
Chapter 3: AI, Machine Learning & Deep Learning: A Concept Hierarchy
Chapter Objectives
Upon completing this chapter, students will be able to:
- Differentiate between the core concepts of Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL), articulating their hierarchical relationship.
- Analyze a given technological problem and determine whether an AI, classic ML, or DL approach is most appropriate, justifying the choice based on data, interpretability, and performance requirements.
- Understand the historical evolution and paradigm shifts from symbolic AI (GOFAI) to data-driven learning, recognizing the key innovations that enabled the rise of ML and DL.
- Deconstruct complex, real-world AI systems (such as autonomous vehicles or recommendation engines) into their constituent ML and DL components.
- Evaluate the trade-offs between different approaches, including computational cost, data dependency, model explainability, and the need for manual feature engineering.
- Articulate the fundamental principles of major learning paradigms (supervised, unsupervised, reinforcement) and key neural network architectures (CNNs, RNNs, Transformers).
Introduction
In the lexicon of 21st-century technology, the terms Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) are often used interchangeably, creating a fog of ambiguity for newcomers and seasoned professionals alike. However, for the AI engineer, precision in language reflects precision in thought and implementation. Understanding the distinct definitions, capabilities, and relationships between these domains is not merely an academic exercise; it is fundamental to designing, building, and deploying effective intelligent systems. This chapter serves as a definitive guide, establishing a clear conceptual hierarchy and demystifying the landscape. AI is the all-encompassing quest to imbue machines with human-like intelligence, a field with roots stretching back to the mid-20th century. Machine Learning emerged as a powerful subfield of AI, representing a critical paradigm shift: instead of explicitly programming rules, we enable systems to learn rules from data. More recently, Deep Learning has revolutionized machine learning itself, employing deep neural networks to learn intricate patterns from vast datasets, automating feature discovery and achieving state-of-the-art performance in areas like computer vision and natural language processing. By dissecting this “Russian doll” structure, you will gain the foundational clarity required to navigate the modern AI ecosystem, make informed architectural decisions, and contribute to the ongoing technological revolution.
Technical Background
Artificial Intelligence (AI): The Quest for Intelligent Machines
Artificial Intelligence is the broadest of the three terms and represents the oldest dream: the creation of machines that can think, reason, and learn. It is a vast, interdisciplinary field of computer science, drawing on logic, mathematics, cognitive science, and philosophy. Its ultimate ambition is to simulate or replicate human intelligence in its entirety, though its practical applications are often focused on specific tasks.
Defining Intelligence: From Turing to Modern Systems
What does it mean for a machine to be “intelligent”? This question has been debated since the field’s inception. Alan Turing, in his seminal 1950 paper “Computing Machinery and Intelligence,” sidestepped a direct definition of “thinking” and instead proposed an operational test: The Turing Test. In this test, a human evaluator engages in a natural language conversation with both a human and a machine. If the evaluator cannot reliably distinguish the machine from the human, the machine is said to have passed the test and exhibited intelligent behavior. While influential, the Turing Test has been criticized for focusing on deception rather than genuine understanding. For instance, a system could pass by using clever tricks and a massive database of canned responses (like the early chatbot ELIZA) without any real comprehension.
Modern definitions of AI are more pragmatic and are often categorized into four approaches, as defined by Stuart Russell and Peter Norvig in their foundational text, Artificial Intelligence: A Modern Approach:
- Thinking Humanly: The cognitive modeling approach, which aims to build systems that think as humans do. This requires psychological experimentation and introspection to create testable theories of the human mind.
- Acting Humanly: The Turing Test approach, focusing on creating systems that perform actions indistinguishable from a human.
- Thinking Rationally: The “laws of thought” approach, based on formal logic. It seeks to build systems that reason through syllogisms and logical deduction to always arrive at correct conclusions.
- Acting Rationally: The rational agent approach, which is the dominant view in modern AI. A rational agent is a system that perceives its environment and takes actions to maximize its chances of achieving its goals. It is a more general and powerful concept than thinking rationally because it allows for correct inference where there is uncertainty and includes actions beyond pure deduction. An AI system that drives a car, for example, acts rationally to get from point A to B safely and efficiently, even without consciousness or human-like thought.
The Spectrum of AI: From Narrow to General Intelligence
The practical reality of AI today is far from the sentient robots of science fiction. We can categorize AI systems based on their level of capability and generality.
- Artificial Narrow Intelligence (ANI), also known as Weak AI, is the only form of AI we have successfully created so far. ANI systems are designed and trained to perform a single, specific task. Examples are ubiquitous: a chess program like Deep Blue, a spam filter in your email, a recommendation engine on a streaming service, or a voice assistant like Siri or Alexa. While these systems can perform their designated tasks with superhuman proficiency, they operate within a pre-defined, limited context. The AI that masters Go cannot compose music or diagnose a disease without being completely re-engineered.
- Artificial General Intelligence (AGI), or Strong AI, is the hypothetical intelligence of a machine that has the capacity to understand, learn, and apply its intelligence to solve any intellectual task that a human being can. An AGI would possess cognitive abilities like reasoning, problem-solving, abstract thinking, and learning from experience across a wide range of domains. It would not be limited to a single function. Achieving AGI is the long-term, holy-grail objective for many AI researchers, but it remains an incredibly complex challenge, with no clear path to its realization.
- Artificial Superintelligence (ASI) is a hypothetical form of AI that would surpass the brightest and most gifted human minds in virtually every field, including scientific creativity, general wisdom, and social skills. The concept, popularized by philosopher Nick Bostrom, raises profound questions about the future of humanity and the existential risks associated with creating an entity far more intelligent than ourselves.
