
Chapter 41: Data Pipeline Design and Implementation
Chapter Objectives
Upon completing this chapter, you will be able to:
- Design end-to-end data pipelines for both batch and real-time machine learning workflows, considering trade-offs between different architectural patterns like Lambda and Kappa.
- Implement scalable and maintainable data ingestion, transformation, and validation processes using modern Python libraries and data engineering frameworks.
- Analyze data quality requirements and integrate automated validation and monitoring strategies to ensure the reliability and integrity of ML training data.
- Deploy data pipelines using containerization and workflow orchestration tools, applying MLOps principles for scheduling, dependency management, and error handling.
- Optimize pipeline performance by addressing bottlenecks, selecting appropriate data storage solutions, and implementing efficient data processing techniques.
- Understand the components of the modern data stack and how they integrate to support robust, production-grade AI systems.
Introduction
In the landscape of modern AI engineering, models are only as effective as the data they are trained on. The process of moving data from its raw, disparate sources to a clean, structured, and model-ready state is the critical backbone of any successful machine learning system. This process is orchestrated by data pipelines, the automated workflows that ingest, transform, validate, and deliver data. A poorly designed pipeline can introduce subtle biases, compromise data integrity, and ultimately lead to model failure in production. Conversely, a robust, scalable, and reliable data pipeline is a significant competitive advantage, enabling faster iteration, more accurate models, and trustworthy AI-driven products.
This chapter delves into the art and science of designing and implementing data pipelines specifically for machine learning. We will move beyond simple scripting to explore architectural patterns and engineering principles required for production-grade systems. You will learn how to handle the complexities of diverse data sources, from structured databases to real-time event streams, and how to apply rigorous validation to ensure data quality. We will explore the modern data stack, including powerful workflow orchestrators like Apache Airflow and transformation tools that have become industry standards. By the end of this chapter, you will have the foundational knowledge and practical skills to build the data infrastructure that powers sophisticated AI applications, transforming raw data into a strategic asset.
Technical Background
The Anatomy of a Modern Data Pipeline
A data pipeline is best understood as an automated sequence of processes that moves data from a source to a destination. In the context of machine learning, this journey is not merely about transportation; it’s about refinement. The pipeline is responsible for transforming raw, often chaotic data into a highly structured, validated, and feature-rich format that can be consumed by ML models for training and inference. Each stage of the pipeline serves a distinct purpose, collectively ensuring the data’s readiness and reliability. A failure or inefficiency at any stage can have cascading effects, compromising the performance and trustworthiness of the entire AI system. The modern data pipeline is typically composed of four key stages: ingestion, transformation, validation, and delivery.
graph LR
subgraph Raw Data Sources
A[API]
B[Databases]
C[Event Streams]
D[Files .csv, .json]
end
subgraph Data Pipeline Stages
direction LR
Ingest(Ingest)
Transform(Transform)
Validate(Validate)
Deliver(Deliver)
end
subgraph Data Destinations
H[Data Lake]
I[Feature Store]
J[ML Model]
K[Data Warehouse]
end
A -- Ingest --> Ingest
B -- Ingest --> Ingest
C -- Ingest --> Ingest
D -- Ingest --> Ingest
Ingest --> Transform
Transform --> Validate
Validate --> Deliver
Deliver -- Store --> H
Deliver -- Store --> K
Deliver -- Serve --> I
I -- Features --> J
classDef startNode fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee
class A,B,C,D startNode;
classDef processNode fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044
class Ingest,Transform,Validate,Deliver processNode;
classDef endNode fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee
class H,I,J,K endNode;
Data Ingestion: The Gateway to Your Data
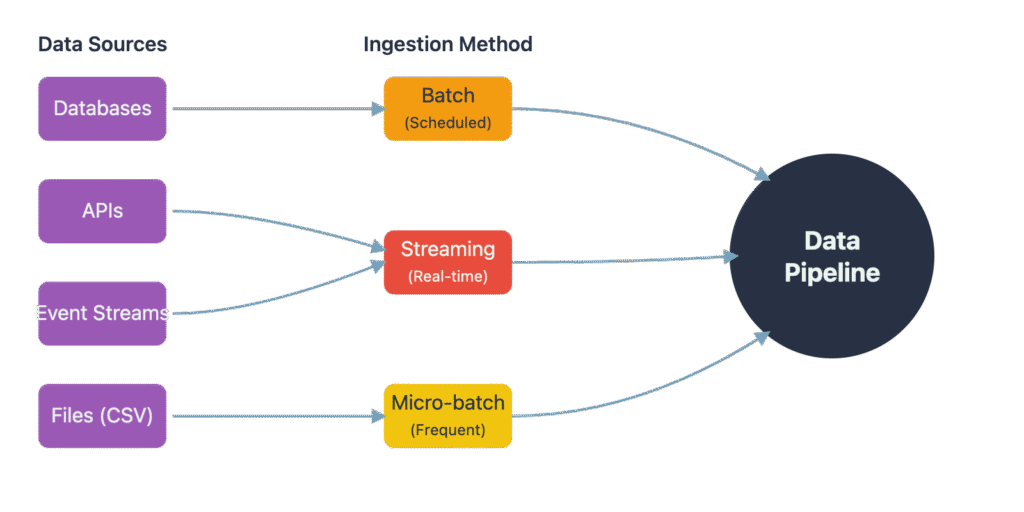
Data ingestion is the first step, where the pipeline connects to various source systems to collect raw data. These sources can be incredibly diverse, ranging from relational databases (e.g., PostgreSQL, MySQL), NoSQL databases (e.g., MongoDB), third-party APIs, event streaming platforms (e.g., Apache Kafka), to simple file storage (e.g., CSV files in an S3 bucket). The method of ingestion is dictated by the nature of the source and the requirements of the ML application. Batch ingestion involves collecting data in large, discrete chunks on a scheduled basis—for example, pulling all of yesterday’s sales data from a database every morning. This approach is suitable for many traditional ML use cases where models are retrained periodically. In contrast, streaming ingestion processes data in real-time or near-real-time as it is generated. This is essential for applications requiring immediate responsiveness, such as fraud detection or real-time recommendation engines. A hybrid approach, micro-batching, processes data in small, frequent batches (e.g., every few minutes), offering a balance between the simplicity of batch processing and the low latency of streaming. The choice of ingestion strategy is a critical design decision that impacts the pipeline’s architecture, cost, and complexity.
