
Chapter 29: Data Validation and Quality Assurance for Machine Learning
Chapter Objectives
Upon completing this chapter, you will be able to:
- Understand the critical role of data quality in the machine learning lifecycle and articulate the business impact of data-related failures.
- Design comprehensive data validation strategies that encompass schema, statistical, and business logic checks.
- Implement automated data validation pipelines using modern Python frameworks such as Pandera and Great Expectations.
- Analyze data quality reports to diagnose issues like data drift, schema violations, and outliers.
- Integrate data validation steps into production MLOps workflows, including CI/CD pipelines and automated data ingestion systems.
- Deploy monitoring solutions to continuously assess data quality in live production environments and trigger alerts on quality degradation.
Introduction
In the intricate architecture of modern AI systems, data serves as the foundational bedrock. The adage “Garbage In, Garbage Out” (GIGO) has never been more pertinent; the performance, reliability, and fairness of even the most sophisticated machine learning models are fundamentally constrained by the quality of the data they are trained and evaluated on. Poor data quality is not a minor inconvenience but a primary driver of model failure, biased outcomes, and significant financial loss in enterprise AI. Issues ranging from silent data corruption in upstream sources to unexpected shifts in production data distributions can invalidate models, erode user trust, and lead to flawed business decisions.
This chapter confronts this challenge directly by establishing a rigorous engineering discipline around data validation and quality assurance. We will move beyond ad-hoc data cleaning scripts and manual checks to the design and implementation of robust, automated, and scalable data validation pipelines. You will learn to treat data quality not as a preliminary, one-off task, but as a continuous, integral component of the MLOps lifecycle. We will explore the theoretical underpinnings of data validation, from schema enforcement and statistical drift detection to the codification of complex business rules. By mastering the concepts and tools presented here, you will gain the ability to build resilient machine learning systems that can proactively identify and mitigate data quality issues, ensuring that your models are not only powerful but also trustworthy and reliable in production environments. This chapter will equip you with the essential skills to construct the guardrails that prevent bad data from derailing your AI initiatives.
Technical Background
The Imperative of Data Quality in Machine Learning
The success of any machine learning system is inextricably linked to the quality of its underlying data. This relationship extends far beyond the initial training phase and permeates the entire lifecycle of the model, from development and validation to production monitoring. A model trained on flawed, incomplete, or unrepresentative data will internalize these imperfections, leading to poor predictive performance and potentially harmful biases. For instance, a credit risk model trained on data with missing income values for a specific demographic might systematically underestimate their creditworthiness. Similarly, a manufacturing defect detection system fed with incorrectly labeled images will fail to perform its core function, leading to costly quality control failures. The impact of poor data quality is therefore not merely technical but has direct and often severe business consequences.
Data quality issues manifest in numerous forms: schema violations, such as a column expected to contain integers suddenly receiving string values; statistical drift, where the distribution of a feature in production deviates significantly from the training data; outliers and anomalies, representing corrupt or simply unexpected data points; and violations of business logic, such as an e-commerce order with a negative purchase quantity. Without automated systems to detect these issues, they often go unnoticed until the model’s performance degrades significantly—a silent failure that can persist for weeks or months. The goal of a robust data validation framework is to make these failures loud, immediate, and actionable. It acts as a set of automated checks and balances, ensuring that data conforms to a predefined contract of expectations at every stage of the ML pipeline. This proactive approach is a cornerstone of modern MLOps and a prerequisite for building enterprise-grade, reliable AI systems.
graph TD
subgraph "Data Pipeline"
A[Data Source <br><i>e.g., Database, API</i>] --> B{Data Validation Gate};
B -- "Good Data" --> C[Model Training / Inference];
B -- "Bad Data" --> D[Quarantine & Alert];
end
%% Styling
classDef primary fill:#283044,stroke:#283044,stroke-width:2px,color:#ebf5ee;
classDef process fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044;
classDef decision fill:#f39c12,stroke:#f39c12,stroke-width:1px,color:#283044;
classDef success fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
classDef warning fill:#f1c40f,stroke:#f1c40f,stroke-width:1px,color:#283044;
class A primary;
class B decision;
class C success;
class D warning;
Core Terminology and Mathematical Foundations
To formalize the process of data validation, we must first establish a precise vocabulary and mathematical framework. At the heart of validation is the concept of a data schema, which defines the expected structure of the data. This includes column names, data types (e.g., integer, float, string, datetime), and nullability constraints. A more advanced schema might also include constraints on value ranges, such as ensuring a user_age column is always between 0 and 120.