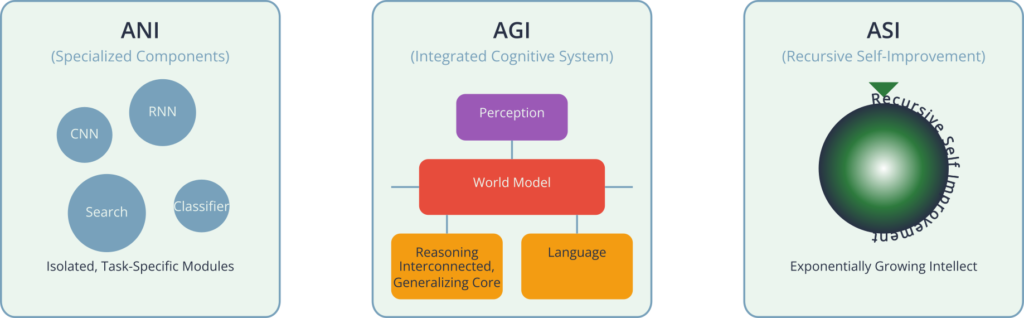
Symbolic AI and the “Good Old-Fashioned AI” (GOFAI)
The first major wave of AI research, from the 1950s to the 1980s, was dominated by an approach known as Symbolic AI, or Good Old-Fashioned AI (GOFAI). The central belief of GOFAI was that intelligence could be achieved by manipulating symbols according to a set of explicit, logical rules. The primary tools were logic programming and knowledge representation.
The quintessential example of this approach is the expert system. These systems aimed to capture the knowledge of a human expert in a specific domain (e.g., medical diagnosis, chemical analysis) and encode it into a knowledge base of “if-then” rules. An inference engine would then use these rules to reason about new data and provide solutions or recommendations. For example, a medical expert system might have a rule like: IF patient has fever AND sore throat AND white spots on tonsils, THEN diagnosis is likely strep throat.
%%{init: {'theme': 'base', 'themeVariables': { 'fontFamily': 'Open Sans'}}}%%
graph TD
A[("<b>Knowledge Base</b><br><i>(Human-coded 'IF-THEN' rules)</i>")]:::data
B[("<b>New Data / Query</b><br><i>(e.g., patient symptoms)</i>")]:::data
C{{"<b>Inference Engine</b><br><i>(Applies logical rules)</i>"}}:::process
D[("<b>Decision / Recommendation</b><br><i>(e.g., 'Likely strep throat')</i>")]:::success
A --> C
B --> C
C --> D
classDef data fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee;
classDef process fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044;
classDef success fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
While expert systems achieved some success in well-defined, static domains, they suffered from several critical limitations. The primary challenge was the knowledge acquisition bottleneck: extracting and encoding the vast, often tacit, knowledge of a human expert into formal rules is incredibly difficult, time-consuming, and expensive. Furthermore, these systems were brittle. If faced with a situation not covered by their rules, they would fail completely, lacking any ability to generalize or handle ambiguity. They could not learn from experience or adapt to new information, making them unsuitable for the messy, uncertain, and rapidly changing real world. This brittleness paved the way for a new paradigm: Machine Learning.
Machine Learning (ML): Enabling Systems to Learn from Data
Machine Learning represents a fundamental departure from the symbolic AI paradigm. Instead of a human programmer hand-crafting explicit rules, an ML system is given a large amount of data and an algorithm that allows it to learn the rules for itself. The formal definition, attributed to Tom M. Mitchell, is: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.” In essence, ML is about creating algorithms that can generalize from examples.
%%{init: {'theme': 'base', 'themeVariables': { 'fontFamily': 'Open Sans'}}}%%
graph LR
subgraph Machine Learning
direction LR
Input2[("Data / Input")]:::data
Output2[("Expected<br>Output / Labels")]:::data
MLProcess{{"<b>Machine Learning<br>Algorithm</b>"}}:::model
Program2[("Learned<br>Program / Model")]:::success
Input2 --> MLProcess
Output2 --> MLProcess
MLProcess --> Program2
end
subgraph Traditional Programming
direction LR
Input1[("Data / Input")]:::data
Program1{{"Hand-Coded<br>Program / Rules"}}:::process
Output1[("Output")]:::success
Input1 --> Program1 --> Output1
end
linkStyle 0 stroke-width:2px,fill:none,stroke:black;
linkStyle 1 stroke-width:2px,fill:none,stroke:black;
linkStyle 2 stroke-width:2px,fill:none,stroke:black;
linkStyle 3 stroke-width:2px,fill:none,stroke:black;
linkStyle 4 stroke-width:2px,fill:none,stroke:black;
classDef data fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee;
classDef process fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044;
classDef success fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
classDef model fill:#e74c3c,stroke:#e74c3c,stroke-width:1px,color:#ebf5ee;
The Core Learning Paradigms
Machine Learning is not a single technique but a collection of approaches, typically categorized into three main paradigms based on the nature of the “experience” or data provided to the learning algorithm.
- Supervised Learning: This is the most common and well-understood paradigm. The system is trained on a dataset where each data point is labeled with the correct output or “ground truth.” The algorithm’s goal is to learn a mapping function that can predict the output label for new, unseen data. The “supervision” comes from the labeled data, which acts as a teacher.
- Classification: The goal is to predict a discrete category. For example, classifying an email as “spam” or “not spam,” or identifying a handwritten digit. The model learns a decision boundary to separate the classes.
- Regression: The goal is to predict a continuous value. For example, predicting the price of a house based on its features (size, location, age) or forecasting a company’s stock price. The model learns a line or curve that best fits the data.The core of supervised learning involves minimizing a loss function (or cost function), which measures the discrepancy between the model’s predictions and the actual labels. An optimization algorithm, such as Gradient Descent, iteratively adjusts the model’s internal parameters to reduce this loss.