Data Transformation: Shaping Raw Data into Insights
Once ingested, raw data is rarely in a usable state for machine learning. The transformation stage is where the heavy lifting of data preparation occurs. This stage can involve a wide range of operations. Data cleaning addresses issues like missing values, duplicates, and inconsistent formatting. For instance, a pipeline might impute missing numerical values with the mean or median of a column, or standardize date formats from multiple sources. Normalization and scaling are common preprocessing steps where numerical features are adjusted to a common scale, such as scaling values to be between 0 and 1 (\(x’ = \frac{x – \min(x)}{\max(x) – \min(x)}\)) or standardizing them to have a mean of 0 and a standard deviation of 1 (\(z = \frac{x – \mu}{\sigma}\)). This is crucial for many algorithms, like support vector machines and neural networks, that are sensitive to the scale of input features.
graph LR
subgraph "ETL (Extract, Transform, Load)"
direction LR
ETL_Source[Source] --> ETL_Staging(Staging Area);
ETL_Staging -- "<b>Transform</b>" --> ETL_Transform{Transformation Logic};
ETL_Transform -- "<b>Load</b>" --> ETL_DW[Data Warehouse];
end
subgraph "ELT (Extract, Load, Transform)"
direction LR
ELT_Source[Source] --> ELT_Load(Data Lake / Warehouse);
ELT_Load -- "<b>Transform</b><br><i>(In-place)</i>" --> ELT_Transformed[Transformed Tables];
end
classDef sourceNode fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee;
class ETL_Source,ELT_Source sourceNode;
classDef processNode fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044;
class ETL_Staging,ETL_Transform,ELT_Load,ELT_Transformed processNode;
classDef endNode fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
class ETL_DW endNode;
The most critical part of this stage for machine learning is feature engineering, the process of creating new, informative features from the existing data. This could involve extracting the day of the week from a timestamp, calculating the ratio of two numerical columns, or applying one-hot encoding to categorical variables. This is where domain knowledge is injected into the pipeline to create signals that make the ML model’s job easier. The historical paradigm for this stage was ETL (Extract, Transform, Load), where data was transformed before being loaded into a centralized data warehouse. However, with the advent of powerful, low-cost cloud data storage, the ELT (Extract, Load, Transform) paradigm has become dominant. In ELT, raw data is loaded directly into a data lake or warehouse, and transformations are performed in place using the powerful compute engines of these systems. This approach provides greater flexibility, as the raw data is preserved and can be re-transformed for new use cases without re-ingesting it.
Data Validation and Quality Assurance
“Garbage in, garbage out” is a well-known axiom in computing that is especially true for machine learning. The data validation stage is a critical quality gate that prevents bad data from corrupting ML models. This goes beyond simple checks for null values. Modern data validation involves defining and enforcing a set of expectations about the data. For example, we might expect a specific column to never contain nulls, for its values to be within a certain range, or for its distribution to remain stable over time. Tools like Great Expectations allow engineers to define these expectations as code, creating a “contract” that the data must adhere to.
The pipeline executes these validation checks automatically. If the data fails validation, the pipeline can be configured to halt processing, quarantine the problematic data, and send an alert to the engineering team. This prevents low-quality data from being used for model training. A key concept in data validation for ML is detecting data drift or concept drift. Data drift occurs when the statistical properties of the input data change over time (e.g., the average purchase amount of customers suddenly increases). Concept drift is when the relationship between the input features and the target variable changes. Automated validation systems can monitor data distributions and model performance, flagging potential drift so that models can be retrained on more recent data. This proactive monitoring is essential for maintaining model performance in a dynamic production environment.
