
Chapter 42: Data Versioning and Experiment Tracking
Chapter Objectives
Upon completing this chapter, students will be able to:
- Understand the fundamental principles of data versioning and experiment tracking and articulate why they are critical for reproducible and scalable AI systems.
- Analyze the limitations of traditional version control systems like Git for managing large datasets and model artifacts in machine learning workflows.
- Implement conceptual workflows for versioning data and tracking experiments using the architectural principles of tools like DVC and MLflow.
- Design a robust MLOps strategy that integrates data versioning, experiment tracking, and code version control to ensure full pipeline provenance and auditability.
- Evaluate and compare different tools and methodologies for data versioning and experiment management based on project requirements, team size, and infrastructure constraints.
- Optimize machine learning development cycles by leveraging versioning and tracking to facilitate collaboration, debug model performance issues, and streamline deployment.
Introduction
In the landscape of modern software engineering, version control systems like Git are the undisputed foundation for collaboration, reproducibility, and stability. However, the unique artifacts of machine learning—vast datasets, multi-gigabyte model files, and an endless stream of experimental results—shatter the assumptions upon which these code-centric tools were built. The failure to systematically manage these components gives rise to the “reproducibility crisis” in AI, where even the original creators of a model struggle to replicate their results weeks or months later. This chapter confronts this challenge directly, introducing the critical disciplines of data versioning and experiment tracking as foundational pillars of professional AI engineering.
We will explore how the inability to answer questions like “What exact dataset was this model trained on?” or “Which set of hyperparameters produced our best-performing result?” introduces significant business risk, hinders collaboration, and makes regulatory compliance nearly impossible. This chapter moves beyond theory to dissect the architectural principles and conceptual frameworks that enable robust MLOps practices. We will examine how tools like Data Version Control (DVC) extend the familiar paradigms of Git to handle large data assets without bloating repositories, and how platforms like MLflow provide a structured system for logging, querying, and visualizing the complex web of experiments that define a modern AI project. By the end of this chapter, you will not only grasp the theoretical necessity of these practices but also understand how to design and implement workflows that bring discipline, auditability, and velocity to the art of building intelligent systems.
Technical Background
The Reproducibility Imperative in Machine Learning
The scientific method is predicated on the principle of reproducibility: the ability for an independent researcher to replicate an experiment and obtain the same results. In computational fields, this has historically been interpreted as sharing the source code. However, modern machine learning introduces a third critical component beyond logic (code) and compute environment: data. A machine learning model is not merely an algorithmic artifact; it is the deterministic output of a function \( f(\text{code}, \text{data}, \text{hyperparameters}) \). Any variation in these inputs will produce a different result. The failure to version all three components is the primary driver of the reproducibility crisis in AI.
Consider a production model for fraud detection that experiences a sudden drop in accuracy. Without a rigorous versioning and tracking system, debugging becomes a forensic nightmare. Was the model retrained on a new batch of data that contained corrupted features? Did a developer tweak a learning rate during a late-night experiment and accidentally push the resulting model to production? Was the feature engineering script modified, subtly changing the data distribution? Without definitive answers, teams are left with guesswork, leading to extended outages and loss of revenue. This is not a purely academic concern; in regulated industries such as finance (credit scoring) and healthcare (diagnostic imaging), the inability to provide a complete audit trail—the exact data, code, and parameters used to train a deployed model—can have severe legal and financial consequences. Data versioning and experiment tracking are therefore not optional “nice-to-haves”; they are essential infrastructure for risk management and professional engineering rigor.
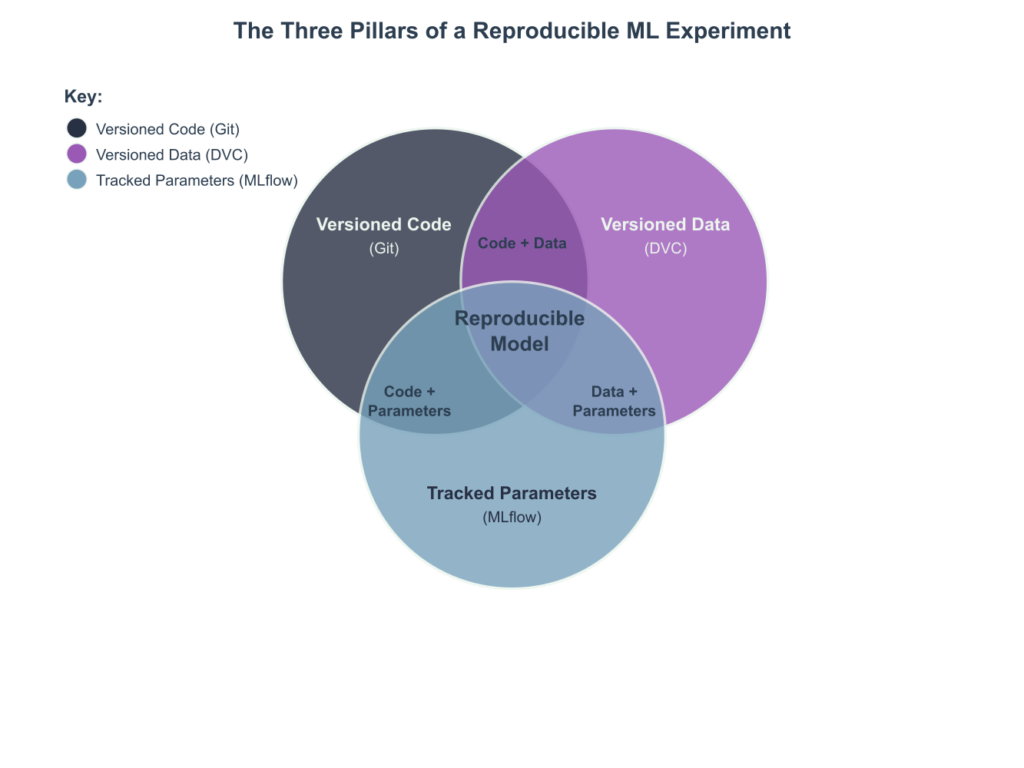
The challenge is fundamentally one of scale and complexity. A single project may involve dozens of datasets, hundreds of feature engineering variations, and thousands of experimental runs. Manually tracking these dependencies using spreadsheets and ad-hoc naming conventions (model_final_v2_really_final.pkl) is untenable. It creates a system brittle to human error and opaque to new team members. The principles discussed in this chapter provide a systematic, automated framework for capturing this information, transforming the chaotic, artisanal process of model development into a disciplined, industrial-grade engineering workflow.