- Unsupervised Learning: In this paradigm, the system is given a dataset with no labels. The algorithm’s task is to find hidden patterns, structures, or relationships within the data on its own. It’s about data exploration and discovery.
- Clustering: The goal is to group similar data points together into clusters. For example, segmenting customers into different purchasing behavior groups or grouping related news articles. Algorithms like K-Means try to minimize the distance between points within a cluster while maximizing the distance between clusters.
- Dimensionality Reduction: The goal is to reduce the number of variables (features) in a dataset while preserving its important structural information. This is useful for data visualization and for improving the performance of other ML models by removing noise. Principal Component Analysis (PCA) is a classic technique.
- Association Rule Mining: This discovers interesting relationships between variables in large databases. A famous example is “market basket analysis,” which might find that customers who buy diapers are also likely to buy beer.
- Reinforcement Learning (RL): This paradigm is inspired by behavioral psychology and is concerned with how an agent should take actions in an environment to maximize a cumulative reward. The agent learns through trial and error. It receives positive rewards for desirable actions and negative rewards (or penalties) for undesirable ones. Unlike supervised learning, there are no “correct” labels for each action; the feedback is often delayed and evaluative. The goal is to learn a policy—a mapping from states of the environment to actions—that maximizes the total expected reward over time. RL is the powerhouse behind game-playing AIs like AlphaGo and is increasingly used in robotics, resource management, and autonomous control systems.
%%{init: {'theme': 'base', 'themeVariables': { 'fontFamily': 'Open Sans'}}}%%
graph LR
subgraph Reinforcement Learning
direction LR
A3[("<b>Agent</b>")]:::model -- "Action" --> B3{"<b>Environment</b>"}:::process
B3 -- "Reward / Penalty" --> A3
B3 -- "New State" --> A3
A3 --> C3[("<b>Goal:</b><br>Maximize Cumulative Reward")]:::success
end
subgraph Unsupervised Learning
direction LR
A2[("<b>Input:</b><br>Unlabeled Data<br><i>(e.g., customer data)</i>")]:::data --> B2{{"<b>Goal:</b> Find Structure<br><i>(e.g., clusters, patterns)</i>"}}:::model --> C2[("<b>Output:</b><br>Grouped Data<br><i>(e.g., customer segments)</i>")]:::success
end
subgraph Supervised Learning
direction LR
A1[("<b>Input:</b><br>Labeled Data<br><i>(e.g., image, 'cat')</i>")]:::data --> B1{{"<b>Goal:</b> Learn Mapping<br><i>f(input) -> output</i>"}}:::model --> C1[("<b>Output:</b><br>Prediction<br><i>(e.g., 'cat' or 'dog')</i>")]:::success
end
classDef data fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee;
classDef model fill:#e74c3c,stroke:#e74c3c,stroke-width:1px,color:#ebf5ee;
classDef success fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
classDef process fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044;
The Machine Learning Workflow: A Practitioner’s View
Developing a successful ML model is not just about choosing an algorithm. It’s a systematic, iterative process. A typical workflow includes:
%%{init: {'theme': 'base', 'themeVariables': { 'fontFamily': 'Open Sans'}}}%%
graph TD
A[("<b>1- Problem Definition</b><br>& Data Collection")]:::start --> B{"2- Data Preprocessing<br>& Cleaning"};
B --> C{{"3- Feature Engineering<br><i>(Critical for Classic ML)</i>"}};
C --> D[("4- Model Selection<br><i>e.g., Random Forest, CNN</i>")]:::model;
D --> E((5- Model Training));
E --> F{6- Model Evaluation<br><i>Using Test Set</i>};
F -- "Not Good Enough" --> G{"7- Parameter Tuning<br><i>Adjust Hyperparameters</i>"};
G --> E;
F -- "Good Enough" --> H[("8- Deployment<br><i>Integrate into Production</i>")]:::success;
H --> I((9- Monitoring &<br>Maintenance));
I -- "Model Drift Detected" --> A;
classDef start fill:#283044,stroke:#283044,stroke-width:2px,color:#ebf5ee;
classDef process fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044;
classDef model fill:#e74c3c,stroke:#e74c3c,stroke-width:1px,color:#ebf5ee;
classDef decision fill:#f39c12,stroke:#f39c12,stroke-width:1px,color:#283044;
classDef success fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
class B,C,E,G,I process;
class F decision;
- Problem Definition & Data Collection: Clearly defining the task (T) and the performance metric (P). Sourcing and gathering relevant data.
- Data Preprocessing & Cleaning: Handling missing values, correcting inconsistencies, and formatting data for the model. This is often the most time-consuming step.
- Feature Engineering: This is a critical and creative step in classic ML. It involves selecting, transforming, and creating the most relevant input variables (features) from the raw data to improve model performance. For example, from a date field, one might engineer features like “day of the week” or “is_holiday.”
- Model Selection: Choosing a suitable algorithm (e.g., Linear Regression, Decision Tree, Support Vector Machine) based on the problem type, data size, and interpretability requirements.
- Model Training: Feeding the prepared data to the selected algorithm to learn the underlying patterns. This involves splitting the data into training, validation, and test sets.
- Model Evaluation: Assessing the model’s performance on the unseen test set using the pre-defined metric (P). This step checks for issues like overfitting (the model performs well on training data but poorly on new data) or underfitting.
- Parameter Tuning: Adjusting the model’s hyperparameters (settings that are not learned from the data, like the learning rate in Gradient Descent) to optimize performance.