Data Storage and Delivery: Fueling the ML Models
The final stage of the pipeline is to store the processed, validated data in a location where it can be easily accessed for model training and inference. The choice of storage system depends on the scale of the data and the access patterns. A Data Lake (e.g., Amazon S3, Google Cloud Storage) is a repository for storing vast amounts of structured and unstructured data in its native format. It is highly scalable and cost-effective, often serving as the destination for raw data in an ELT architecture. A Data Warehouse (e.g., Snowflake, Google BigQuery) is a system designed for fast querying and analysis of structured data. It’s where transformed, analysis-ready data is often stored.
graph TD
A[Processed Data] --> B{Data Lake};
A --> C{Data Warehouse};
A --> D{Feature Store};
B -- "Raw & Transformed Data" --> E[Ad-hoc Analysis];
C -- "Structured Data" --> F[BI Dashboards];
D -- "Low-latency Features" --> G[Real-time Inference];
B -- "Training Datasets" --> H[Batch Model Training];
C -- "Aggregates" --> H;
classDef startNode fill:#283044,stroke:#283044,stroke-width:2px,color:#ebf5ee;
class A startNode;
classDef storageNode fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044;
class B,C,D storageNode;
classDef useCaseNode fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee;
class E,F,G,H useCaseNode;
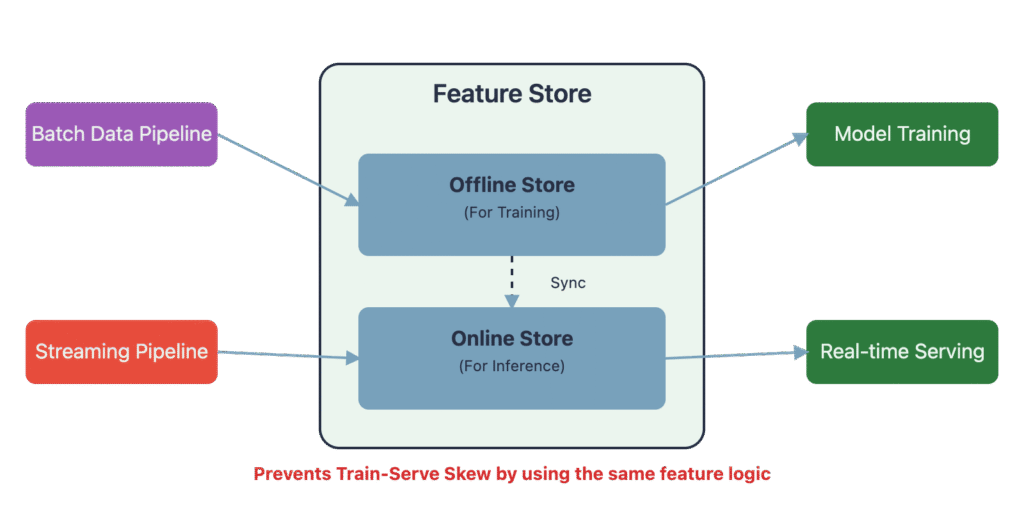
For real-time ML applications, a Feature Store has emerged as a critical piece of infrastructure. A feature store is a centralized repository for storing, retrieving, and managing curated features for machine learning models. It solves several problems: it prevents feature duplication across different projects, ensures consistency between features used for training and serving (preventing train-serve skew), and provides low-latency access to features for real-time inference. For example, when a user visits an e-commerce site, the recommendation model needs to quickly retrieve the user’s latest features (e.g., recent browsing history) to generate personalized recommendations. The feature store is designed for exactly this kind of high-throughput, low-latency read access. The pipeline’s final task is to deliver the right data, in the right format, to the right system, ready to power the next generation of intelligent applications.
Architectural Paradigms and Design Principles
Building a data pipeline involves more than just scripting a sequence of tasks; it requires architectural thinking. The chosen architecture determines how the pipeline handles data timeliness, scales with increasing data volume, and recovers from failures. As data engineering has matured, several architectural patterns have emerged to address the diverse needs of modern applications, from large-scale batch analytics to instantaneous, real-time decision-making. These paradigms, combined with core engineering principles, provide a blueprint for constructing pipelines that are not only functional but also robust, scalable, and maintainable over their entire lifecycle.
graph TD
subgraph Lambda Architecture
direction TB
L_Input([Data Input]) --> L_BatchLayer{Batch Layer};
L_Input --> L_SpeedLayer{Speed Layer};
L_BatchLayer --> L_ServingLayer[Serving Layer];
L_SpeedLayer --> L_ServingLayer;
L_ServingLayer --> L_Query((Query));
style L_Input fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee
style L_BatchLayer fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044
style L_SpeedLayer fill:#e74c3c,stroke:#e74c3c,stroke-width:1px,color:#ebf5ee
style L_ServingLayer fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee
style L_Query fill:#f39c12,stroke:#f39c12,stroke-width:1px,color:#283044
end
subgraph Kappa Architecture
direction TB
K_Input([Data Input]) --> K_Stream{Real-time<br>Processing Layer};
K_Stream --> K_Serving[Serving Layer];
K_Serving --> K_Query((Query));
style K_Input fill:#9b59b6,stroke:#9b59b6,stroke-width:1px,color:#ebf5ee
style K_Stream fill:#78a1bb,stroke:#78a1bb,stroke-width:1px,color:#283044
style K_Serving fill:#2d7a3d,stroke:#2d7a3d,stroke-width:2px,color:#ebf5ee
style K_Query fill:#f39c12,stroke:#f39c12,stroke-width:1px,color:#283044
end
linkStyle 0 stroke-width:2px,fill:none,stroke:black;
linkStyle 1 stroke-width:2px,fill:none,stroke:black;
linkStyle 2 stroke-width:2px,fill:none,stroke:black;
linkStyle 3 stroke-width:2px,fill:none,stroke:black;
linkStyle 4 stroke-width:2px,fill:none,stroke:black;
linkStyle 5 stroke-width:2px,fill:none,stroke:black;
linkStyle 6 stroke-width:2px,fill:none,stroke:black;
linkStyle 7 stroke-width:2px,fill:none,stroke:black;
Batch vs. Real-Time Processing Architectures
The fundamental trade-off in data pipeline architecture is often between latency, cost, and complexity. The Lambda Architecture, proposed by Nathan Marz, was an early attempt to provide a general-purpose solution that could serve both batch and real-time use cases. It operates with three layers: a batch layer, a speed (or real-time) layer, and a serving layer. All incoming data is dispatched to both the batch and speed layers simultaneously. The batch layer pre-computes comprehensive, accurate views of the data on a periodic basis (e.g., every few hours). The speed layer processes the data in real-time to provide immediate, though potentially less accurate, results for the most recent data. The serving layer then merges the results from both the batch and speed layers to answer queries, providing a comprehensive view that combines historical accuracy with real-time information. While powerful, the Lambda architecture’s primary drawback is its complexity; it requires maintaining two separate codebases and data processing systems for the batch and speed layers.