Limitations of Traditional Version Control for AI
Git, the cornerstone of modern software development, was brilliantly designed for managing text-based source code. Its internal data model, based on snapshots of a project’s directory, is highly efficient for tracking line-by-line changes in files that are typically measured in kilobytes. However, this same design becomes a critical liability when applied to the artifacts of machine learning. The core issue lies in how Git stores history. Every time a large file (like a dataset or a model binary) is modified, Git does not store the “diff” or change; it stores a complete new copy of that file.
Imagine a 10 GB dataset. If a data scientist adds a single column and commits the change, the .git repository does not grow by a few kilobytes; it grows by another 10 GB. Over a few iterations of data cleaning and feature engineering, the repository size can balloon to hundreds of gigabytes, making simple operations like git clone or git checkout prohibitively slow and expensive. This fundamental mismatch renders Git unusable as a primary tool for versioning the non-code assets of an AI project.
Several early workarounds emerged, each with significant drawbacks. Git LFS (Large File Storage) was a notable improvement. It works by storing large files on a separate remote server and placing lightweight text pointers in the Git repository. When a user checks out a branch, Git LFS downloads the specific versions of the large files referenced by the pointers. While this solves the repository bloat problem, Git LFS is a generic solution for large files, not a specialized tool for ML workflows. It lacks understanding of ML pipelines, data lineage, or the relationship between data and the code that processes it. It cannot, for instance, tell you which version of a feature engineering script produced a specific version of your training data. It simply versions the files in isolation, leaving the crucial connective tissue of the ML workflow untracked. Other naive approaches, such as storing data in cloud storage buckets with manual versioning enabled (e.g., S3 versioning), suffer from a similar, and more severe, disconnect from the codebase and the experimental context.
Note: The core limitation stems from Git’s snapshot-based architecture for binary files. For a 1GB file, a 1-byte change results in a new 1GB object being stored in Git’s object database, leading to exponential repository growth. This is fundamentally different from how it handles text, where it can efficiently store diffs.
Principles of Data Versioning with DVC
To address the shortcomings of traditional tools, systems like Data Version Control (DVC) were created. DVC is not a replacement for Git but rather an elegant layer that works on top of it. The core philosophy of DVC is to separate the storage of large files from the versioning of their metadata. It allows you to use Git to version everything—code, metadata, and pipeline definitions—while delegating the storage of large data and model files to a more suitable backend, such as an S3 bucket, Google Cloud Storage, an SSH server, or even a local directory.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#283044', 'primaryTextColor': '#ebf5ee', 'lineColor': '#78a1bb', 'textColor': '#283044'}}}%%
sequenceDiagram
actor User
participant Git
participant DVC
participant RemoteStorage as Remote Storage (S3, GCS)
User->>Git: git checkout feature-branch
activate Git
Git-->>User: Updates code files and <br> .dvc metafiles
deactivate Git
User->>DVC: dvc checkout
activate DVC
DVC->>DVC: Reads hash from .dvc metafile
DVC->>RemoteStorage: Request data file with hash
activate RemoteStorage
RemoteStorage-->>DVC: Returns data file
deactivate RemoteStorage
DVC->>User: Places correct data file <br> in workspace
deactivate DVC
How DVC Works: Content-Addressing and Metafiles
The genius of DVC lies in its use of content-addressable storage. When you tell DVC to track a file or directory (e.g., dvc add data/raw_dataset.csv), it performs two key actions. First, it calculates a unique hash—typically MD5—of the file’s content. This hash, such as ec442079a03952b6133c20c5741386d1, serves as a universal, unambiguous identifier for that specific version of the data. The hash is independent of the filename or location. Second, DVC copies the file to a hidden cache (usually in .dvc/cache) and renames it to its hash. This ensures that even if you have ten copies of the same large file in your project, only one copy is physically stored.