- Deployment & Monitoring: Integrating the trained model into a production environment where it can make predictions on live data. It’s crucial to monitor its performance over time as data distributions can shift (a phenomenon known as model drift).
Deep Learning (DL): The Neural Network Renaissance
Deep Learning is not a separate field from Machine Learning; rather, it is a highly successful and powerful subfield of ML. It utilizes a specific class of algorithms: deep artificial neural networks. The “deep” refers to the use of multiple layers in the network, allowing it to learn complex patterns and representations directly from data. The resurgence of neural networks, an idea that has been around for decades, was made possible by the confluence of three key factors in the early 2010s: the availability of massive datasets (Big Data), the development of powerful parallel processing hardware (especially GPUs), and algorithmic improvements.
The Biological Inspiration: From Neurons to Artificial Neural Networks (ANNs)
The fundamental building block of a neural network is the artificial neuron, or perceptron, a concept loosely inspired by the biological neurons in the human brain. A neuron receives one or more inputs, computes a weighted sum of these inputs, adds a bias, and then passes the result through a non-linear activation function. This function determines the neuron’s output, deciding whether and to what extent it “fires.”
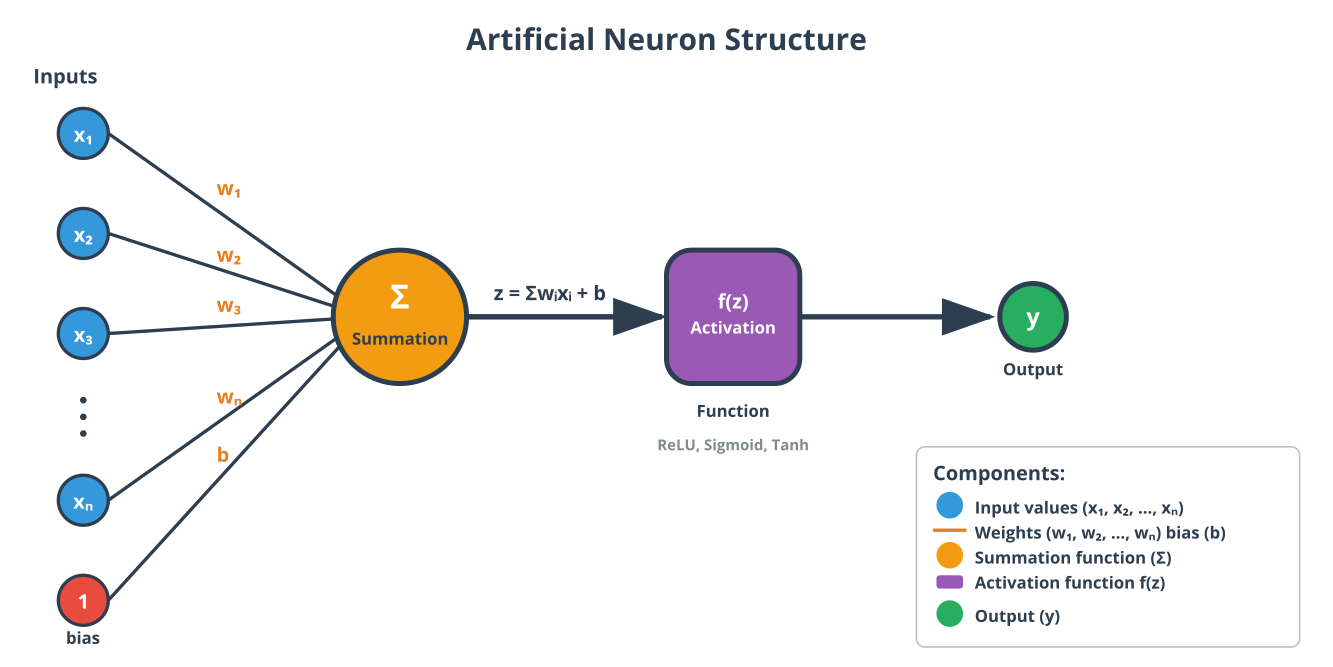
An Artificial Neural Network (ANN) is formed by organizing these neurons into layers: an input layer that receives the raw data, one or more hidden layers that perform the computations, and an output layer that produces the final prediction. In a simple feedforward network, information flows in one direction, from the input layer through the hidden layers to the output layer.
Activation Functions Comparison
| Activation Function | Formula | Output Range | Pros | Cons |
|---|---|---|---|---|
| Sigmoid | 1 / (1 + e⁻ˣ) | (0, 1) | Smooth gradient, clear predictions for probability. | Vanishing gradient problem, output is not zero-centered. |
| Tanh (Hyperbolic Tangent) | (eˣ – e⁻ˣ) / (eˣ + e⁻ˣ) | (-1, 1) | Zero-centered output, which helps in optimization. | Still suffers from the vanishing gradient problem. |
| ReLU (Rectified Linear Unit) | max(0, x) | [0, ∞) | Computationally efficient, avoids vanishing gradients for positive values. | “Dying ReLU” problem (neurons can become inactive), not zero-centered. |
| Leaky ReLU | max(αx, x) for small α>0 | (-∞, ∞) | Fixes the “Dying ReLU” problem, faster computation. | Results are not always consistent; choice of α can be an issue. |
| Softmax | eˣᵢ / Σ(eˣⱼ) | (0, 1) | Outputs a probability distribution, ideal for multi-class classification output layers. | Typically used only in the final layer, not in hidden layers. |
The “Deep” in Deep Learning: The Power of Hierarchy and Representation Learning
What distinguishes a “deep” neural network from a “shallow” one is the presence of multiple hidden layers (though the exact number is not strictly defined, typically more than one or two). The magic of depth lies in its ability to perform hierarchical representation learning. Each layer learns to transform its input data into a slightly more abstract and composite representation.