In response to this complexity, Jay Kreps proposed the Kappa Architecture. This architecture eliminates the batch layer entirely and handles all data processing as a single stream. The core idea is that if you have a scalable, ordered, and replayable stream of data (provided by a system like Apache Kafka), you can reprocess the entire history of data through a single stream processing engine whenever you need to regenerate your views. This simplifies the architecture to a single codebase and a single processing framework. The Kappa architecture has gained significant traction with the maturation of stream processing technologies like Apache Flink and Spark Streaming. However, it may not be suitable for all use cases, particularly those involving complex, multi-stage transformations or algorithms that are inherently easier to implement in a batch-oriented manner. The choice between Lambda and Kappa depends on the specific requirements for latency, the complexity of the data processing logic, and the operational maturity of the engineering team.
Scalability, Reliability, and Maintainability
Beyond high-level architectural patterns, several core design principles are essential for building production-grade data pipelines. Scalability is the ability of the pipeline to handle growing amounts of data and processing load. This is typically achieved by designing pipelines to run on distributed systems (like Apache Spark) that can scale horizontally by adding more compute nodes. Using cloud-native, serverless tools (like AWS Glue or Google Cloud Dataflow) can also provide automatic scaling based on demand.
Reliability ensures that the pipeline produces correct results and is resilient to failures. A key concept for reliability is idempotency. An idempotent operation is one that can be applied multiple times without changing the result beyond the initial application. In a data pipeline, if a task fails and needs to be retried, it should be idempotent to avoid creating duplicate data or incorrect results. For example, an INSERT operation is not idempotent, but an UPSERT (update or insert) operation is. Fault tolerance is another aspect of reliability, involving mechanisms for automatic retries, checkpointing the state of long-running jobs, and robust error handling and alerting.
Maintainability refers to the ease with which a pipeline can be understood, modified, and debugged. This is achieved through clean, modular code, comprehensive documentation, and the use of configuration files to separate logic from parameters like database credentials or file paths. Adopting a DataOps or MLOps mindset, which applies DevOps principles like version control, automated testing, and continuous integration/continuous deployment (CI/CD) to data and ML workflows, is crucial for maintainability. Using a workflow orchestrator like Apache Airflow or Prefect helps immensely by providing a clear, visual representation of the pipeline’s structure, managing dependencies between tasks, and centralizing logging and monitoring.
Practical Examples and Implementation
Development Environment Setup
To follow the examples in this chapter, you will need a development environment configured with Python and several key libraries. We recommend using a virtual environment to manage dependencies for this project.
Prerequisites:
- Python 3.11+: Ensure you have a modern version of Python installed.
- Docker and Docker Compose: These are required to run Apache Airflow locally in a containerized environment, which is the recommended setup for development.
Setup Steps:
1. Create a Project Directory and Virtual Environment:
mkdir ml_data_pipeline
cd ml_data_pipeline
python -m venv venv
source venv/bin/activate # On Windows, use `venv\Scripts\activate`2. Install Python Libraries:We will use pandas for data manipulation, great_expectations for data validation, and apache-airflow for orchestration.
pip install pandas scikit-learn great_expectations "apache-airflow[docker]"
apache-airflow[docker] provides the necessary dependencies to work with the official Docker Compose setup.
3. Initialize Apache Airflow:Airflow provides a convenient command to set up a local development environment using Docker Compose.
mkdir airflow
cd airflow
# Download the official Docker Compose file
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.9.2/docker-compose.yaml'
# Create necessary directories
mkdir -p ./dags ./logs ./plugins ./config
# Set the correct Airflow user
echo -e "AIRFLOW_UID=$(id -u)" > .env
# Initialize the database and create the admin user
docker-compose up airflow-init
# Start all Airflow services
docker-compose uphttp://localhost:8080. The default login is airflow with the password airflow. Your dags folder is where you will place your pipeline definitions.
Core Implementation Examples
Let’s start with a simple, standalone Python script that performs a batch ETL process. This script will read raw user data from a CSV file, clean and transform it, and save the result to a new CSV file.
Example 1: Simple Batch ETL Script
This script simulates a common task: preparing user data for a churn prediction model.
# file: simple_etl.py
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import os
def run_simple_etl(input_path: str, output_path: str):
"""
A simple ETL script to process user data.
This function:
1. Extracts data from a source CSV file.
2. Transforms the data by:
- Handling missing values.
- Engineering a new feature ('tenure_in_months').
- Normalizing numerical features.
- One-hot encoding categorical features.