Finally, DVC creates a small, human-readable text file with a .dvc extension (e.g., data/raw_dataset.csv.dvc). This metafile is what you actually commit to Git. It contains the hash of the data, its size, and information about where to find it in the cache. A typical metafile looks like this:
outs:
- md5: ec442079a03952b6133c20c5741386d1
size: 10737418240
path: raw_dataset.csv
This tiny text file acts as a pointer or a “bill of materials” for your data. When a colleague clones your Git repository, they get the code and these .dvc metafiles. They then run a command like dvc pull, which reads the hash from the metafile, finds the corresponding data in the shared remote storage (the DVC remote), and downloads it into their workspace. This workflow perfectly marries the strengths of Git for code and collaboration with the efficiency of cloud storage for large data assets. When you switch branches in Git, you are switching to a different set of these metafiles. Running dvc checkout then synchronizes your local data to match the versions pointed to by the metafiles in that branch, ensuring that your code and data are always in perfect alignment.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#283044', 'primaryTextColor': '#ebf5ee', 'lineColor': '#78a1bb', 'textColor': '#283044'}}}%%
graph TD
subgraph User's Local Machine
A[Start: User has<br>code and data.zip] --> B{"Run <br> "dvc add data.zip""};
B --> C["1- DVC calculates <br> hash of data.zip"];
C --> D["2- DVC copies data.zip to <br> local cache (.dvc/cache)"];
D --> E["3- DVC creates metafile <br> "data.zip.dvc""];
E --> F{"Run <br> "git add .""};
F --> G{"Run <br> "git commit -m 'version data'""};
G --> H{"Run <br> "dvc push""};
end
subgraph Version Control & Storage
G -- Pushes metafile --> I[Git Repository];
H -- Pushes data file --> J["Remote Storage <br> (S3, GCS, etc.)"];
end
classDef start fill:#283044,stroke:#283044,stroke-width:2px,color:#ebf5ee;
classDef process fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044;
classDef data fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee;
classDef git fill:#f39c12,stroke:#f39c12,stroke-width:1px,color:#283044;
classDef remote fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
class A start;
class B,F,G,H git;
class C,D,E process;
class I,J remote;
DVC Pipelines: Capturing Data Lineage
Beyond simple file versioning, DVC introduces the concept of pipelines. A DVC pipeline defines the stages of your ML workflow—data preprocessing, feature engineering, training, evaluation—as a Directed Acyclic Graph (DAG). Each stage in the pipeline is defined in a dvc.yaml file, specifying its dependencies (inputs, like code and data), its outputs, and the command to run. DVC uses this graph to understand the entire lineage of your project. It knows that your model.pkl was generated by train.py, which in turn depended on features.csv, which was created by featurize.py from the raw data. When you change a piece of code or data, DVC is smart enough to know which downstream stages need to be re-run, saving significant computation time. This pipeline definition, also versioned in Git, captures the full provenance of your model, making your entire workflow transparent and reproducible.
Foundations of Experiment Tracking with MLflow
While DVC excels at managing the inputs to your model (data and code), experiment tracking is concerned with managing the outputs and the process itself. An ML experiment is more than just a single script execution; it’s a complex combination of source code version, input data hash, hyperparameters, evaluation metrics, and output artifacts like models and visualizations. Platforms like MLflow provide a structured framework for systematically capturing this information. MLflow is built around four primary components, but its core lies in the MLflow Tracking component.
The Core Components of an Experiment
MLflow Tracking is designed around a simple but powerful logging paradigm. It allows you to instrument your training code with a few lines to log the essential components of any experiment to a central server, known as the MLflow Tracking Server. These components are:
- Parameters: The key-value inputs to your run, such as hyperparameters (
learning_rate=0.01,epochs=10). These are the variables you control to influence the model’s behavior. - Metrics: The key-value outputs that measure the model’s performance, such as
accuracy=0.95orrmse=0.23. Metrics can be logged at multiple steps (e.g., per epoch) to track performance over time. - Artifacts: Any output file, such as the trained model itself (
model.pkl), images (a confusion matrix), or data files (a CSV of predictions). These are stored in a managed location, typically cloud storage, associated with the specific run. - Source: MLflow automatically records the Git commit hash of the code that was executed, providing a direct link back to the exact version of the logic used.
When you run your training script, MLflow records all this information as a single, immutable “run” within an “experiment.” An experiment is simply a logical grouping of runs, typically corresponding to a specific modeling task. This creates a searchable, auditable database of every experiment ever conducted. A data scientist can then use the MLflow UI or API to ask complex questions like, “Show me all runs from last week where the accuracy was above 90%, and sort them by the validation loss,” or “Compare the ROC curves for the top 5 models trained for the user churn prediction task.” This transforms experiment management from a chaotic process of manual record-keeping into a systematic, queryable science.
MLflow Experiment: user-churn-prediction
| Run Name | Git Commit | Parameters | Metrics | Artifacts |
|---|---|---|---|---|
| xgboost_run_1 | a1b2c3d4 | learning_rate: 0.01 n_estimators: 500 |
accuracy: 0.92 f1_score: 0.88 |
model.pkl, confusion_matrix.png |
| logistic_regression_base | e5f6g7h8 | solver: ‘liblinear’ C: 1.0 |
accuracy: 0.85 f1_score: 0.81 |
model.pkl, roc_curve.png |
| xgboost_run_2_tuned | a1b2c3d4 | learning_rate: 0.05 n_estimators: 200 |
accuracy: 0.93 f1_score: 0.89 |
model.pkl, feature_importance.png |
The MLflow Tracking Server acts as this central repository. It can be as simple as a local directory of files or as robust as a remote server with a database backend and cloud storage for artifacts. This flexibility allows it to scale from an individual data scientist’s laptop to a large enterprise MLOps platform. By centralizing experiment data, it fosters collaboration, prevents redundant work, and provides a “single source of truth” for a project’s modeling history.