Beyond structural integrity, we are deeply concerned with the statistical properties of the data. A key challenge in production ML is data drift (also known as feature drift), which occurs when the statistical distribution of one or more input features changes over time. For a feature \(X\), if \(P_{train}(X)\) represents its probability distribution in the training set and \(P_{prod}(X)\) represents its distribution in production, data drift occurs when \(P_{train}(X) \neq P_{prod}(X)\). This is problematic because the model learned a mapping \(f(X) \to Y\) based on \(P_{train}(X)\), and its performance is not guaranteed when the input distribution changes.
To detect drift, we employ statistical hypothesis tests. For numerical features, the Kolmogorov-Smirnov (K-S) test is a powerful non-parametric test that compares the cumulative distribution functions (CDFs) of two samples. The K-S statistic, \(D\), is defined as the maximum absolute difference between the two CDFs: \(D = \sup_x |F_{train}(x) – F_{prod}(x)|\). A large \(D\) value and a correspondingly small p-value suggest that the two samples are drawn from different distributions, indicating drift. For categorical features, the Chi-Squared (\(\chi^2\)) test is commonly used to compare the observed frequencies of categories against the expected frequencies from the training data.
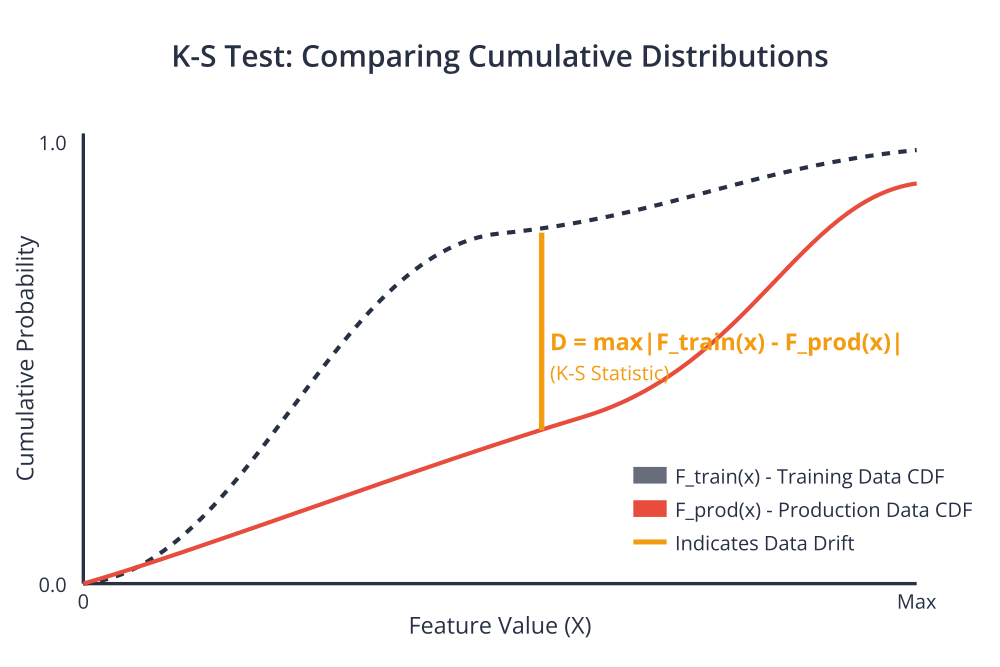
A related but distinct concept is concept drift, where the statistical properties of the target variable \(Y\) or the relationship between \(X\) and \(Y\) change. This means \(P_{prod}(Y|X) \neq P_{train}(Y|X)\). For example, in a fraud detection system, the patterns defining fraudulent behavior might evolve as fraudsters adapt their strategies. Detecting concept drift often requires labeled production data and monitoring the model’s predictive performance metrics (e.g., accuracy, precision, recall).
Data Drift vs. Concept Drift
| Aspect | Data Drift (or Feature Drift) | Concept Drift |
|---|---|---|
| What Changes? | The statistical distribution of the input data (the features, X). | The relationship between the input data (X) and the target variable (Y). |
| Formal Definition | Pprod(X) ≠ Ptrain(X) | Pprod(Y|X) ≠ Ptrain(Y|X) |
| Example | A fraud detection model sees transaction amounts that are, on average, much higher in production than in training due to inflation. | The patterns of fraudulent transactions change as fraudsters adopt new techniques. The same transaction features now predict a different outcome. |
| How to Detect | Statistical tests on input features (e.g., K-S test, Chi-Squared test) by comparing production data to a reference dataset. Can be done without labels. | Monitoring model performance metrics (e.g., accuracy, precision, recall) on labeled production data. Requires ground truth. |
Historical Development and Evolution
The practice of data validation is not new; it has its roots in traditional software engineering and database management, where concepts like data integrity constraints, type checking, and assertions have been used for decades to ensure application correctness. In the context of relational databases, schema enforcement, NOT NULL constraints, and CHECK constraints are fundamental tools for maintaining data quality at the storage layer. The extract, transform, load (ETL) processes in data warehousing also incorporated quality checks to ensure that data loaded into analytical systems was clean and consistent.