Consider an image classification task.
- The first hidden layer might learn to detect simple features like edges, corners, and color blobs from the raw pixel data.
- The second hidden layer would take these edge and blob features as input and learn to combine them into more complex features, like eyes, noses, or textures.
- A third hidden layer might combine those features to recognize even more complex objects, like facial structures or car wheels.
- The final output layer then takes these high-level representations and makes a classification decision (e.g., “this is a cat” or “this is a car”).
This hierarchical process is the core strength of Deep Learning. It automates the feature engineering step, which was a laborious and critical part of the classic ML workflow. The network learns the optimal features directly from the data, making it exceptionally powerful for complex, unstructured data types like images, audio, and text, where manually defining features is nearly impossible

Key Architectures and Their Domains
Deep Learning is not a one-size-fits-all solution. Different neural network architectures have been developed to excel at different types of tasks and data.
- Convolutional Neural Networks (CNNs): These are the workhorses of computer vision. CNNs use a special type of layer called a convolutional layer, which applies filters to an input image to create feature maps. This allows the network to learn spatial hierarchies of features in a way that is translation-invariant (it can recognize an object regardless of where it appears in the image). They are used in image classification, object detection, and medical image analysis.
- Recurrent Neural Networks (RNNs): These are designed to work with sequential data, such as time series or natural language. RNNs have “loops” in them, allowing information to persist. This internal memory lets the network use the context of previous inputs in a sequence to inform its processing of the current input. They are used in machine translation, speech recognition, and sentiment analysis. However, standard RNNs suffer from the vanishing gradient problem, making it hard to learn long-range dependencies. Variants like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) were developed to address this.
- Transformers: Introduced in the 2017 paper “Attention Is All You Need,” the Transformer architecture has revolutionized natural language processing (NLP) and is now being applied to other domains like computer vision. Instead of processing data sequentially like an RNN, Transformers use a mechanism called self-attention to weigh the importance of different words in the input sequence simultaneously. This allows for much greater parallelization and has enabled the creation of massive pre-trained models like BERT and GPT (Generative Pre-trained Transformer), which have achieved state-of-the-art results on a wide array of language tasks.
Conceptual Framework and Analysis
Understanding the technical definitions is the first step. The next is to internalize the relationships, trade-offs, and conceptual boundaries between AI, ML, and DL. This framework is essential for making sound engineering decisions.
The Hierarchical Relationship: AI as the Superset
The most effective way to visualize the relationship is as a set of concentric circles or Russian nesting dolls.
%%{init: {'theme': 'base', 'themeVariables': { 'fontFamily': 'Open Sans'}}}%%
graph TD
subgraph AI [Artificial Intelligence]
direction TB
subgraph ML [Machine Learning]
direction TB
subgraph DL [Deep Learning]
DL_Node[("<b>Deep Learning</b><br><i>e.g., CNNs, Transformers</i><br>Automates feature learning from raw data.")]
end
ML_Node[("<b>Machine Learning</b><br><i>e.g., SVM, Random Forest</i><br>Algorithms that learn patterns from data.")]
end
AI_Node[("<b>Artificial Intelligence</b><br><i>e.g., Expert Systems, Robotics</i><br>The broad concept of creating intelligent machines.")]
end
style AI fill:#283044,stroke:#283044,stroke-width:2px,color:#ebf5ee
style ML fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044
style DL fill:#e74c3c,stroke:#e74c3c,stroke-width:1px,color:#ebf5ee
- Artificial Intelligence (AI) is the all-encompassing universe of creating intelligent machines. This includes everything from the symbolic logic of GOFAI to the data-driven approaches of ML and DL, as well as fields like robotics, planning, and knowledge representation. Any system that reasons, learns, or acts rationally can be considered AI.
- Machine Learning (ML) is a subset of AI. It is a specific approach to achieving AI, one that focuses on algorithms that learn from data. Not all AI is ML. An old-school expert system is a form of AI, but it does not learn from data, so it is not ML.
- Deep Learning (DL) is a further subset of Machine Learning. It is a specialized technique within ML that uses a particular type of algorithm (deep neural networks). Therefore, every deep learning system is a machine learning system, and by extension, an AI system. However, not all ML is DL. A simple linear regression model or a decision tree is a classic ML algorithm but does not involve deep neural networks.
This hierarchy clarifies the terminology: it is correct to call a deep learning-based image classifier an “AI system,” but it is more specific and informative to call it a “deep learning model.” The choice of term often depends on the context and the desired level of technical detail.
Comparative Analysis: When to Use Which Approach
Choosing between symbolic AI, classic ML, and deep learning is a critical architectural decision that depends on the specific problem constraints. There is no single “best” approach; each has its strengths and weaknesses.