Conceptual Framework and Analysis
Theoretical Framework Application: DAGs as the Backbone of Reproducibility
The concept of a Directed Acyclic Graph (DAG) is the unifying theoretical framework that underpins modern data versioning and ML pipeline tools. A DAG is a mathematical structure consisting of nodes (vertices) and directed edges, with the critical property that there are no cycles. In the context of MLOps, the nodes represent the artifacts of a workflow (datasets, code files, models), and the edges represent the processes or transformations that create them (scripts, commands). DVC pipelines and the lineage implicitly tracked by MLflow are both concrete implementations of a DAG.
This is not merely an academic abstraction; the DAG structure is what guarantees provenance and enables lazy evaluation. Provenance refers to the ability to trace the full ancestry of any artifact. By traversing the graph backward from a final model file, one can identify the exact version of the training script, the feature set, the raw data, and the hyperparameters that produced it. This is the bedrock of auditability and debugging. If a model is found to have a bias, the DAG allows an engineer to precisely identify the upstream data source or feature engineering step that introduced it.
The acyclic nature of the graph is crucial. It ensures that the workflow has a clear beginning and end, preventing infinite loops and guaranteeing that the process is repeatable. Furthermore, the DAG enables powerful optimizations. When a node in the graph changes (e.g., a data scientist modifies the feature engineering script), only the downstream nodes that depend on it need to be recomputed. DVC’s dvc repro (reproduce) command leverages this principle. It examines the DAG defined in dvc.yaml, checks the hashes of all dependencies and outputs, and intelligently re-runs only the stages that have become “dirty” due to an upstream change. This saves immense amounts of time and computational resources, as expensive data processing or model training steps are not needlessly repeated. The DAG is therefore not just a way to visualize a pipeline; it is the computational engine that makes reproducible, efficient, and auditable machine learning workflows possible.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#283044', 'primaryTextColor': '#ebf5ee', 'lineColor': '#78a1bb', 'textColor': '#283044'}}}%%
graph TD
A[raw_data.csv] --> C{process.py};
B[process.py] --> C;
C --> D[processed_data.csv];
D --> F{train.py};
E[train.py] --> F;
F --> G[model.pkl];
G --> I{evaluate.py};
D --> I;
H[evaluate.py] --> I;
I --> J[metrics.json];
classDef data fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee;
classDef code fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044;
classDef model fill:#e74c3c,stroke:#e74c3c,stroke-width:1px,color:#ebf5ee;
classDef output fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
class A,D data;
class B,E,H code;
class C,F,I code;
class G model;
class J output;
Comparative Analysis: Philosophies of MLOps Tooling
The ecosystem of tools for data versioning and experiment tracking is rich and diverse, with different tools embodying distinct philosophical approaches. Choosing the right tool depends on understanding these underlying philosophies and matching them to a team’s specific needs, existing infrastructure, and desired level of abstraction.
Comparison of Data Versioning & Pipeline Tools
| Criterion | DVC (Data Version Control) | Git LFS (Large File Storage) | Pachyderm |
|---|---|---|---|
| Primary Focus | ML Data & Pipeline Versioning | Generic Large File Versioning | Data-Driven Pipelines & Lineage |
| Core Abstraction | Git-like commands, metafiles | Git pointers to large files | Data “repositories” and pipelines |
| Infrastructure | Unopinionated (any blob storage) | Requires a Git LFS server | Kubernetes-native |
| Lineage Tracking | Explicit via dvc.yaml DAGs |
None (file-level versioning only) | Automatic, core feature |
| Ease of Use | High (familiar Git workflow) | High (integrates seamlessly with Git) | Moderate (requires k8s knowledge) |
| Best For | Teams wanting to extend their existing Git workflow with data-awareness. Individuals and teams of all sizes. | Developers needing to store large, non-ML binaries (e.g., graphics assets) in Git. | Enterprises needing end-to-end, language-agnostic, containerized data pipelines with strong governance. |
DVC represents a Git-centric philosophy. Its greatest strength is its seamless integration with the tools and mental models that developers already possess. It extends Git’s capabilities to data without forcing users to abandon their familiar git checkout workflow. This approach is incredibly powerful for teams where data scientists are comfortable with Git and want a lightweight, unopinionated tool that works with any storage backend and any programming language. Its focus is on providing the primitives for reproducibility, leaving orchestration and compute management to other systems.
In contrast, Pachyderm embodies a data-centric and container-native philosophy. It treats data as the central, first-class citizen. In Pachyderm, you create “data repositories,” and pipelines are defined as containerized transformations that trigger automatically when new data is committed to a repository. Its key strength is its automatic and immutable lineage tracking at the level of individual data “commits.” Because every step runs in a container on Kubernetes, it provides unparalleled language-agnostic reproducibility. However, this power comes at the cost of complexity; it requires a Kubernetes cluster and a steeper learning curve, making it better suited for larger organizations with dedicated MLOps teams.