However, the rise of machine learning, particularly in the era of “big data,” introduced new challenges that these traditional methods were not fully equipped to handle. ML systems are uniquely sensitive to statistical distributions, not just schematic correctness. A database constraint can ensure a price column is a positive number, but it cannot, by itself, alert you if the average price of products suddenly doubles overnight—a distributional shift that could severely impact a pricing model. Furthermore, the scale and velocity of data in modern ML pipelines, often involving unstructured or semi-structured data from disparate sources, demanded more flexible, scalable, and automated validation solutions.
This led to the development of specialized data validation frameworks designed for the ML lifecycle. Early approaches often involved custom scripts written in Python or R, using libraries like Pandas for data manipulation and statistical libraries like SciPy for hypothesis testing. While functional, these custom solutions lacked standardization, were difficult to maintain, and required significant engineering effort to build and scale. The evolution of the MLOps field spurred the creation of open-source tools like Great Expectations and Pandera, which provide a declarative syntax for defining data quality tests, automate the process of validation, and generate comprehensive reports. These modern tools represent a paradigm shift, treating data validation as a first-class citizen in the engineering workflow, akin to unit testing for software code. They allow data contracts to be expressed explicitly in code, version-controlled, and executed automatically within CI/CD pipelines.
Evolution of Data Validation: Traditional vs. Modern ML Approaches
| Aspect | Traditional Approach (e.g., Databases, ETL) | Modern ML Approach (e.g., MLOps) |
|---|---|---|
| Primary Focus | Schema integrity, atomicity, and consistency at the storage layer. | Statistical distributions, data drift, and business logic relevant to model performance. |
| Key Concerns | Data types, nullability, uniqueness, referential integrity. | Feature distribution stability, concept drift, outliers, data freshness, and label quality. |
| Tooling | Database constraints (e.g., NOT NULL, CHECK), custom ETL scripts. |
Declarative frameworks (e.g., Great Expectations, Pandera), “validation as code.” |
| Timing of Validation | Primarily at the point of data loading (ETL) or writing to the database. | Continuous process: at ingestion, pre-training, and during live production monitoring. |
| Failure Handling | Typically rejects the write operation or fails the ETL job. | Triggers alerts, quarantines data, stops CI/CD pipelines, or enables model fallbacks. |
| Artifacts | Error logs, failed job reports. | Version-controlled expectation suites, comprehensive and shareable data quality reports (Data Docs). |
Architecting Automated Validation Pipelines
An effective data validation strategy cannot be an afterthought; it must be architected as an integral component of the end-to-end machine learning pipeline. The goal is to create automated “tollgates” through which data must pass before it can be used for training, evaluation, or inference. This prevents bad data from propagating downstream and corrupting ML assets. The placement of these validation steps is critical and depends on the specific goals at each stage of the MLOps lifecycle.
A common architectural pattern involves placing a validation step immediately after data ingestion. Before any raw data from upstream sources (e.g., production databases, event streams, third-party APIs) is landed in a data lake or warehouse, it undergoes a set of initial quality checks. This “gatekeeper” validation typically focuses on schema conformance, data types, and the presence of critical columns. Data that fails these checks can be routed to a quarantine area for manual inspection, or an alert can be triggered to notify the data source owner. This initial step ensures that the foundational data storage layer remains clean and trustworthy.
graph TD
subgraph "Data Ingestion & Preparation"
A[Upstream Data Sources] --> B(Ingest Data);
B --> C{Validation Gate 1: <br><b>Schema & Integrity</b>};
C -- Pass --> D[Clean Data Lake];
C -- Fail --> E[Quarantine Area 1];
end
subgraph "Model Development & Training"
D --> F(Curate Training Dataset);
F --> G{Validation Gate 2: <br><b>Statistical & Business Logic</b>};
G -- Pass --> H[Model Training & Tuning];
G -- Fail --> I[Alert Data Science Team];
end
subgraph "Production Deployment & Monitoring"
H --> J(Deploy Model to API);
K[Live Inference Requests] --> J;
J --> L{Validation Gate 3: <br><b>Real-time Monitoring</b>};
L -- Pass --> M[Generate Prediction];
L -- Fail --> N[Alert On-Call Engineer <br> & Trigger Fallback];
end
%% Styling
classDef primary fill:#283044,stroke:#283044,stroke-width:2px,color:#ebf5ee;
classDef process fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044;
classDef decision fill:#f39c12,stroke:#f39c12,stroke-width:1px,color:#283044;
classDef success fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
classDef model fill:#e74c3c,stroke:#e74c3c,stroke-width:1px,color:#ebf5ee;
classDef warning fill:#f1c40f,stroke:#f1c40f,stroke-width:1px,color:#283044;
class A,K primary;
class B,D,F,H,J,M process;
class C,G,L decision;
class E,I,N warning;
Design Patterns and Best Practices
Beyond the initial ingestion gate, validation should be applied at other key points. Before a model training job is initiated, the curated training dataset should be validated against a more comprehensive set of expectations. This includes not only schema checks but also statistical tests for drift compared to a reference dataset (e.g., the data used to train the previous model version) and checks for business logic invariants. This pre-training validation ensures that the model is not trained on data that has fundamentally changed, which could lead to unexpected behavior.
