40f,stroke-width:1px,color:#283044
style Bias4 fill:#f1c40f,stroke:#f1c40f,stroke-width:1px,color:#283044
Strategic Framework and Implementation
Moving from understanding ethical principles to implementing them requires a structured, organization-wide strategy. Responsible AI cannot be an afterthought or the sole responsibility of a single team; it must be woven into the fabric of the organization’s culture, processes, and governance. This section provides a strategic framework for operationalizing AI ethics, ensuring that development aligns with business objectives and societal values.
A Framework for Responsible AI Governance
A successful Responsible AI program requires a deliberate governance framework that establishes clear policies, roles, and processes. This framework serves as the operational backbone for translating ethical principles into consistent practice.
1. Establish an AI Ethics Committee or Review Board
The first step is to formalize oversight. An AI Ethics Committee or a similar cross-functional body should be established, comprising representatives from legal, compliance, engineering, product management, and business leadership. This committee is not meant to be a bottleneck but a center of excellence. Its mandate should include:
- Developing and maintaining the organization’s AI ethics principles and policies. These should be clear, concise, and aligned with both company values and emerging regulations.
- Reviewing high-risk AI projects. Using a risk-based assessment (see below), the committee should provide guidance and require mitigation plans for projects that could have a significant negative impact on individuals or society.
- Providing training and resources to development teams on ethical design, bias detection, and responsible implementation.
- Acting as an escalation point for ethical dilemmas that cannot be resolved at the team level.
2. Implement a Risk-Based Assessment Process
Not all AI systems carry the same level of ethical risk. A model that optimizes a manufacturing process has a different risk profile than one that assists in criminal sentencing. A Risk-Based Assessment or Ethical Impact Assessment should be a mandatory gate in the project lifecycle for any new AI initiative. This process involves:
- Scoping the Application: Clearly defining the intended use case, the target population, and the decisions the AI will influence.
- Identifying Potential Harms: Brainstorming the potential negative impacts across various domains, such as fairness (e.g., discriminatory outcomes), privacy (e.g., data misuse), safety (e.g., physical harm from autonomous systems), and societal impact (e.g., job displacement).
- Quantifying Risk: Assessing the likelihood and severity of these harms. This helps prioritize which risks require the most urgent attention. A simple matrix of “low,” “medium,” and “high” risk can be used. High-risk applications, such as those involving sensitive personal data or affecting fundamental rights, should automatically trigger a full review by the Ethics Committee.
- Developing a Mitigation Plan: For each identified risk, the project team must propose concrete mitigation strategies. This is not a “pass/fail” test but a collaborative process to make the system safer and more responsible before development begins.
3. Integrate Ethics into the MLOps Lifecycle
Ethical considerations must be embedded into the standard Machine Learning Operations (MLOps) workflow. This means augmenting existing processes with new tools and checkpoints.
- Data Governance: Implement strict protocols for data provenance, quality, and suitability. Every dataset should have a “datasheet” that documents its origin, collection methodology, known limitations, and potential biases.
- Bias & Fairness Audits: Before model training, conduct exploratory data analysis to detect statistical biases. After training, use fairness toolkits (e.g., IBM’s AI Fairness 360, Google’s What-If Tool) to measure the model’s performance across different demographic subgroups. These audits should be a mandatory part of the code review and pre-deployment checklist.
- Transparency & Explainability Reports: For high-risk models, generate and store explainability reports (e.g., SHAP value summaries) for each prediction or on a representative sample. These reports are crucial for debugging, auditing, and fulfilling “right to an explanation” requests.
- Post-Deployment Monitoring: Ethical risks do not end at deployment. Continuously monitor the model’s live performance for drift in both accuracy and fairness metrics. Set up automated alerts to flag when the model’s behavior deviates significantly from its pre-deployment benchmarks, which could indicate that it is encountering a new population or that its performance is degrading for a particular subgroup.