A similar comparison can be made for experiment trackers:
Comparison of Experiment Tracking Tools
| Criterion | MLflow | Weights & Biases (W&B) | Kubeflow Pipelines |
|---|---|---|---|
| Philosophy | Open, modular, unopinionated library | Integrated, “it just works” SaaS platform | Kubernetes-native pipeline orchestration |
| Primary Focus | Logging, packaging, and deploying models | Visualization, collaboration, and reporting | Defining and running complex ML workflows on k8s |
| Hosting | Self-hosted or managed service | Primarily SaaS, with on-prem options | Self-hosted on a Kubernetes cluster |
| Ease of Use | High (simple logging API) | Very High (minimal setup, rich UI) | Moderate (requires k8s and pipeline DSL) |
| Best For | Teams wanting a flexible, open-source foundation they can build upon. | Teams prioritizing ease of use, powerful visualizations, and collaborative features. | Enterprises standardizing their ML infrastructure on Kubernetes and needing complex pipeline orchestration. |
MLflow is an open-source, library-based tool that provides the essential building blocks for MLOps. Its philosophy is modular and unopinionated, allowing teams to adopt its components (Tracking, Projects, Models) incrementally. Weights & Biases, on the other hand, offers a more polished, integrated, and opinionated SaaS experience. It excels at providing rich, real-time visualizations and collaborative reporting features out of the box, trading some of MLflow’s flexibility for a more streamlined user experience. Kubeflow Pipelines is a much heavier-weight solution, focused not just on tracking but on orchestrating entire multi-step workflows as containerized components on Kubernetes, making it a powerful but complex choice for large-scale, standardized MLOps.
Conceptual Examples and Scenarios
To illustrate these principles in action, consider a scenario where an e-commerce company wants to improve its product recommendation engine.
stateDiagram-v2
[*] --> Experimenting: New Project
Experimenting --> Staging: Promote Best Run
Experimenting --> Experimenting: Log New Run
Staging --> Production: Pass All Tests
Staging --> Experimenting: Major Issues Found
Production --> Archived: Model Degradation / New Version
Production --> Production: Monitor & Retrain
Archived --> [*]: Decommissioned
style Experimenting fill:#78a1bb,stroke:#283044,stroke-width:1px,color:#283044
style Staging fill:#f39c12,stroke:#283044,stroke-width:1px,color:#283044
style Production fill:#2d7a3d,stroke:#283044,stroke-width:2px,color:#ebf5ee
style Archived fill:#d63031,stroke:#283044,stroke-width:1px,color:#ebf5ee
Scenario 1: The Reproducibility Challenge
A data scientist, Alice, develops a new model that shows a 5% lift in click-through rate in offline testing. She saves the model as recommender_v3.pkl and emails it to the engineering team. Two months later, the company wants to retrain the model on new product data. However, Alice has left the company. The team finds her training script, but they don’t know which version of the massive user interaction dataset she used. Was it the raw log data from January, or the cleaned version with bot traffic removed? Did she use the product metadata that included the new spring collection? Without data versioning, the team cannot reliably reproduce her result. They are forced to start from scratch, wasting weeks of effort.
With DVC and MLflow: Alice would have used dvc add to track her dataset. The git log would show a commit message like “Add cleaned user interaction data for Q1.” The commit would contain a .dvc file pointing to the exact data hash. Her training run would be logged in MLflow, recording the Git commit of her code, the DVC hash of her data, the hyperparameters she used (e.g., n_estimators=500), and the resulting 5% lift metric. The new team could simply git checkout her commit, dvc pull the correct data, and reproduce her environment and results perfectly in minutes.
Scenario 2: The Debugging Imperative
The new recommendation model is deployed to production. For three weeks, it performs well. On the fourth week, revenue from recommended products drops by 15%. The team suspects model degradation.
Without a tracking system: The team’s investigation is chaotic. They manually review deployment logs, code changes, and data ingestion pipelines. It’s a process of elimination based on tribal knowledge and guesswork. Did the nightly data refresh pipeline fail? Was there a change in the upstream API providing user data?
With a tracking system: The MLOps engineer on call opens the MLflow UI. They see that the model was automatically retrained and deployed five days ago, as scheduled. They compare the training run for the new model with the previous one. They immediately spot a discrepancy: the input data hash is different. Using DVC, they trace the lineage of this new data and discover that an upstream data cleaning job, owned by a different team, was modified. It started incorrectly stripping currency symbols from product prices, causing the price feature to be ingested as NULL for all non-USD products. This corrupted the training data and led to poor recommendations for international users. The DAG-based lineage provided by DVC and the comprehensive logging from MLflow allowed them to diagnose a complex, cross-team issue in under an hour, rather than days. The problem was not in the model code, but in the data, a fact made immediately obvious by the versioning systems.
Analysis Methods and Evaluation Criteria
When evaluating which versioning and tracking strategy to adopt, organizations must move beyond a simple feature-by-feature comparison and consider a holistic set of criteria rooted in their specific context. A useful analytical framework involves assessing tools and practices across three key axes: Technical Fit, Operational Cost, and Governance & Scalability.
mindmap
root((Evaluating MLOps Tools))
Technical Fit
Ecosystem Integration
Workflow Compatibility
Language & Framework Support
Operational Cost
Total Cost of Ownership (TCO)
Cognitive Overhead & Learning Curve
User Experience (UX)
Governance & Scalability
Access Control & Security
Auditability & Compliance
Scalability
1. Technical Fit:
- Ecosystem Integration: How well does the tool integrate with our existing technology stack (cloud provider, CI/CD systems, data warehouses, compute platforms like Spark or Ray)? A tool that requires extensive custom integration may not be worth the effort.