3. Loads the processed data into a destination CSV file.
"""
print("Starting simple ETL process...")
# --- 1. Extract ---
try:
df = pd.read_csv(input_path)
print(f"Successfully extracted {len(df)} rows from {input_path}")
except FileNotFoundError:
print(f"Error: Input file not found at {input_path}")
return
# --- 2. Transform ---
# Handle missing values
df['total_charges'] = pd.to_numeric(df['total_charges'], errors='coerce')
df['total_charges'].fillna(df['total_charges'].median(), inplace=True)
# Feature Engineering: Convert tenure from days to months
df['tenure_in_months'] = (df['tenure_days'] / 30).astype(int)
# Select features for the model
features_to_keep = [
'gender', 'senior_citizen', 'partner', 'dependents',
'tenure_in_months', 'monthly_charges', 'total_charges', 'churn'
]
df_transformed = df[features_to_keep].copy()
# Normalize numerical features
numerical_cols = ['tenure_in_months', 'monthly_charges', 'total_charges']
scaler = MinMaxScaler()
df_transformed[numerical_cols] = scaler.fit_transform(df_transformed[numerical_cols])
# One-hot encode categorical features
categorical_cols = ['gender', 'partner', 'dependents']
df_transformed = pd.get_dummies(df_transformed, columns=categorical_cols, drop_first=True)
# Convert boolean churn to integer
df_transformed['churn'] = df_transformed['churn'].apply(lambda x: 1 if x == 'Yes' else 0)
print("Data transformation complete.")
# --- 3. Load ---
# Ensure output directory exists
os.makedirs(os.path.dirname(output_path), exist_ok=True)
df_transformed.to_csv(output_path, index=False)
print(f"Successfully loaded processed data to {output_path}")
if __name__ == "__main__":
# Create some dummy raw data for demonstration
raw_data = {
'customer_id': ['001', '002', '003', '004'],
'gender': ['Female', 'Male', 'Male', 'Female'],
'senior_citizen': [0, 1, 0, 0],
'partner': ['Yes', 'No', 'No', 'Yes'],
'dependents': ['No', 'No', 'Yes', 'Yes'],
'tenure_days': [30, 720, 90, 1500],
'monthly_charges': [29.85, 56.95, 53.85, 42.30],
'total_charges': ['29.85', '4000.90', '484.65', None],
'churn': ['No', 'Yes', 'No', 'No']
}
raw_df = pd.DataFrame(raw_data)
os.makedirs('data/raw', exist_ok=True)
raw_df.to_csv('data/raw/customer_data.csv', index=False)
# Run the ETL process
run_simple_etl(
input_path='data/raw/customer_data.csv',
output_path='data/processed/processed_customer_data.csv'
)
Tip: While this script is self-contained, in a real project, the ETL logic should be separated from the main execution block. The
run_simple_etlfunction is a good example of this separation, making the logic reusable and easier to test.
Step-by-Step Tutorials
Tutorial: Orchestrating the ETL Process with Apache Airflow
While the simple script works, it requires manual execution. In a production environment, we need to schedule this pipeline to run automatically, handle failures, and manage dependencies. This is where a workflow orchestrator like Apache Airflow excels. We will now convert our script into an Airflow DAG (Directed Acyclic Graph).
A DAG is a Python script that defines a workflow. Each task in the workflow is a node in the graph, and the dependencies between tasks are the directed edges.
Step 1: Create the DAG file
Inside your airflow/dags directory, create a new Python file named customer_churn_pipeline.py.
Step 2: Define the DAG
First, we’ll define the DAG’s properties, such as its ID, schedule, and start date.
# file: airflow/dags/customer_churn_pipeline.py
from __future__ import annotations
import pendulum
from airflow.models.dag import DAG
from airflow.operators.python import PythonOperator
# Define the ETL functions directly in the DAG file for simplicity.
# In a real project, these would be imported from a separate library.
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import os
# Define constants for file paths
RAW_DATA_PATH = "/opt/airflow/data/raw/customer_data.csv"
PROCESSED_DATA_PATH = "/opt/airflow/data/processed/processed_customer_data.csv"
# --- Define Python functions for each task ---
def generate_raw_data():
"""Creates a dummy raw CSV file for the pipeline to process."""
raw_data = {
'customer_id': ['001', '002', '003', '004', '005'],
'gender': ['Female', 'Male', 'Male', 'Female', 'Male'],
'senior_citizen': [0, 1, 0, 0, 1],
'partner': ['Yes', 'No', 'No', 'Yes', 'No'],
'dependents': ['No', 'No', 'Yes', 'Yes', 'No'],
'tenure_days': [30, 720, 90, 1500, 365],
'monthly_charges': [29.85, 56.95, 53.85, 42.30, 99.65],
'total_charges': ['29.85', '4000.90', '484.65', None, '3500.50'],
'churn': ['No', 'Yes', 'No', 'No', 'Yes']
}
raw_df = pd.DataFrame(raw_data)
os.makedirs(os.path.dirname(RAW_DATA_PATH), exist_ok=True)
raw_df.to_csv(RAW_DATA_PATH, index=False)
print(f"Generated raw data at {RAW_DATA_PATH}")
def transform_data():
"""Reads raw data, transforms it, and saves the result."""