Another critical pattern is continuous validation or production data monitoring. Once a model is deployed, the live inference data it receives must be continuously monitored for quality issues. This involves running the same validation logic on the stream of incoming inference requests. This is crucial for detecting real-time data quality problems, such as a malfunctioning sensor feeding anomalous data to an IoT predictive maintenance model, or a change in a partner’s API format breaking an input feature. When a validation failure is detected in production, the system can be designed to trigger alerts, fall back to a default prediction, or even temporarily disable the model to prevent it from making erroneous predictions based on corrupt data.
A best practice in designing these pipelines is to manage validation rules as code. Expectations or constraints should be defined in a declarative format (e.g., YAML, JSON, or a Python-based DSL), stored in a version control system like Git, and applied consistently across different environments (development, staging, production). This “validation as code” approach brings the same benefits of rigor, reproducibility, and collaboration to data quality management as “infrastructure as code” brings to system administration.
sequenceDiagram
actor Engineer
participant Git as Version Control
participant CI_CD as CI/CD Pipeline
participant Validator as Validation Service
participant Datalake as Data Storage
Engineer->>Git: 1. Push changes to validation rules (e.g., schema.py)
Git->>CI_CD: 2. Trigger pipeline on commit
CI_CD->>Datalake: 3. Fetch sample data batch
CI_CD->>Validator: 4. Run validation with new rules on data batch
Validator-->>CI_CD: 5. Return validation result (Pass/Fail)
alt Validation Passes
CI_CD->>Git: 6a. Merge changes to main branch
CI_CD->>Engineer: 7a. Notify: Success
else Validation Fails
CI_CD->>Git: 6b. Block merge
CI_CD->>Engineer: 7b. Notify: Failure with report
end
Advanced Topics and Modern Approaches
As machine learning systems become more complex and operate at a larger scale, the need for more sophisticated validation techniques grows. Simple range checks and type enforcement are necessary but not sufficient for catching subtle yet impactful data quality issues. Modern approaches leverage statistical methods and even machine learning itself to build more intelligent and adaptive data quality systems.
One of the most important advanced topics is the use of unsupervised learning for anomaly and outlier detection. While rule-based systems are excellent for catching known failure modes (e.g., a user_id must be a positive integer), they cannot anticipate all possible ways data can become corrupted. Anomaly detection algorithms, such as Isolation Forest or Local Outlier Factor (LOF), can learn the normal patterns within a dataset and flag data points that deviate significantly from this norm. For example, in a high-dimensional dataset of sensor readings, a combination of values might be individually within their valid ranges but collectively represent an impossible physical state. An anomaly detection model could identify such multivariate outliers that would be missed by simple, per-feature validation rules. This technique is particularly valuable for monitoring high-velocity data streams in production, providing a safety net for “unknown unknowns.”
Data Provenance and Lineage for Trustworthiness
Another critical area is data provenance and lineage. Data provenance refers to the record of the origins of data and the processes by which it arrived in its current state. Data lineage provides a map of the data’s journey, showing how it is transformed and used across different systems. In the context of data validation, lineage is essential for debugging quality issues. When a validation check fails, a data lineage graph can help an engineer quickly trace the problematic data back to its source, identify the specific transformation step that introduced the error, and understand which downstream assets (e.g., models, reports) are affected. Tools like dbt (Data Build Tool) and open standards like OpenLineage are becoming central to modern data stacks, enabling automated lineage tracking. This capability is not only crucial for operational robustness but also for regulatory compliance and governance, as it provides a clear, auditable trail of how data is used to make automated decisions. By integrating validation results with lineage information, organizations can build a comprehensive and trustworthy picture of their data’s health and history.
Practical Examples and Implementation
Development Environment Setup
To effectively implement the data validation strategies discussed, we will use a modern Python-based environment. The primary tools for this chapter are Pandera and Great Expectations, two leading open-source libraries for data validation.