graph TD
subgraph "MLOps Pipeline with Responsible AI Governance"
A[Start: Project Inception] --> B{Ethical Risk<br>Assessment};
B -- High Risk --> C[Ethics Committee Review];
B -- Low/Medium Risk --> D[Data Ingestion & Versioning];
C --> D;
D --> E["Data Quality &<br>Datasheet Review"];
style E fill:#f39c12,stroke:#f39c12,stroke-width:1px,color:#283044
E --> F[Feature Engineering];
F --> G["<b>Bias Audit (Pre-Training)</b><br><i>Check for representation<br>& historical bias</i>"];
style G fill:#f1c40f,stroke:#f1c40f,stroke-width:1px,color:#283044
G --> H[Model Training];
H --> I["<b>Fairness & Explainability<br>Analysis (Post-Training)</b><br><i>Generate Model Card, SHAP/LIME reports</i>"];
style I fill:#f1c40f,stroke:#f1c40f,stroke-width:1px,color:#283044
I --> J[Model Validation & Testing];
J --> K{Deployment Gate<br>Final Review};
K -- Approved --> L[Model Deployment];
L --> M["<b>Post-Deployment Monitoring</b><br><i>Track accuracy AND fairness drift</i>"];
style M fill:#f1c40f,stroke:#f1c40f,stroke-width:1px,color:#283044
M --> N{Alert: Performance<br>or Fairness Degradation};
N -- Trigger --> O[Retrain/Review Cycle];
O --> H;
M --> P[End: Healthy Model in Production];
end
classDef default fill:#78a1bb,stroke:#283044,stroke-width:1px,color:#283044
classDef startNode fill:#283044,stroke:#283044,stroke-width:2px,color:#ebf5ee
classDef endNode fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee
classDef decisionNode fill:#f39c12,stroke:#f39c12,stroke-width:1px,color:#283044
classDef dataNode fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee
classDef modelNode fill:#e74c3c,stroke:#e74c3c,stroke-width:1px,color:#ebf5ee
classDef warningNode fill:#f1c40f,stroke:#f1c40f,stroke-width:1px,color:#283044
class A startNode;
class D,E,F dataNode;
class G,I,M warningNode;
class H,J,L modelNode;
class B,K,N decisionNode;
class P endNode;
Case Study Analysis: A Tale of Two AI Implementations
To understand the practical importance of this framework, consider two hypothetical companies implementing an AI system to screen job applicants.
Case Study 1: “MoveFast Inc.” – The Technology-First Approach
- Scenario: MoveFast Inc. wants to automate the initial screening of tens of thousands of resumes for software engineering roles to save time for its recruiters. The engineering team is tasked with building a model that predicts which candidates are most likely to receive a job offer based on 20 years of the company’s hiring data.
- Implementation: The team focuses purely on predictive accuracy. They use the historical data as-is, train a complex deep learning model, and achieve 95% accuracy in predicting past hiring decisions. They do not explicitly test for bias, assuming that because “race” and “gender” are not in the dataset, the model will be fair. The system is deployed quickly.
- Outcome: Initially, the system is hailed as a success, dramatically reducing recruiter workload. However, an investigative journalist finds that the system disproportionately rejects female candidates. The analysis reveals that the model learned to penalize resumes that mentioned “women’s chess club” or attendance at all-female colleges, as these were proxies for gender that correlated with lower hiring rates in the biased historical data. The company faces a major public relations crisis, regulatory investigation, and a class-action lawsuit. The project is scrapped, and trust in the company’s AI initiatives plummets.
Case Study 2: “Responsible Corp.” – The Strategic Approach
- Scenario: Responsible Corp. has the same goal: automating resume screening.
- Implementation: The project kicks off with an Ethical Impact Assessment. The AI Ethics Committee immediately flags it as a high-risk application. They mandate a thorough analysis of the historical hiring data, which reveals a significant historical bias against female and minority candidates. Instead of using this data to predict past hiring decisions, they redefine the project’s goal: to predict candidate skills based on a carefully curated rubric. They use fairness-aware machine learning techniques to train the model, explicitly minimizing the correlation between the model’s output and sensitive demographic attributes. They use LIME to ensure the model is focusing on relevant skills (e.g., “Python,” “system design”) and not on proxies for gender or race. Before deployment, they run a pilot program where the AI’s recommendations are reviewed by human recruiters, and they establish a clear appeals process for rejected candidates.
- Outcome: The development process is slower and more deliberate. However, the deployed system is not only efficient but also demonstrably fairer. It helps recruiters identify qualified candidates from non-traditional backgrounds that they might have previously overlooked. Responsible Corp. publishes a whitepaper on their methodology, enhancing their brand reputation as an ethical and innovative employer. The system provides sustainable business value while actively promoting diversity and inclusion.
Implementation Strategies: Fostering a Culture of Responsibility
A framework is only as effective as the culture that supports it. Implementing responsible AI is a change management challenge that requires buy-in from all levels of the organization.
- Executive Sponsorship: The commitment to AI ethics must start at the top. Leaders must articulate a clear vision for responsible AI, allocate resources to support the governance framework, and empower the Ethics Committee.