- Workflow Compatibility: Does the tool’s philosophy align with our team’s existing workflow? For a team deeply invested in Git, a Git-centric tool like DVC is a natural fit. For a team building on Kubernetes, a cloud-native tool like Pachyderm might be more appropriate.
- Language & Framework Support: Does the tool provide robust SDKs and support for the programming languages and ML frameworks (TensorFlow, PyTorch, Scikit-learn) our team uses?
2. Operational Cost:
- Total Cost of Ownership (TCO): This includes not just licensing fees (for commercial tools) but also the cost of infrastructure (servers, storage), maintenance, and the engineering time required for setup and support. An open-source, self-hosted tool may have no license fee but could incur significant operational overhead.
- Cognitive Overhead & Learning Curve: How difficult is the tool for new data scientists and engineers to learn? A tool with a steep learning curve can slow down onboarding and reduce adoption. The ideal tool should feel like a natural extension of the developer’s workflow, not a burdensome chore.
- User Experience (UX): For tools with a UI, is it intuitive? Does it provide powerful visualization and comparison features that actively help data scientists gain insights, or is it merely a repository for logs?
3. Governance & Scalability:
- Access Control & Security: Does the tool provide granular role-based access control (RBAC)? How does it manage secrets and credentials needed to access data and infrastructure? This is critical in enterprise environments.
- Auditability & Compliance: Can the system produce a complete, immutable audit trail for a given model? Can it answer the questions required by regulators (e.g., GDPR’s “right to explanation”)?
- Scalability: Can the tool handle the number of experiments, the size of data, and the number of users we anticipate in the future? Does its architecture scale horizontally? For example, can the MLflow Tracking Server be backed by a distributed database, and can its artifact store handle petabytes of data?
By systematically scoring potential tools and workflows against these criteria, an organization can make an informed, strategic decision that balances immediate needs with long-term vision, ensuring the chosen solution will support, rather than hinder, its AI development efforts as they mature.
Industry Applications and Case Studies
The principles of data versioning and experiment tracking are not theoretical ideals; they are actively deployed across industries to solve concrete business problems and unlock value.
- Autonomous Vehicles: Companies developing self-driving cars deal with petabytes of sensor data (LIDAR, camera, radar) from millions of miles of driving. Every piece of this data must be versioned, curated, and labeled. When a model exhibits a failure case (e.g., failing to recognize a pedestrian in rainy conditions), engineers must be able to query and retrieve the exact data slices that correspond to that scenario. They use data versioning systems to manage these massive datasets and experiment tracking to log the performance of thousands of model variations trained on different data subsets and with different architectures. This allows them to systematically improve model performance and ensure the safety and reliability of their systems. The ability to trace a deployed model back to the exact data used for its training and validation is a non-negotiable requirement for safety and regulatory certification.
- Pharmaceutical Drug Discovery: In computational drug discovery, researchers run massive simulations and train models to predict the efficacy and side effects of new molecules. The search space is enormous, and the experiments are computationally expensive. Experiment tracking platforms are essential for managing these large-scale campaigns. Researchers log the parameters of their simulations (molecular structures, physical parameters) and the resulting metrics (binding affinity, toxicity scores). This creates a comprehensive, searchable database of virtual experiments, allowing teams to identify promising candidates, avoid re-running failed experiments, and collaborate globally. The complete audit trail is also critical for intellectual property claims and for submitting results to regulatory bodies like the FDA.
- Fintech and Algorithmic Trading: High-frequency trading firms develop complex models to predict market movements. A model’s performance is exquisitely sensitive to the historical data it was trained on and the specific features used. These firms use sophisticated data versioning to capture point-in-time snapshots of market data, ensuring that backtesting is performed on the exact data that would have been available at that moment, avoiding any look-ahead bias. Every trading algorithm is the result of thousands of experiments. They use tracking systems to log the performance (e.g., Sharpe ratio, max drawdown) of each backtest against specific parameters and data versions. When a deployed algorithm underperforms, they can instantly trace its lineage to determine if the issue is a bug in the code, a shift in market regime, or a flaw in the original training data.
Best Practices and Common Pitfalls
Adopting data versioning and experiment tracking requires more than just choosing a tool; it requires a cultural shift and the implementation of disciplined best practices.
- Integrate, Don’t Isolate: The most effective systems are those where versioning and tracking are not afterthoughts but are deeply integrated into the development lifecycle. Connect your tools to your CI/CD system. For example, create a GitHub Action that automatically runs
dvc reproand logs evaluation metrics to MLflow whenever a pull request is merged. This ensures that every change is automatically validated and tracked. - Version Everything That Matters: Don’t just version your final training set. Version the raw data, the cleaning scripts, the feature engineering code, and every intermediate data artifact. The goal is to be able to reproduce the entire pipeline from scratch. A common pitfall is to only version the final
train.csv, which hides the crucial data processing steps from the audit trail. Use DVC pipelines to define these dependencies explicitly. - Establish a Naming Convention for Experiments: While tools like MLflow assign unique IDs to every run, it’s crucial to use a human-readable naming convention for your experiments. A good practice is to name experiments based on the business problem or modeling task, such as
user-churn-predictionorfraud-detection-xgboost. This makes the UI much easier to navigate and allows team members to quickly find relevant runs. Avoid vague names liketestorJohns_experiments. - Log Rich Context, Not Just Metrics: Don’t stop at logging accuracy and loss. Log hyperparameters, environment details (library versions), data hashes, and qualitative artifacts like plots (confusion matrices, feature importance charts). A plot can often tell a story that a single metric cannot. A common pitfall is to log too little information, making it difficult to differentiate between two runs with similar metrics but different underlying behaviors.