df = pd.read_csv(RAW_DATA_PATH)
# The transformation logic is the same as in the simple script
df['total_charges'] = pd.to_numeric(df['total_charges'], errors='coerce')
df['total_charges'].fillna(df['total_charges'].median(), inplace=True)
df['tenure_in_months'] = (df['tenure_days'] / 30).astype(int)
features_to_keep = [
'gender', 'senior_citizen', 'partner', 'dependents',
'tenure_in_months', 'monthly_charges', 'total_charges', 'churn'
]
df_transformed = df[features_to_keep].copy()
numerical_cols = ['tenure_in_months', 'monthly_charges', 'total_charges']
scaler = MinMaxScaler()
df_transformed[numerical_cols] = scaler.fit_transform(df_transformed[numerical_cols])
categorical_cols = ['gender', 'partner', 'dependents']
df_transformed = pd.get_dummies(df_transformed, columns=categorical_cols, drop_first=True)
df_transformed['churn'] = df_transformed['churn'].apply(lambda x: 1 if x == 'Yes' else 0)
os.makedirs(os.path.dirname(PROCESSED_DATA_PATH), exist_ok=True)
df_transformed.to_csv(PROCESSED_DATA_PATH, index=False)
print(f"Transformed data saved to {PROCESSED_DATA_PATH}")
def validate_data():
"""A simple validation step to check the output."""
try:
df = pd.read_csv(PROCESSED_DATA_PATH)
assert len(df) > 0, "Processed data is empty"
assert 'churn' in df.columns, "Target column 'churn' is missing"
# Check that churn is binary
assert df['churn'].isin([0, 1]).all(), "Churn column is not binary"
print("Data validation successful.")
except (FileNotFoundError, AssertionError) as e:
print(f"Data validation failed: {e}")
raise
# --- Define the DAG ---
with DAG(
dag_id="customer_churn_etl_pipeline",
start_date=pendulum.datetime(2024, 1, 1, tz="UTC"),
schedule="@daily",
catchup=False,
tags=["ml", "etl"],
doc_md="""
### Customer Churn ETL Pipeline
This pipeline processes raw customer data to prepare it for a churn prediction model.
- It generates sample raw data.
- It transforms the data by cleaning, feature engineering, and scaling.
- It performs a simple validation on the processed data.
""",
) as dag:
# --- Define Tasks ---
generate_data_task = PythonOperator(
task_id="generate_raw_data",
python_callable=generate_raw_data,
)
transform_data_task = PythonOperator(
task_id="transform_customer_data",
python_callable=transform_data,
)
validate_data_task = PythonOperator(
task_id="validate_processed_data",
python_callable=validate_data,
)
# --- Define Task Dependencies ---
generate_data_task >> transform_data_task >> validate_data_task
Warning: The file paths inside the Airflow tasks (
/opt/airflow/data/...) correspond to the filesystem inside the Docker container. You will need to create adatadirectory inside yourairflowproject folder on your host machine so it gets mounted into the container.
Step 3: Run and Monitor the DAG
Save the file. Airflow will automatically detect it and display it in the UI. You can unpause the DAG and trigger it manually to see it run. The Graph View in the Airflow UI will show the defined dependencies visually: generate_raw_data -> transform_customer_data -> validate_processed_data. You can click on each task instance to view its logs, which is invaluable for debugging.

Integration and Deployment Examples
To make our pipeline more robust and portable, we should containerize the entire workflow, including any custom libraries. While our Airflow setup already uses Docker, a more advanced approach involves building a custom Docker image that includes our pipeline code and dependencies.
Dockerfile for a custom Airflow image:
# Start from the official Airflow image
FROM apache/airflow:2.9.2
# Switch to root user to install dependencies
USER root
# Install any system-level dependencies if needed
# RUN apt-get update && apt-get install -y --no-install-recommends <your-package> && apt-get clean
# Switch back to the airflow user
USER airflow
# Copy our requirements file and install Python packages
COPY requirements.txt /
RUN pip install --no-cache-dir -r /requirements.txt
You would then build this image and reference it in your docker-compose.yaml file. This ensures that the execution environment is consistent and includes all necessary libraries. For production deployment, you would push this custom image to a container registry (like Docker Hub, AWS ECR, or Google Container Registry) and configure your production Airflow environment (e.g., running on Kubernetes with the official Helm chart) to pull from it. This CI/CD approach for deploying DAGs and their dependencies is a cornerstone of modern MLOps.
Industry Applications and Case Studies
Robust data pipelines are the unsung heroes behind countless AI-powered services that we use daily. Their design and implementation are critical to business success across various industries.
- E-commerce Personalization (e.g., Amazon, Netflix): Recommendation engines require massive amounts of data about user interactions (clicks, views, purchases) and item metadata. Data pipelines work around the clock to process this data. A batch pipeline might run nightly to retrain a collaborative filtering model on all historical data. Simultaneously, a real-time streaming pipeline, often built on Kafka and Flink, processes live clickstream data to update user profiles and generate “in-session” recommendations. The challenge is to maintain consistency between the batch and real-time features to avoid train-serve skew. A feature store is often the solution, providing a unified source for both training and live inference. The business impact is direct: better recommendations lead to higher user engagement and increased sales.
- Financial Fraud Detection (e.g., PayPal, Stripe): When a transaction occurs, a fraud detection model must make a decision in milliseconds. This requires a low-latency data pipeline that can ingest transaction data, enrich it with historical features (e.g., user’s average transaction amount, location history), and feed it to an inference service. This is a classic real-time use case for a Kappa-style architecture. The pipeline must be highly available and fault-tolerant, as downtime could result in significant financial losses. The technical challenge lies in processing and serving features at extremely low latency, often requiring in-memory databases and optimized stream processors.