Comparative Analysis of AI Approaches
| Criterion | Symbolic AI (e.g., Expert System) | Classic Machine Learning (e.g., SVM, Random Forest) | Deep Learning (e.g., CNN, Transformer) |
|---|---|---|---|
| Data Requirements | Low (relies on human-coded rules) | Moderate to Large (works well with hundreds to thousands of data points) | Very Large (often requires millions of data points to perform well) |
| Computational Cost | Low (inference is typically fast) | Low to Moderate (training is feasible on a standard CPU) | Very High (training often requires specialized hardware like GPUs or TPUs) |
| Interpretability | High (“White Box”). The reasoning process is transparent and traceable. | Moderate to High. Models like decision trees are easy to interpret. Others are less so. | Very Low (“Black Box”). Understanding why a deep network made a specific decision is a major research challenge. |
| Feature Engineering | N/A (relies on a knowledge base) | High. Requires significant domain expertise to manually create effective features. | Low to None. The model learns features automatically from raw data. |
| Performance on Unstructured Data (Images, Text) | Poor. Not designed for perceptual tasks. | Moderate. Can work if clever features are engineered, but often struggles. | Excellent. State-of-the-art performance on these tasks. |
| Performance on Structured/Tabular Data | Can be effective if rules are clear. | Excellent. Often outperforms deep learning on small-to-medium sized tabular datasets. | Good, but can be overkill and may not outperform classic models without careful tuning. |
| Development Time | High (due to knowledge acquisition bottleneck) | Moderate (dominated by feature engineering and tuning) | High (dominated by data collection, training time, and hyperparameter tuning) |
Note: The lines are blurring. Fields like Explainable AI (XAI) are actively working to pry open the “black box” of deep learning. Similarly, hybrid models that combine symbolic reasoning with deep learning are a promising area of research, aiming to get the best of both worlds: the pattern-recognition power of DL and the reasoning capabilities of symbolic AI.
Conceptual Scenarios: Deconstructing AI Systems
Let’s apply this framework to understand real-world systems.
Scenario 1: A Streaming Service’s Recommendation Engine
- The AI System: The entire platform feature that suggests movies and shows you might like is an AI system. Its goal is to act rationally by maximizing user engagement and retention.
- The Machine Learning Component: How does it achieve this? Not with hand-coded rules like
IF user watched 'The Matrix' THEN recommend 'Blade Runner'. Instead, it uses Machine Learning. A common approach is collaborative filtering, an algorithm that analyzes a massive user-item interaction matrix (which users watched/rated which movies). It learns patterns, such as “users who liked movie A and B also tended to like movie C.” This is a classic ML task. - The Deep Learning Potential: A more advanced version of this engine might use Deep Learning to create rich, dense vector representations (called embeddings) of both users and movies. The network could learn these embeddings from raw data like movie synopses, genres, cast information, and user viewing histories. By representing users and movies in a shared “taste space,” the system can make more nuanced recommendations than classic collaborative filtering. This DL model is still an ML model, which is part of the larger AI system.
%%{init: {'theme': 'base', 'themeVariables': { 'fontFamily': 'Open Sans'}}}%%
graph TD
subgraph Inputs
A[("<b>User Data</b><br>- Watch History<br>- Ratings<br>- Clicks")]:::data
B[("<b>Item Data</b><br>- Movie Genres<br>- Cast / Crew<br>- Synopsis Text")]:::data
end
subgraph "ML Model"
C{{"<b>Collaborative Filtering /<br>Deep Learning Embedding Model</b>"}}:::model
end
subgraph Output
D[("<b>Personalized Recommendations</b><br><i>'Movies You Might Like'</i>")]:::success
end
A --> C
B --> C
C --> D
classDef data fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee;
classDef model fill:#e74c3c,stroke:#e74c3c,stroke-width:1px,color:#ebf5ee;
classDef success fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
Scenario 2: An Autonomous Vehicle
- The AI System: The entire self-driving car is a complex AI system, specifically a rational agent. Its overarching goal is to navigate from a starting point to a destination safely and efficiently.
- The Machine Learning Components: This AI system is not a single model but an orchestra of many ML models working in concert.
- Perception: To understand its surroundings, the car uses Deep Learning. CNNs process input from cameras to perform object detection (identifying other cars, pedestrians, traffic lights) and semantic segmentation (labeling every pixel in an image as “road,” “sidewalk,” “building,” etc.).
- Prediction: Once objects are identified, the system needs to predict their future behavior. Will that car change lanes? Will that pedestrian step into the street? This might be handled by classic ML or DL models (like LSTMs) trained on vast datasets of traffic scenarios.
- Planning: Given the current state of the world and predictions about its future, the car must decide on a trajectory (steering, acceleration, braking). This decision-making process is often formulated as a Reinforcement Learning problem, where the agent (the car) learns a policy to maximize rewards (e.g., for reaching the destination) while avoiding penalties (e.g., for collisions or traffic violations).
%%{init: {'theme': 'base', 'themeVariables': { 'fontFamily': 'Open Sans'}}}%%
graph TD
A[("<b>Sensor Inputs</b><br>Cameras, LiDAR, Radar")]:::data --> B{"<b>Perception</b><br><i>(CNNs for Object Detection /<br>Semantic Segmentation)</i>"}:::model;
B --> C{"<b>Prediction</b><br><i>(LSTMs to forecast<br>object movement)</i>"}:::model;
C --> D{"<b>Planning</b><br><i>(RL to decide trajectory<br>and behavior)</i>"}:::model;
D --> E[("<b>Control Actions</b><br>Steer, Accelerate, Brake")]:::success;
classDef data fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee;
classDef model fill:#e74c3c,stroke:#e74c3c,stroke-width:1px,color:#ebf5ee;
classDef success fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
Scenario 3: A Spam Filter
- The AI System: The feature in your email client that automatically moves junk mail to a spam folder is a simple but effective AI system.
- The Machine Learning Component: Early spam filters used hand-coded rules (e.g.,
IF email contains "viagra" THEN mark as spam). These were brittle and easily circumvented. Modern filters use Machine Learning. A common approach is to use a Naive Bayes classifier or a Support Vector Machine (SVM)—both classic ML algorithms. The model is trained on a large corpus of emails labeled as “spam” or “not spam.” - The Feature Engineering: For a classic ML approach, a crucial step is feature engineering. The system would convert the text of an email into a vector of features, such as the frequency of certain words (“free,” “prize,” “winner”), the presence of all-caps text, or the number of exclamation points.