- Python: We recommend using Python 3.11 or newer.
- Pandera: A lightweight, flexible, and expressive library for data validation, particularly well-suited for use with Pandas DataFrames. It allows you to define schemas as code.
- Great Expectations: A more comprehensive and feature-rich framework for data quality. It introduces the concepts of “Expectations,” “Data Context,” and “Data Docs” to create a powerful, collaborative environment for managing data quality.
You can set up your environment using a virtual environment and pip:
# Create and activate a virtual environment
python -m venv venv
source venv/bin/activate
# Install necessary libraries
pip install pandas pandera great-expectations
Note: For production use cases, you would typically manage these dependencies using a
requirements.txtorpyproject.tomlfile and install them as part of a CI/CD pipeline or Docker image build process.
Core Implementation Examples
Let’s explore how to define and apply data validation rules using both Pandera and Great Expectations. We’ll use a sample dataset of customer transactions.
Example 1: Schema Validation with Pandera
Pandera excels at defining schemas as Python objects, which can be version-controlled and reused. This approach feels very natural for developers and integrates seamlessly with data processing code.
Imagine we have a Pandas DataFrame with the following structure:
transaction_id: Unique identifier (string)customer_id: Customer identifier (integer)transaction_amount: The amount of the transaction (float, must be positive)transaction_date: The date of the transaction (datetime)
Here is a complete, working example of defining and applying a Pandera schema.
import pandas as pd
import pandera as pa
from pandera.errors import SchemaError
# Define a Pandera schema for our transaction data
# This schema acts as a "data contract"
transaction_schema = pa.DataFrameSchema({
'transaction_id': pa.Column(str, checks=pa.Check.str_startswith('txn_'), unique=True, description="Unique transaction identifier"),
'customer_id': pa.Column(int, checks=pa.Check.gt(0), description="Unique customer identifier"),
'transaction_amount': pa.Column(float, checks=[
pa.Check.gt(0.0, error="Transaction amount must be positive"),
pa.Check.le(10000.0, error="Transaction amount seems unusually high")
], nullable=False),
'transaction_date': pa.Column(pa.DateTime, checks=pa.Check.le(pd.to_datetime('today')), coerce=True)
})
# --- Create sample data ---
# 1. Good data that conforms to the schema
good_data = pd.DataFrame({
'transaction_id': ['txn_001', 'txn_002', 'txn_003'],
'customer_id': [101, 102, 101],
'transaction_amount': [150.75, 99.99, 1234.00],
'transaction_date': ['2025-08-19', '2025-08-18', '2025-08-19']
})
# 2. Bad data with several violations
bad_data = pd.DataFrame({
'transaction_id': ['txn_004', 'txn_005', 'txn_005'], # Not unique
'customer_id': [103, -104, 105], # Negative customer_id
'transaction_amount': [250.00, 0.0, 15000.00], # Zero and too high amount
'transaction_date': ['2025-08-20', '2025-08-21', 'not_a_date'] # Future date and invalid format
})
# --- Validation Logic ---
def validate_data(df: pd.DataFrame, schema: pa.DataFrameSchema):
"""
Validates a DataFrame against a Pandera schema.
Handles errors gracefully and prints informative messages.
"""
try:
print("Attempting to validate DataFrame...")
validated_df = schema.validate(df, lazy=True)
print("Validation successful!")
return validated_df
except SchemaError as err:
print("Validation failed!")
print("Detailed errors:")
# The 'lazy=True' parameter collects all errors instead of stopping at the first one.
print(err.failure_cases)
return None
# --- Run validation ---
print("--- Validating good_data ---")
validate_data(good_data, transaction_schema)
print("\n" + "="*50 + "\n")
print("--- Validating bad_data ---")
validate_data(bad_data, transaction_schema)
This example demonstrates how Pandera provides clear, actionable error messages that pinpoint exactly which data points failed validation and why. The lazy=True argument is particularly useful for getting a complete picture of all data quality issues at once.
Step-by-Step Tutorials
Tutorial: Creating a Great Expectations Suite
Great Expectations is more structured than Pandera and is designed for building comprehensive data quality test suites that can be executed against datasets. It generates detailed HTML reports, which it calls “Data Docs,” that are excellent for collaboration between technical and non-technical stakeholders.
Step 1: Initialize a Data Context
The Data Context manages your project’s configuration.
# In your terminal, in your project directory
great_expectations init
This command creates a great_expectations subdirectory with configuration files.
Step 2: Connect to a Data Source
Next, you’ll configure a Datasource to tell Great Expectations where your data lives. Let’s assume our transaction data is in a CSV file named transactions.csv.