- Autonomous Vehicle Development (e.g., Waymo, Tesla): Autonomous vehicles are equipped with numerous sensors (cameras, LiDAR, radar) that generate terabytes of data per day. Ingesting this massive volume of data from the vehicle fleet into the cloud is a major data engineering challenge. These pipelines are designed to handle large binary files and unstructured data. Once in the cloud, complex ETL pipelines process and label this data to create curated datasets for training perception and prediction models. The scale is immense, and pipelines are built on distributed processing frameworks like Apache Spark running on thousands of nodes. The reliability of these pipelines is paramount, as the safety of the autonomous system depends on the quality of the training data.
Best Practices and Common Pitfalls
Building data pipelines that are robust and easy to manage requires adhering to established engineering principles and being aware of common traps that can lead to technical debt and operational headaches.
Best Practices:
- Embrace Idempotency: Design every task in your pipeline to be idempotent. This means that re-running a failed task will not produce duplicate data or side effects. This is the single most important principle for building reliable, self-healing pipelines. Use
UPSERToperations in databases and design file writes to be atomic and overwritable. - Parameterize Everything: Hardcoding values like file paths, database names, or query parameters in your pipeline logic is a recipe for disaster. Externalize all configuration into a separate file or use a configuration management system (like Airflow’s Variables and Connections). This makes your pipeline flexible and easy to promote from development to production environments.
- Implement Comprehensive Monitoring and Alerting: You cannot fix what you cannot see. Your pipeline should emit detailed logs and metrics (e.g., records processed, task duration, memory usage). Use a monitoring tool (like Prometheus, Grafana, or Datadog) to visualize these metrics and set up automated alerts for anomalies, such as a sudden drop in data volume or a task running much longer than usual.
- Treat Your Data as a Product: Apply software engineering best practices to your data. This includes versioning your datasets, defining clear schemas (data contracts), and implementing automated data quality tests. Tools like
dbt(Data Build Tool) andGreat Expectationsare excellent for implementing this “data-as-code” philosophy. - Separate Compute and Storage: This is a core principle of modern cloud data architectures. By using scalable object storage (like S3) for your data lake and ephemeral compute clusters (like Spark on EKS or Dataproc) for processing, you can scale each component independently, leading to significant cost savings and flexibility.
Common Pitfalls:
- The Monolithic Pipeline: Avoid creating a single, massive script or DAG that does everything. This becomes impossible to debug, test, and maintain. Break down your pipeline into smaller, logical, and reusable tasks or sub-DAGs.
- Ignoring Data Quality Until the End: Many teams focus solely on the transformation logic and only discover data quality issues when the ML model performs poorly. Data validation should be an integral part of the pipeline from the very beginning, with checks at every major stage (post-ingestion, post-transformation).
- Neglecting Backfills: Your pipeline will inevitably need to be re-run on historical data, either to fix a bug or to add a new feature. If the pipeline logic is not designed to handle backfills (e.g., it has hardcoded dates), this can be an incredibly painful and manual process. Always design your tasks to be deterministic and runnable for any given historical period.
- Underestimating “Small” Data: While “big data” gets a lot of attention, many production pipelines fail due to the overhead of processing many small files. Distributed systems like Spark have a significant scheduling overhead for each task, and processing thousands of tiny files can be much slower than processing one large file of the same total size. Implement a compaction step in your pipeline to merge small files into larger, more optimal ones.
Hands-on Exercises
- Basic: Enhance the Simple ETL Script:
- Objective: Add more sophisticated feature engineering and data cleaning to the
simple_etl.pyscript. - Tasks:
- Modify the script to handle a new categorical feature,
payment_method. One-hot encode it. - Instead of filling missing
total_chargeswith the median, fill it based on the average charges for that customer’s tenure. - Add a new feature called
monthly_to_total_ratiocalculated asmonthly_charges / total_charges. Handle potential division by zero.
- Modify the script to handle a new categorical feature,
- Success Criteria: The script runs without errors and the output CSV contains the new, correctly calculated features.
- Objective: Add more sophisticated feature engineering and data cleaning to the
- Intermediate: Add Data Quality Checks to the Airflow DAG:
- Objective: Integrate
Great Expectationsinto the Airflow DAG to perform robust data validation. - Tasks:
- Create a new Python function for the validation task that uses the Great Expectations library.
- Define a set of expectations for the processed data, such as:
expect_column_values_to_not_be_nullfor key columns.expect_column_values_to_be_betweenfor the normalized numerical columns (i.e., between 0 and 1).expect_column_values_to_be_in_setfor the binarychurncolumn.
- Modify the
validate_data_taskin the Airflow DAG to call this new function. The task should fail if the data does not meet the expectations.
- Success Criteria: The Airflow DAG runs, and the validation task succeeds. If you manually introduce “bad” data into the processed file, the validation task should fail, and the logs should clearly state which expectation was not met.
- Objective: Integrate
- Advanced: Design a Micro-Batch Pipeline Architecture:
- Objective: Design a data pipeline architecture for a scenario requiring near-real-time updates.
- Scenario: You are building a system to monitor social media for mentions of your company’s product. You need to process these mentions (e.g., perform sentiment analysis) and update a dashboard every 5 minutes.