- The Deep Learning Alternative: A more sophisticated filter could use a DL model (like an RNN or Transformer) to read the email text directly. The DL model would learn the relevant features on its own, potentially capturing more subtle linguistic patterns indicative of spam than a human could engineer. This would likely offer higher accuracy but at the cost of greater computational complexity and less direct interpretability.
Industry Applications and Case Studies
The distinctions between AI, ML, and DL are not just theoretical; they define the capabilities and limitations of real-world business solutions.
- Healthcare: Medical Imaging Analysis
- Application: Using AI to detect diseases like cancer from medical scans (X-rays, CT scans, MRIs).
- Implementation: This is a prime application for Deep Learning, specifically Convolutional Neural Networks (CNNs). A CNN can be trained on thousands of labeled images (e.g., scans with and without tumors) to learn the subtle visual patterns that indicate malignancy, often with accuracy rivaling or exceeding human radiologists.
- Business Value: Early and more accurate diagnosis, reduced workload for radiologists, and improved patient outcomes. The technical challenge lies in acquiring large, high-quality, and properly labeled datasets while adhering to strict patient privacy regulations like HIPAA.
- Finance: Algorithmic Trading and Fraud Detection
- Application: Building systems to detect fraudulent credit card transactions in real-time.
- Implementation: This is often a domain for classic Machine Learning. Models like Random Forests or Gradient Boosted Trees are highly effective on the structured, tabular data typical of financial transactions (transaction amount, time, location, merchant type). These models are relatively fast to train and deploy, and their interpretability is a major advantage for regulatory compliance, as banks often need to explain why a transaction was flagged.
- Business Value: Minimizing losses from fraud, protecting customers, and maintaining trust. The key challenge is dealing with highly imbalanced datasets (fraudulent transactions are rare) and adapting to the constantly evolving tactics of fraudsters.
- Retail & E-commerce: Demand Forecasting
- Application: Predicting future product sales to optimize inventory management, reduce waste, and prevent stockouts.
- Implementation: This problem involves time-series data and can be tackled by both classic ML and DL. Classic ML methods like ARIMA or Prophet are often used as strong baselines. However, for complex scenarios with many products and external factors (promotions, holidays, weather), Deep Learning models like LSTMs can capture more intricate temporal dependencies and non-linear relationships, leading to more accurate forecasts.
- Business Value: Increased profitability through reduced inventory holding costs and lost sales. The challenge is creating a robust system that can handle thousands of individual product forecasts and incorporate a wide variety of influencing factors.
Best Practices and Common Pitfalls
Navigating the AI/ML/DL landscape requires not just technical skill but also a strategic mindset.
- Start with the Simplest Model: Don’t jump to deep learning just because it’s powerful. Always begin with a simple, interpretable baseline model (like linear regression or a decision tree). If it performs “good enough” for your business problem, you might not need the complexity, cost, and “black box” nature of a deep neural network. This is a core principle of Occam’s Razor applied to machine learning.
- Data Quality over Model Complexity: The performance of any ML or DL system is fundamentally capped by the quality of its data. Garbage in, garbage out. Spending time on data cleaning, preprocessing, and understanding your data distribution will almost always yield a better return on investment than tweaking a complex model architecture.
- Understand the “Why” (Interpretability): For high-stakes decisions (e.g., loan applications, medical diagnoses, legal systems), a model that is 99% accurate but uninterpretable may be less useful or even dangerous than a model that is 95% accurate but fully transparent. Choose your approach based on the required level of trust and accountability. Classic ML often wins here.
- Feature Engineering is Still Relevant: While deep learning automates feature learning, it doesn’t make feature engineering obsolete. For tabular data, well-crafted features can significantly boost the performance of even simple models. Furthermore, understanding what makes a good feature provides invaluable domain insight.
- Beware of Hype Cycles: The field of AI is prone to hype. It’s crucial to distinguish between genuine technological breakthroughs and marketing buzz. A solid understanding of the fundamentals of AI, ML, and DL provides the best defense against adopting inappropriate or unproven technologies.
- Focus on the Full MLOps Lifecycle: A model is not a project; it’s a product. Success in AI engineering requires thinking beyond just training the model. You must consider data pipelines, automated retraining, deployment strategies, performance monitoring, and model versioning—the entire field of MLOps (Machine Learning Operations).
Hands-on Exercises
These exercises are designed to reinforce the conceptual distinctions without requiring extensive coding.
- System Classification (Individual):
- Objective: To practice identifying the correct classification for various systems.
- Task: For each of the following systems, classify it as: (a) Symbolic AI (Not ML), (b) Classic ML (Not DL), or (c) Deep Learning. Justify your answer in one or two sentences, referencing concepts like learning from data, feature engineering, and neural networks.
- A GPS navigation system that uses Dijkstra’s algorithm to find the shortest path.
- A system that predicts customer churn based on their age, subscription plan, and monthly bill, using a logistic regression model.
- A mobile app that can identify a species of plant from a photo taken by the user.
- A tax preparation software that fills out forms based on a series of questions answered by the user.
- Problem-Approach Matching (Individual or Group):
- Objective: To apply the comparative analysis framework to select an appropriate technical approach.
- Task: You are a consultant for a startup. They have three project ideas. For each one, recommend whether they should start with a classic ML approach or a deep learning approach. Justify your recommendation based on data type, expected data volume, need for interpretability, and likely performance.
- Project A: A tool to predict house prices for a single city using a dataset of 5,000 past sales with features like square footage, number of bedrooms, and neighborhood.
- Project B: A voice assistant for a new smart speaker that needs to understand and respond to spoken commands in natural language.
- Project C: A system for a hospital to predict the likelihood of a patient developing sepsis based on 50 structured variables from their electronic health record (e.g., heart rate, white blood cell count, temperature).