# This command walks you through connecting to your data
great_expectations datasource new
Follow the prompts to connect to your filesystem and select the CSV file.
Step 3: Create an Expectation Suite
An Expectation Suite is a collection of assertions about your data. You can create one interactively.
# The CLI will profile your data and suggest expectations
great_expectations suite new
You will be prompted to select the data asset and a name for your suite (e.g., transactions.warning). The interactive session will open a Jupyter Notebook that allows you to explore your data and define expectations.
Here’s how you would define some expectations programmatically, which is what the interactive session helps you build:
import great_expectations as ge
# This code would typically be run within the notebook generated by the CLI
# or in a Python script that has loaded a Data Context.
# Assume 'context' is a loaded Great Expectations Data Context
# and we are working with a batch of data.
validator = context.get_validator(
batch_request=your_batch_request, # Points to your transaction data
expectation_suite_name="transactions.warning"
)
# Schema-level expectations
validator.expect_table_columns_to_match_ordered_list([
'transaction_id', 'customer_id', 'transaction_amount', 'transaction_date'
])
validator.expect_column_values_to_not_be_null('transaction_id')
validator.expect_column_values_to_be_unique('transaction_id')
# Column-specific expectations
validator.expect_column_values_to_be_of_type('customer_id', 'INTEGER')
validator.expect_column_values_to_be_between('transaction_amount', min_value=0.01, max_value=10000.0)
validator.expect_column_values_to_match_strftime_format('transaction_date', '%Y-%m-%d')
# More complex, business-logic expectations
validator.expect_column_values_to_match_regex('transaction_id', r'^txn_.*')
# Save the suite to your project
validator.save_expectation_suite(discard_failed_expectations=False)
Step 4: Validate Data with a Checkpoint
A Checkpoint bundles a batch of data with an Expectation Suite for validation.
# Create a new checkpoint via the CLI
great_expectations checkpoint new my_transaction_checkpoint
This will again open a notebook to help you configure the checkpoint.
Step 5: Run the Checkpoint and Review Data Docs
Once configured, you can run the validation.
great_expectations checkpoint run my_transaction_checkpoint
After the run completes, Great Expectations will open the Data Docs in your browser. This is the key output: a detailed, human-readable report showing which expectations passed and failed, along with the observed values that caused failures.
Integration and Deployment Examples
Automated data validation provides the most value when integrated directly into your data pipelines.
Integration with an MLOps Pipeline (e.g., Airflow)
In a production pipeline orchestrated by a tool like Apache Airflow, you can add a validation task that runs before any model training or data processing task.
# Example Airflow DAG task using the Great Expectations operator
from airflow.providers.great_expectations.operators.great_expectations import GreatExpectationsOperator
validate_raw_data = GreatExpectationsOperator(
task_id='validate_raw_data',
data_context_root_dir='/path/to/great_expectations',
checkpoint_name='my_transaction_checkpoint',
fail_task_on_validation_failure=True # This will stop the DAG if data quality is poor
)
# Define task dependencies
# The training task will only run if validation succeeds
validate_raw_data >> model_training_task
Warning: Setting
fail_task_on_validation_failure=Trueis a powerful way to enforce data quality, but it’s important to have a clear operational procedure for handling these failures, including who gets notified and how the issue is triaged.
Industry Applications and Case Studies
The principles of automated data validation are not merely academic; they are actively deployed across industries to protect revenue, mitigate risk, and ensure the reliability of AI-driven products.
- Financial Services (Fraud Detection): In finance, models are used to detect fraudulent credit card transactions in real-time. The input features for these models include transaction amount, merchant category, time of day, and location. A sudden drift in the distribution of transaction amounts could indicate a new type of fraud or, conversely, a data ingestion error. Automated validation pipelines continuously monitor these feature distributions using K-S tests. If significant drift is detected, the system can alert a team of analysts and potentially route transactions through a more conservative, rule-based system until the model’s reliability can be re-assessed. This prevents both financial losses from missed fraud and customer dissatisfaction from incorrectly blocked transactions.
- Healthcare (Medical Imaging Analysis): AI models that analyze medical images (e.g., X-rays, MRIs) to detect diseases are highly sensitive to the quality and format of input images. A validation pipeline for a chest X-ray analysis model would include checks to ensure the image is in the correct format (e.g., DICOM), has the expected resolution, and that metadata tags like patient orientation are present and valid. It might also include a check to ensure the image brightness and contrast fall within a normal range, flagging images that are too dark or washed out. This prevents the model from making life-critical predictions based on corrupted or low-quality input.