- Education and Training: All stakeholders, from engineers to executives, must be trained on the principles of AI ethics and the company’s specific policies. This is not a one-time event but an ongoing educational effort.
- Incentive Alignment: Performance metrics and incentives should be updated to reward responsible behavior. If engineers are only evaluated on model accuracy, they will not prioritize fairness. Include metrics related to fairness, transparency, and the successful completion of ethical impact assessments in performance reviews.
- Embrace Transparency: Be transparent, both internally and externally, about your approach to AI ethics. Publish your principles, share case studies (both successes and failures), and engage in open dialogue with customers and the public. This builds trust and holds the organization accountable.
Tools and Assessment Methods
- Fairness Toolkits:
- AI Fairness 360 (AIF360) by IBM: An open-source library with a comprehensive set of fairness metrics and bias mitigation algorithms.
- Fairlearn by Microsoft: An open-source Python package that enables developers to assess and improve the fairness of their models.
- Google’s What-If Tool: An interactive visual interface integrated into TensorBoard that allows developers to probe model behavior on different data slices and under different fairness constraints.
- Explainability Libraries:
- SHAP (SHapley Additive exPlanations): A game theory-based approach to explaining the output of any machine learning model. It is one of the most robust and widely used methods.
- LIME (Local Interpretable Model-agnostic Explanations): A technique that explains individual predictions by approximating the underlying model with a simpler, interpretable one in the local vicinity of the prediction.
- Assessment Templates:
- Datasheets for Datasets: A template for documenting the characteristics of a training dataset, inspired by datasheets for electronic components. It details motivation, composition, collection process, and recommended uses.
- Model Cards: A framework for reporting a model’s performance characteristics, including its intended uses, evaluation data, performance metrics across different groups, and ethical considerations.
Industry Applications and Case Studies
The principles of responsible AI are not theoretical; they are being applied, and sometimes learned the hard way, across numerous industries. Examining these real-world scenarios highlights the tangible business and societal value of an ethical approach.
- Finance: Credit Scoring and Lending: Financial institutions increasingly use AI to determine creditworthiness. The primary ethical challenge is ensuring these models do not discriminate against protected groups. Application: A fintech company deploys a loan approval model. Challenge: The model, trained on historical data, learns that zip code is a powerful predictor of loan defaults. However, since zip code is a strong proxy for race in many regions, this leads to discriminatory lending practices, a violation of fair lending laws. Solution: Using a responsible AI framework, the company implements a fairness-aware learning algorithm that is constrained to reduce the statistical dependence between the model’s output and the applicants’ race-associated zip codes. They also use SHAP to provide loan officers and, upon request, customers with the top reasons for a decision, enhancing transparency and complying with regulations requiring adverse action notices. The business impact is reduced regulatory risk and increased trust among a broader customer base.
- Healthcare: Medical Diagnostics: AI models, particularly in medical imaging, can diagnose diseases like cancer with superhuman accuracy. Application: A hospital system uses an AI to detect diabetic retinopathy from retinal scans. Challenge: An initial model, trained on data from a predominantly white population, performs poorly when deployed in a community with a more diverse patient base, failing to detect the disease in patients with different levels of retinal pigmentation. Solution: The development team engages in a targeted data collection effort to create a more representative dataset. They publish a “Model Card” detailing the model’s performance across different demographic groups (age, race, gender) and explicitly state its limitations. This ensures clinicians are aware of where the model is most and least reliable, leading to safer and more equitable clinical outcomes.
- Human Resources: Automated Hiring and Promotion: As seen in the case study, HR departments use AI to filter resumes and even analyze video interviews. Application: A large corporation uses an AI tool to identify employees with high potential for promotion. Challenge: The tool, trained on the career trajectories of current senior leaders (who are mostly male), consistently ranks male employees as having higher potential. Solution: The HR and AI teams collaborate to redefine the problem. Instead of predicting “promotion potential” based on a biased past, they build separate models to predict specific, objective skills and competencies. They conduct regular fairness audits to ensure the tools are not creating disparate impacts. This leads to a more objective and equitable promotion process, improving employee morale and diversity in leadership.
Best Practices and Common Pitfalls
Navigating the complex landscape of AI ethics requires vigilance and adherence to best practices. Avoiding common pitfalls is as important as adopting the right techniques.
- Best Practice: Adopt a Multidisciplinary Approach. Responsible AI is not just a coding problem. Involve legal experts, ethicists, social scientists, and domain specialists from the very beginning of a project. Their diverse perspectives are invaluable for identifying risks that a purely technical team might miss.