- Treat Your Tracking Server as Production Infrastructure: A self-hosted MLflow server that lives on a data scientist’s laptop is not a robust solution. The tracking server is a critical piece of shared infrastructure. It should be deployed with proper database backends, backup procedures, and access controls. A common mistake is to underestimate the operational importance of the tracking server, leading to data loss when an unmanaged instance fails.
- Don’t Let Perfect Be the Enemy of Good: Implementing a full-blown, end-to-end versioning and tracking system can seem daunting. Start small. Begin by using MLflow to track experiments on a single project. Then, introduce DVC to version the data for that project. Incrementally build up your MLOps maturity. The biggest pitfall is analysis paralysis—waiting to find the “perfect” tool or design the “perfect” system before starting. The value of tracking even a few experiments is far greater than tracking none at all.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#283044', 'primaryTextColor': '#ebf5ee', 'lineColor': '#78a1bb', 'textColor': '#283044'}}}%%
graph TD
subgraph "Development & Versioning"
A[Developer] -- "1- git commit" --> B(Git Repository);
A -- "2- dvc push" --> C[DVC Remote Storage];
end
subgraph "CI/CD & Automation"
B -- "3- Triggers Webhook" --> D{"CI/CD Server<br>(e.g., GitHub Actions)"};
D -- "4- Pulls Code & Data" --> B;
D -- "5- dvc pull" --> C;
D -- "6- Runs Pipeline (dvc repro)" --> E((Compute<br>Environment));
E -- "7- Logs Metrics & Models" --> F(MLflow Tracking Server);
end
subgraph "Deployment & Monitoring"
F -- "8- Model Registry" --> G{Staging/Production};
G -- "9- Serves Model" --> H[End Users / Apps];
H -- "10- Generates New Data" --> I[Data Lake];
I -- "11- Feedback Loop" --> A;
end
style B fill:#f39c12,stroke:#283044,stroke-width:1px,color:#283044
style C fill:#9b59b6,stroke:#283044,stroke-width:1px,color:#ebf5ee
style F fill:#e74c3c,stroke:#283044,stroke-width:1px,color:#ebf5ee
style G fill:#2d7a3d,stroke:#283044,stroke-width:1px,color:#ebf5ee
style D fill:#78a1bb,stroke:#283044,stroke-width:1px,color:#283044
Hands-on Exercises
- Conceptual Pipeline Mapping (Individual):
- Objective: To practice thinking in terms of DAGs and dependencies.
- Task: Choose a machine learning project you have worked on or are familiar with (e.g., predicting house prices, classifying images). On paper or using a diagramming tool, draw the complete DAG of the project. Start with the raw data source(s) and end with the final performance metrics. Create nodes for every script, data file, and model. Label the edges to show the dependencies.
- Expected Outcome: A clear visual representation of your project’s lineage. Identify at least three intermediate data artifacts you might not have thought to version previously.
- Hint: Think about every manual step you perform. If you run
clean.pyto producedata_clean.csv, that’s a stage with one code dependency, one data dependency, and one data output.
- Comparative Tool Analysis (Individual or Team):
- Objective: To develop a framework for evaluating MLOps tools.
- Task: Using the “Analysis Methods and Evaluation Criteria” section as a guide, create a decision matrix to compare two tools: DVC and Pachyderm. Research both tools online from their official documentation and community articles. Fill in the matrix with your assessment of each tool’s strengths and weaknesses across technical fit, operational cost, and governance.
- Expected Outcome: A completed decision matrix with a written summary (2-3 paragraphs) justifying which tool you would recommend for a hypothetical 5-person startup and which you would recommend for a 200-person enterprise technology company.
- Experiment Tracking Forensics (Team):
- Objective: To simulate debugging a production issue using experiment tracking data.
- Task: Your instructor will provide you with a screenshot or a CSV export of an MLflow experiment page containing 15-20 runs. The data will include parameters (e.g.,
learning_rate,dropout,data_version), metrics (accuracy,f1_score), and source information. The instructor will pose a question, such as: “The model deployed from runxyz123is performing poorly on users from Canada. What is the likely cause?” Your team must analyze the provided data to form a hypothesis. - Expected Outcome: A short, written report detailing your hypothesis and the evidence from the experiment data that supports it. For example, you might find that the
data_versionused in the failing run corresponds to a dataset where thecountryfeature was accidentally dropped. - Hint: Look for correlations. Sort the runs by different parameters and metrics. Do you see any patterns where a specific parameter value or data version consistently leads to poor performance?
Tools and Technologies
The primary tools discussed in this chapter represent the modern, open-source foundation for data versioning and experiment tracking.
- DVC (Data Version Control):
- Purpose: An open-source tool for versioning data and ML models. It works alongside Git to version large files, track ML pipelines, and ensure reproducibility.