- E-commerce (Recommendation Engines): Personalization engines in e-commerce rely on user behavior data, such as clicks, views, and purchases. A data validation system would ensure that
product_idanduser_idfields always correspond to valid entries in the respective master databases. It would also monitor the click-through rate (CTR) of products. A sudden, inexplicable drop in the CTR for a popular item could indicate a data pipeline failure (e.g., clicks are not being logged correctly) rather than a genuine change in user interest. By flagging this anomaly, the data engineering team can fix the underlying issue before it negatively impacts the recommendation model’s performance and, by extension, the company’s revenue.
Best Practices and Common Pitfalls
Implementing a robust data validation strategy requires more than just choosing the right tools; it involves adopting a set of best practices that ensure the system is maintainable, scalable, and effective.
- Version Your Validation Rules: Treat your validation rules (e.g., Pandera schemas, Great Expectations suites) as code. Store them in a version control system like Git, and tie specific versions of your rules to specific versions of your models and datasets. This ensures reproducibility and provides an audit trail for how data quality standards have evolved.
- Validation is Not a Binary Pass/Fail: While some data quality issues are critical and should halt a pipeline (e.g., a missing critical column), others might be less severe. Implement a tiered approach. For example, a “strict” suite of expectations runs before model training, where failure is not an option. A “warning” suite might run on production data, where some failures trigger alerts for investigation but do not stop the system.
- Avoid Over-Constraining: It can be tempting to define very tight constraints on your data. However, overly specific rules can be brittle and lead to frequent, spurious failures when data changes in benign ways. Start with essential, stable constraints (schema, nulls, basic ranges) and add more specific statistical or business logic checks as you gain a better understanding of your data’s natural variance.
- Plan for Failure: When a validation check fails, what happens next? Your system design must include a clear failure path. Should the pipeline stop? Should the bad data be quarantined? Who gets notified? Answering these questions is crucial for operationalizing data quality. A common pitfall is setting up validation that generates alerts but having no one responsible for acting on them, leading to alert fatigue and ignored problems.
- Security and Privacy Considerations: Data validation systems often need to access and profile production data. Ensure that these systems adhere to security best practices. When generating reports or logs, be careful not to expose sensitive Personally Identifiable Information (PII). Data Docs from Great Expectations, for example, can show examples of failing data; configure your system to mask or omit sensitive columns from these reports.
Hands-on Exercises
- Basic Schema Definition (Individual):
- Objective: Create a Pandera schema for a simple dataset.
- Task: You are given a CSV file containing employee data with columns:
employee_id(integer, unique, positive),department(string, must be one of ‘HR’, ‘Engineering’, ‘Sales’),salary(float, between 40000 and 250000), andhire_date(datetime). Write a Python script that defines a Pandera schema to enforce these rules, loads the CSV into a Pandas DataFrame, and validates it. Test your script with both a “clean” and a “dirty” version of the CSV. - Success Criteria: The script correctly identifies all violations in the dirty file and prints a detailed error report.
- Building an Expectation Suite (Individual):
- Objective: Use Great Expectations to create and test a suite of expectations.
- Task: Using the same employee dataset from Exercise 1, initialize a Great Expectations Data Context. Use the interactive workflow (
suite new) to create an Expectation Suite. Include expectations for column existence, types, value sets (department), and ranges (salary). Create a checkpoint and run it against your clean and dirty data files. - Success Criteria: You have a saved Expectation Suite and can generate and view the Data Docs report showing the validation results for both files.
- Data Drift Detection (Team-based):
- Objective: Simulate and detect data drift between two datasets.
- Task: As a team, create two versions of a larger dataset (e.g., a housing prices dataset). The first (
data_t1.csv) represents training data. The second (data_t2.csv) represents production data a month later. Indata_t2.csv, intentionally introduce drift in one numerical column (e.g., increase the meansquare_footageby 20%) and one categorical column (e.g., change the distribution ofproperty_type). Use Great Expectations to build a suite that comparesdata_t2againstdata_t1and specifically checks for distribution changes using expectations likeexpect_column_kl_divergence_to_be_less_than. - Success Criteria: The validation run successfully flags the drift in the specified columns, and the team can explain the results in the Data Docs.
Tools and Technologies
- Pandera: A Python library for data validation that is lightweight, expressive, and integrates directly with Pandas. It is ideal for developers who want to define data contracts directly within their application code and for real-time validation in data processing scripts. Its strengths are its simplicity and tight integration with the PyData ecosystem.
- Great Expectations (GE): A comprehensive, open-source framework for data quality. GE is more opinionated than Pandera, providing a full “Data Context” for managing datasources, expectations, and validation results. Its key feature is the automatic generation of “Data Docs”—human-readable data quality reports. It is best suited for building robust, standalone data quality pipelines and fostering collaboration between data engineers, analysts, and domain experts.