- Common Pitfall: The “Fairness as a Checkbox” Mentality. Do not treat ethical assessments as a bureaucratic hurdle to be cleared. Simply running a fairness tool and reporting a metric is not enough. Teams must deeply understand the context of their application and engage in a thoughtful, value-driven discussion about which fairness trade-offs are acceptable and why.
- Best Practice: Document Everything. Create a detailed audit trail for every AI project. This includes the rationale for the project, the datasheet for the training data, the results of bias and fairness audits, the decisions made during the ethical review process, and the model card for the final deployed system. This documentation is critical for accountability and debugging.
- Common Pitfall: Over-relying on Automated Tools. Fairness and explainability tools are powerful aids, but they are not a substitute for critical thinking. An explanation from SHAP might show which features were important, but it doesn’t explain why the model learned that correlation or whether that correlation is spurious or just. Human judgment is still required to interpret the outputs of these tools.
- Best Practice: Plan for Redress and Contestation. No AI system is perfect. Design clear, accessible channels for individuals to appeal or contest an AI-driven decision that affects them. This “human in the loop” for appeals is a cornerstone of accountable systems and is increasingly a legal requirement.
- Common Pitfall: Forgetting Post-Deployment. The ethical risks of an AI system can change after it is deployed. The distribution of data it sees in the real world may shift, leading to performance degradation or emergent biases. A robust monitoring system that tracks both accuracy and fairness metrics over time is essential.
Hands-on Exercises
These exercises are designed to translate the theoretical concepts from this chapter into practical skills.
- Individual Exercise: The Data Detective.
- Objective: Develop an intuition for identifying potential biases in a dataset.
- Task: Download the “Adult” dataset from the UCI Machine Learning Repository, a common benchmark for fairness research. Using a Python notebook with libraries like Pandas and Matplotlib, perform an exploratory data analysis.
- Guidance:
- Calculate the distribution of the target variable (
income > 50K) across different sensitive attributes likeraceandsex. - Create visualizations (bar charts, histograms) to show these distributions.
- Write a brief (1-2 paragraph) summary of the potential representation biases you have found and hypothesize how a model trained on this data might perform unfairly.
- Calculate the distribution of the target variable (
- Verification: Your summary should correctly identify that certain groups are underrepresented and have a lower proportion of high-income individuals in the dataset.
- Individual Exercise: Fairness Audit.
- Objective: Use a fairness toolkit to measure bias in a trained model.
- Task: Train a simple logistic regression classifier on the “Adult” dataset to predict income. Using the
fairlearnlibrary in Python, calculate and compare at least two different group fairness metrics (e.g., demographic parity difference, equalized odds difference). - Guidance:
- Split the data into training and testing sets.
- Train the model.
- Use
fairlearn.metricsto compute the fairness metrics for thesexattribute. - Interpret the results: what do these numbers tell you about the model’s fairness?
- Verification: The code should correctly compute the fairness metrics, and the interpretation should accurately describe the degree of disparity in the model’s predictions between male and female subgroups.
- Team-Based Exercise: Ethical Impact Assessment Role-Play.
- Objective: Practice the collaborative process of assessing the ethical risks of a new AI application.
- Task: Your team is proposing to develop an AI system for a university that predicts which students are at high risk of dropping out, so that advisors can intervene.
- Guidance:
- Assign roles to team members: Project Manager, Lead AI Engineer, University Legal Counsel, and a Student Advocate.
- As a group, fill out a simplified Ethical Impact Assessment template. Brainstorm potential harms (e.g., stigmatization of students, bias against low-income students).
- Discuss and document potential mitigation strategies for the top three risks you identify.
- Verification: The completed assessment should identify plausible risks beyond simple model accuracy and propose concrete, actionable mitigation strategies that consider the perspectives of all assigned roles.
Tools and Technologies
To put the principles of responsible AI into practice, engineers rely on a growing ecosystem of tools and frameworks. Mastery of these tools is becoming a key skill for AI professionals.
- Core Libraries (Python):
fairlearn(Microsoft): A Python package for assessing and improving the fairness of machine learning models. It is well-documented and integrates with Scikit-learn.pip install fairlearnAI Fairness 360(IBM): A comprehensive open-source toolkit with over 70 fairness metrics and 10 bias mitigation algorithms. It is more extensive thanfairlearnbut can have a steeper learning curve.shap(SHapley Additive exPlanations): The primary library for implementing SHAP, providing powerful model-agnostic explanations.pip install shap
- Platform Integration:
- Google Cloud AI Platform: Includes tools like “Explainable AI” which provides feature attributions for models, and “What-If Tool” for interactive model probing. These are integrated directly into the cloud MLOps workflow.