- Installation: DVC is a Python package installed via pip:
pip install dvc. It also requires a supported backend for remote storage, such as AWS S3 (pip install 'dvc[s3]'), Google Cloud Storage (pip install 'dvc[gcs]'), or a simple SSH server (pip install 'dvc[ssh]'). - Alternatives: Git LFS is a simpler, more generic alternative for large file storage but lacks ML pipeline awareness. Pachyderm is a more powerful, enterprise-grade alternative that provides automated, container-based data versioning and lineage on Kubernetes.
- MLflow:
- Purpose: An open-source platform to manage the end-to-end machine learning lifecycle. This chapter focused on MLflow Tracking, which provides a server and API for logging experiment parameters, metrics, and artifacts.
- Installation: MLflow is also a Python package:
pip install mlflow. For tracking, you can run a local UI withmlflow ui, which uses the local filesystem for storage. For collaborative work, the server should be configured to use a remote database (like PostgreSQL) and a cloud storage artifact root. - Alternatives: Weights & Biases (W&B) is a popular commercial alternative with a strong focus on visualization and collaboration. CometML is another commercial offering in the space. For users heavily invested in the Kubernetes ecosystem, Kubeflow Pipelines provides experiment tracking as part of a broader orchestration system.
Tip: When starting a new project, a powerful and common stack is to use Git for code, DVC for data and pipeline definition (
dvc.yaml), and MLflow for logging the results of pipeline runs. This combination provides a comprehensive, open-source solution for reproducibility.
Summary
- Reproducibility is Critical: Machine learning models are a function of code, data, and parameters. All three must be versioned to ensure reproducibility, which is essential for debugging, collaboration, and regulatory compliance.
- Git is Not Enough: Traditional version control systems like Git are designed for text-based code and are not suitable for handling the large datasets and model files common in AI development.
- Data Versioning with DVC: DVC extends Git, allowing you to use familiar workflows to version large files by storing them in remote storage and tracking them via small, text-based metafiles. DVC pipelines use DAGs to capture the full lineage of your data transformations.
- Experiment Tracking with MLflow: MLflow provides a structured system for logging the key components of an experiment: parameters, metrics, artifacts, and source code versions. This creates a searchable, centralized history of all modeling efforts.
- DAGs are the Foundation: Directed Acyclic Graphs are the core theoretical concept that enables provenance tracking and efficient pipeline execution in modern MLOps tools.
- Choose Tools Based on Philosophy: The right tool for your team depends on your existing workflow, infrastructure, and scalability needs. Evaluate tools based on their underlying philosophy, whether it’s Git-centric (DVC), data-centric (Pachyderm), or a flexible library-based approach (MLflow).
- Best Practices Drive Success: Effective MLOps is about both tools and culture. Integrating tools into CI/CD, establishing clear naming conventions, and treating your tracking infrastructure as a production system are key to success.
Further Reading and Resources
- DVC Official Documentation: (https://dvc.org/doc) – The definitive source for all DVC features, concepts, and tutorials. The “Get Started” guide is an excellent hands-on introduction.
- MLflow Official Documentation: (https://mlflow.org/docs/latest/index.html) – Comprehensive documentation for all MLflow components, including detailed API references and examples.
- “Machine Learning Engineering” by Andriy Burkov: (Chapter 5: “MLOps”) – This book provides a concise, industry-focused overview of MLOps principles, including the role of data versioning and experiment tracking.
- Pachyderm Official Documentation: (https://docs.pachyderm.com/) – For those interested in a deeper, Kubernetes-native approach to data versioning, Pachyderm’s documentation explains its core concepts of data-driven pipelines and immutable lineage.
- Made With ML – MLOps: (https://madewithml.com/mlops) – A practical, hands-on tutorial series that walks through building and deploying ML systems using a modern stack, including Git, DVC, and MLflow.
- “Towards Reproducible Research in AI”: A collection of academic papers and conference workshops (e.g., at NeurIPS, ICML) often discuss the state-of-the-art in reproducibility. Searching for these proceedings will yield cutting-edge research on the topic.
Glossary of Terms
- Artifact: Any file generated during an ML workflow, such as a trained model, a dataset, a plot, or a text file of evaluation results.
- Content-Addressable Storage: A storage mechanism where a piece of data is addressed by a unique hash of its content, rather than by its name or location. This ensures that identical data is only stored once.
- DAG (Directed Acyclic Graph): A graph where nodes are connected by directed edges and there are no cycles. In MLOps, it’s used to represent the dependencies and flow of a pipeline.
- Data Lineage (or Provenance): The complete history of a piece of data, including its origin and all transformations it has undergone.
- DVC (Data Version Control): An open-source tool that works with Git to version data and models and define ML pipelines.
- Experiment Tracking: The process of systematically recording all relevant information about a machine learning experiment, including code, data, parameters, and metrics.
- Git LFS (Large File Storage): A Git extension for versioning large files by storing them on a separate server.
- Metafile: A small text file used by DVC that contains metadata about a large data artifact, such as its content hash and size. This file is versioned in Git.
- MLflow: An open-source platform for managing the end-to-end ML lifecycle, including components for tracking experiments, packaging code, and deploying models.
- Reproducibility: The ability to recreate a prior computational result using the same code, data, and environment.