- dbt (Data Build Tool): While primarily a data transformation tool, dbt has increasingly incorporated data quality features. Using
dbt tests, you can define data quality checks (e.g., uniqueness, not null, accepted values) directly within your data models as YAML configurations. This is an excellent choice for teams that have already adopted dbt for their data warehousing and transformation workflows, as it allows quality checks to live alongside the transformations that create the data. - Cloud-Native Solutions: Major cloud providers offer services for data quality management. For example, AWS has Deequ, a library built on Apache Spark for large-scale data profiling and validation, and Google Cloud has Dataplex Data Quality, which automates the process of defining and running quality checks on data in BigQuery and Google Cloud Storage.
Comparison of Data Validation Frameworks
| Framework | Primary Use Case | Strengths | Considerations |
|---|---|---|---|
| Pandera | Validation within Python scripts and applications; defining “data contracts” as code. | Lightweight, expressive, developer-friendly API, seamless integration with Pandas. | Less opinionated; reporting and data source management are left to the user. |
| Great Expectations | Building comprehensive, standalone data quality pipelines and fostering team collaboration. | Automatic “Data Docs” (HTML reports), extensive library of expectations, data source connectors. | More setup required (Data Context); can be more heavyweight for simple scripts. |
| dbt (Tests) | Integrating data quality checks directly into the data transformation and warehousing process. | Validation lives with data models, easy to add simple tests (uniqueness, not null), part of the analytics engineering workflow. | Less focused on statistical validation (e.g., drift); primarily for structural and referential integrity. |
| Cloud-Native Solutions | Leveraging managed services for data quality on large-scale data within a specific cloud ecosystem. | Scalability (built on Spark, etc.), deep integration with cloud storage and data warehouses. | Can lead to vendor lock-in; may be less flexible than open-source frameworks. |
Summary
- Data Quality is Foundational: The performance and reliability of any ML system are fundamentally limited by the quality of its data. “Garbage In, Garbage Out” is the central principle.
- Validation is a Multi-faceted Discipline: Effective data validation involves checking for schema integrity, statistical properties (like drift), and adherence to business logic.
- Automation is Key: Manual data checking is not scalable or reliable. Data validation must be implemented as an automated, integral part of the MLOps pipeline.
- Treat Validation as Code: Data quality rules and expectations should be defined declaratively, version-controlled, and tested, just like application code.
- Modern Frameworks Provide Structure: Tools like Pandera and Great Expectations provide the necessary abstractions and automation to build and manage sophisticated data quality systems efficiently.
- Context Matters: The appropriate validation strategy depends on the context. Checks at data ingestion may differ from those before model training or during production monitoring.
Further Reading and Resources
- Great Expectations Documentation: (docs.greatexpectations.io) – The official and comprehensive source for learning how to use the Great Expectations framework.
- Pandera Documentation: (pandera.readthedocs.io) – The official documentation for the Pandera library, with numerous examples and API references.
- “Clean Code: A Handbook of Agile Software Craftsmanship” by Robert C. Martin: While not about data, the principles of writing clean, maintainable, and testable code are directly applicable to writing clean, maintainable, and testable validation rules.
- Google Research Publication: “Everyone wants to do the model work, not the data work“: A foundational paper discussing the often-underestimated importance of data quality and data engineering in production ML.
- dbt (Data Build Tool) Documentation on Testing: (docs.getdbt.com) – An excellent resource for understanding how to integrate data quality tests directly into the data transformation process.
- “Designing Data-Intensive Applications” by Martin Kleppmann: A must-read for understanding the broader context of data systems, which provides the foundation upon which data quality systems are built.
- The MLOps Community Blog: (mlops.community) – A vibrant community and resource for articles and discussions on the practical aspects of MLOps, including data validation and monitoring.
Glossary of Terms
- Data Drift: A change in the statistical distribution of input features (\(X\)) between the training data and production data. Formally, \(P_{train}(X) \neq P_{prod}(X)\).
- Concept Drift: A change in the relationship between input features (\(X\)) and the target variable (\(Y\)). Formally, \(P_{train}(Y|X) \neq P_{prod}(Y|X)\).
- Data Schema: The formal definition of the structure of a dataset, including column names, data types, and constraints.
- Data Validation: The process of ensuring that data conforms to a set of predefined quality rules and expectations.
- Expectation Suite (Great Expectations): A collection of verifiable assertions about data.
- Data Docs (Great Expectations): Human-readable reports generated from the results of a validation run.
- Idempotent: An operation that can be applied multiple times without changing the result beyond the initial application. Data validation pipelines should strive to be idempotent.
- MLOps (Machine Learning Operations): A set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently.
- Data Provenance: The history of data, including its origins and the transformations it has undergone.