- Tasks (Design-oriented, no coding required):
- Choose an appropriate architectural pattern (e.g., Kappa, or a modified batch approach). Justify your choice.
- Draw a diagram of your proposed pipeline. Label the key components (e.g., ingestion service, message queue, processing engine, data store, dashboard).
- Identify the specific technologies you would use for each component (e.g., Kafka for message queue, Spark Streaming for processing, etc.) and explain why.
- Describe how you would handle potential failures, such as the sentiment analysis service being temporarily unavailable.
- Success Criteria: A clear, well-justified architectural diagram and description that addresses the requirements for scalability, latency, and fault tolerance.
Tools and Technologies
The modern data stack is a rich ecosystem of tools, many of which are open-source and have become de facto industry standards.
- Workflow Orchestration:
- Apache Airflow: The dominant open-source platform for programmatically authoring, scheduling, and monitoring workflows. Its “DAGs-as-code” paradigm provides immense flexibility.
- Prefect: A popular alternative to Airflow, focusing on a more modern, Python-native developer experience and dynamic, data-aware pipelines.
- Dagster: A data orchestrator that emphasizes a data-aware, asset-based approach, making it easier to test and maintain data pipelines.
- Data Processing and Transformation:
- Apache Spark: A powerful, distributed, general-purpose cluster-computing framework. It is the go-to tool for large-scale data processing (terabytes to petabytes).
- dbt (Data Build Tool): An open-source command-line tool that enables data analysts and engineers to transform data in their warehouse more effectively. It brings software engineering best practices like version control and testing to the transformation layer.
- Pandas/Polars: Python libraries for in-memory data manipulation. Pandas is the classic choice, while Polars is a newer, high-performance library written in Rust that excels at handling larger-than-memory datasets on a single machine.
- Streaming and Real-Time:
- Apache Kafka: A distributed event streaming platform used as a highly scalable, durable message bus for real-time data feeds.
- Apache Flink: A stream processing framework for stateful computations over unbounded and bounded data streams, known for its low latency and high throughput.
- Cloud Services:
- AWS: Glue (serverless ETL), Kinesis (streaming), S3 (storage), Redshift (warehouse).
- Google Cloud: Dataflow (serverless stream/batch processing), Pub/Sub (messaging), Cloud Storage, BigQuery (warehouse).
- Microsoft Azure: Data Factory, Stream Analytics, Blob Storage, Synapse Analytics.
Summary
- Data pipelines are the foundation of ML systems, responsible for the automated ingestion, transformation, validation, and delivery of data.
- The core stages of a pipeline are Ingest, Transform, Validate, and Deliver, each with specific engineering challenges and solutions.
- Architectural patterns like Lambda (batch + speed layers) and Kappa (all-streaming) provide blueprints for designing pipelines, with a trade-off between complexity and real-time capability.
- Key design principles for robust pipelines include scalability, reliability (especially idempotency), and maintainability.
- Workflow orchestrators like Apache Airflow are essential for scheduling, monitoring, and managing dependencies in production pipelines.
- Data validation is not optional; it is a critical quality gate that should be automated and integrated throughout the pipeline to prevent “garbage in, garbage out.”
- The modern data stack provides a rich ecosystem of specialized tools for each part of the pipeline, enabling engineers to build powerful, modular systems.
Further Reading and Resources
- Designing Data-Intensive Applications by Martin Kleppmann: An essential book that covers the fundamental principles of data systems.
- The Official Apache Airflow Documentation: The most authoritative resource for learning how to build and manage pipelines with Airflow. (https://airflow.apache.org/docs/)
- Great Expectations Documentation: Comprehensive guides and tutorials on implementing data quality testing in your pipelines. (https://greatexpectations.io/docs/)
- The dbt (Data Build Tool) Getting Started Guide: An excellent introduction to applying software engineering principles to data transformation. (https://docs.getdbt.com/docs/get-started/getting-started-overview)
- “The Log: What every software engineer should know about real-time data’s unifying abstraction” by Jay Kreps: The influential blog post that introduced the concepts behind Apache Kafka and the Kappa architecture. (https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying)
- Awesome Data Engineering GitHub Repository: A curated list of resources, tools, and libraries for data engineering. (https://github.com/igorbarinov/awesome-data-engineering)
Glossary of Terms
- DAG (Directed Acyclic Graph): A graph with directed edges and no cycles. In workflow orchestration, it represents a set of tasks and their dependencies.
- Data Drift: A change in the statistical properties of the input data that a model is trained on, which can degrade model performance over time.
- Data Lake: A centralized repository that allows you to store all your structured and unstructured data at any scale.
- Data Warehouse: A system used for reporting and data analysis, which stores integrated, subject-oriented, and historical data.
- ELT (Extract, Load, Transform): A data integration paradigm where raw data is loaded into a target system (like a data lake) first, and transformations are performed afterward.
- ETL (Extract, Transform, Load): A data integration paradigm where data is transformed before being loaded into the target system.
- Feature Store: A centralized data management layer for machine learning features, ensuring consistency between training and serving environments.
- Idempotency: The property of an operation that ensures it can be applied multiple times without changing the result beyond the initial application.
- Kappa Architecture: A data processing architecture that uses a single streaming pipeline to handle both real-time and historical data processing.
- Lambda Architecture: A data processing architecture that uses separate batch and real-time (speed) layers to handle data, merging the results in a serving layer.