- Amazon SageMaker: Offers “SageMaker Clarify,” a feature that provides insights into training data and models to help identify potential bias and explain model predictions.
- Azure Machine Learning: Has a “Responsible AI dashboard” that integrates
fairlearnand other tools into a unified interface for assessing models.
- Version Compatibility: As of early 2025, these tools are generally compatible with Python 3.9+ and major ML frameworks like TensorFlow 2.15+ and Scikit-learn 1.3+. Always check the official documentation for the latest dependency requirements before starting a new project.
Tip: Start with
fairlearnfor fairness audits andshapfor explainability. They offer a powerful combination of functionality and ease of use for most common scenarios.
Summary
This chapter established the critical importance of ethics and responsibility in the field of AI engineering. We moved from abstract principles to concrete technical and strategic implementations.
- Key Concepts: We defined and explored the interconnected triad of Fairness, Accountability, and Transparency (FAT) as the foundation of responsible AI.
- Bias Mitigation: We analyzed the various sources of bias—in data, algorithms, and human interaction—and outlined strategies for identifying and mitigating them throughout the MLOps lifecycle.
- Strategic Implementation: We introduced a comprehensive framework for Responsible AI Governance, including the establishment of an ethics committee, the use of risk-based assessments, and the integration of ethical checkpoints into development workflows.
- Practical Skills: You have learned about industry-standard tools for fairness auditing (
fairlearn) and explainability (shap), and have practiced applying these concepts through hands-on exercises. - Real-World Relevance: The case studies and industry examples demonstrate that responsible AI is not just an ethical imperative but a crucial factor for business success, risk management, and long-term sustainability.
Mastering the content of this chapter will not only make you a better engineer but also a more responsible innovator, capable of building AI systems that are both powerful and principled.
Further Reading and Resources
- Buolamwini, J., & Gebru, T. (2018). Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. Proceedings of the 1st Conference on Fairness, Accountability and Transparency. (A seminal academic paper that exposed bias in commercial AI systems).
- The EU AI Act: The official legislative text from the European Union. Reading the primary source is essential for understanding the direction of global AI regulation. (https://artificialintelligenceact.eu/)
- Google AI’s Responsible AI Practices: A set of tools, resources, and best practices from a leading industry player. (https://ai.google/principles/)
- O’Neil, C. (2016). Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. A highly influential and accessible book that provides compelling case studies of algorithmic harm.
fairlearnDocumentation: The official documentation and user guide for the Fairlearn Python package. (https://fairlearn.org/)- Christoph Molnar’s Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. An excellent and comprehensive online book covering the theory and practice of XAI. (https://christophm.github.io/interpretable-ml-book/)
- Datasheets for Datasets by Timnit Gebru et al.: The original research paper proposing a framework for dataset documentation. (https://arxiv.org/abs/1803.09010)
Glossary of Terms
- Accountability: The principle of establishing clear responsibility for the outcomes of an AI system, including mechanisms for redress.
- Algorithmic Bias: Bias that is introduced by the design of the algorithm itself, which may systematically favor certain outcomes over others.
- Bias: In the context of AI ethics, a systematic deviation from a standard of fairness, often resulting in prejudiced or discriminatory outcomes against certain groups.
- Demographic Parity: A group fairness metric that is satisfied if the probability of receiving a positive outcome is the same for all demographic groups.
- Equal Opportunity: A group fairness metric that is satisfied if the true positive rate is the same for all demographic groups.
- Explainable AI (XAI): A field of AI research and practice focused on developing methods to explain and interpret the decisions made by machine learning models, especially “black box” models.
- Fairness: The principle that an AI system’s outcomes should be just and equitable, and not create or perpetuate discrimination.
- FAT (Fairness, Accountability, Transparency): A triad of interconnected principles that form a framework for responsible AI.
- Model Card: A short document providing key information about a machine learning model, including its intended use, performance metrics across different groups, and ethical considerations.
- Proxy Variable: A feature in a dataset that is not itself sensitive but is highly correlated with a sensitive attribute, and can be used by a model to make discriminatory predictions.
- SHAP (SHapley Additive exPlanations): A popular XAI technique that uses concepts from cooperative game theory to explain individual predictions by assigning an importance value to each feature.
- Transparency: The principle that the inner workings and decision-making processes of an AI system should be understandable to a degree appropriate for the context.