- Deconstructing an AI Product (Group):
- Objective: To analyze a complex, real-world AI product and identify its components.
- Task: Choose a popular AI-powered product (e.g., Spotify’s Discover Weekly, Google Translate, a video game with intelligent NPCs). As a group, create a presentation or document that deconstructs the product.
- What is the overall AI goal of the product?
- Identify at least two distinct Machine Learning tasks the system likely performs (e.g., classification, clustering, prediction).
- For each ML task, speculate on whether it is more likely implemented with classic ML or Deep Learning, and what specific architectures (e.g., CNN, Transformer) might be used. Justify your reasoning.
Tools and Technologies
The choice of software tools often reflects the conceptual layer at which you are working.
- General AI (Symbolic): While less common now for mainstream applications, languages like Lisp and Prolog were historically dominant in symbolic AI research. Modern applications might use specialized libraries for logic programming or planning.
- Classic Machine Learning: The undisputed king of this domain is Scikit-learn for Python. It provides a clean, consistent API for a vast array of pre-processing tools and classic ML algorithms, including regression, classification, and clustering models. For data manipulation and analysis, Pandas and NumPy are indispensable.
- Deep Learning: The DL ecosystem is dominated by two major frameworks:
- TensorFlow (Google): A powerful and flexible framework with a strong production focus, particularly through its high-level API, Keras. Keras makes building and training deep neural networks remarkably straightforward. (Current version: TensorFlow 2.15+)
- PyTorch (Meta): Known for its flexibility, “Pythonic” feel, and strong support in the research community. It provides a more imperative programming style, which many researchers and developers find intuitive for rapid prototyping and complex model design.
- The Broader Ecosystem: Tools like Jupyter Notebooks are essential for experimentation and visualization. Cloud platforms like AWS SageMaker, Google AI Platform, and Azure Machine Learning provide managed services for the entire MLOps lifecycle, from data labeling to model deployment and monitoring at scale.
Major Cloud ML Platforms Overview
| Cloud Provider | Primary MLOps Platform | Key Pre-trained APIs | AutoML Service |
|---|---|---|---|
| Amazon Web Services (AWS) | Amazon SageMaker | Rekognition (Vision), Polly (Text-to-Speech), Comprehend (NLP), Translate | SageMaker Autopilot |
| Google Cloud Platform (GCP) | Vertex AI | Vision AI, Speech-to-Text, Natural Language AI, Translation AI | Vertex AI AutoML |
| Microsoft Azure | Azure Machine Learning | Cognitive Services (Vision, Speech, Language, Decision) | Azure Automated ML |
Summary
- AI is the broadest field, encompassing the entire concept of creating intelligent machines that can reason and act.
- Machine Learning is a subfield of AI that focuses on a specific approach: enabling systems to learn patterns from data without being explicitly programmed.
- Deep Learning is a subfield of Machine Learning that uses a specific technique—deep artificial neural networks with many layers—to learn complex, hierarchical representations from data.
- The progression from AI to ML to DL represents a move from explicitly coded logic to learned rules to automated feature learning.
- The choice between classic ML and DL is a critical engineering decision involving a trade-off between performance on unstructured data, data/compute requirements, and model interpretability.
- Understanding this hierarchy is fundamental for any AI engineer to effectively design, communicate, and build modern intelligent systems.
Further Reading and Resources
- Russell, S., & Norvig, P. (2020). Artificial Intelligence: A Modern Approach (4th ed.). The definitive university textbook on AI, covering the breadth of the field from symbolic logic to modern machine learning.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. The foundational textbook on deep learning, written by three of the field’s pioneers. Available online for free.
- Google AI Blog & Meta AI Blog: Authoritative sources for the latest research and applications coming directly from the teams behind TensorFlow and PyTorch. https://cloud.google.com/blog/products/ai-machine-learning
- Distill.pub: An online academic journal known for outstanding articles that clarify and visualize machine learning concepts with exceptional clarity. https://distill.pub
- Papers with Code: A fantastic resource for discovering the latest state-of-the-art ML/DL models, linking research papers to their corresponding open-source code implementations on GitHub. https://github.com/paperswithcode
- Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow by Aurélien Géron: An excellent, practical book that bridges theory and implementation for both classic ML and deep learning.
Glossary of Terms
- Artificial Intelligence (AI): The broad scientific field dedicated to creating machines or software that exhibit intelligent behavior.
- Artificial Neural Network (ANN): A computing system inspired by biological neural networks. It’s the foundational structure for deep learning.
- Deep Learning (DL): A subfield of machine learning based on artificial neural networks with multiple hidden layers (deep architectures).
- Expert System: A classic AI program that uses a knowledge base of human-coded rules and an inference engine to solve problems in a specific domain. A form of Symbolic AI.
- Feature Engineering: The process of using domain knowledge to create input variables (features) for a machine learning algorithm. Largely automated by deep learning.
- Machine Learning (ML): A subfield of AI that gives computers the ability to learn from data without being explicitly programmed.
- MLOps (Machine Learning Operations): A set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently.
- Reinforcement Learning (RL): A paradigm of machine learning where an agent learns to make decisions by taking actions in an environment to maximize a cumulative reward.
- Supervised Learning: A paradigm of machine learning where the algorithm learns from a dataset containing labeled examples (i.e., each data point has a correct output).
- Symbolic AI / GOFAI: The “Good Old-Fashioned AI” approach, which is based on the belief that intelligence can be achieved by manipulating symbols according to explicit logical rules.
- Unsupervised Learning: A paradigm of machine learning where the algorithm learns from an unlabeled dataset, finding patterns and structure on its own.
