
Chapter 70: Pthreads: Semaphores for Resource Counting & Synchronization
Chapter Objectives
By the end of this chapter, you will be able to:
- Understand the fundamental principles of semaphores and their role in concurrent programming.
- Implement POSIX unnamed semaphores to manage access to shared resources in a multi-threaded application.
- Utilize the core semaphore API (
sem_init,sem_wait,sem_post,sem_destroy) to control thread execution and prevent race conditions. - Design and build a practical, multi-threaded application on a Raspberry Pi 5 that uses semaphores for resource counting.
- Debug common semaphore-related issues, such as deadlocks and incorrect initialization.
- Apply synchronization concepts to solve classic concurrency problems like the producer-consumer problem.
Introduction
In the world of embedded systems, efficiency and reliability are paramount. As systems become more complex, the need to perform multiple tasks concurrently has led to the widespread adoption of multi-threaded programming. However, when multiple threads of execution run simultaneously, they often need to access the same shared resources, such as a memory buffer, a file, or a hardware peripheral like a serial port. Uncontrolled access to these resources can lead to a chaotic state known as a race condition, where the final outcome depends on the unpredictable timing of thread execution. This can result in corrupted data, system instability, and difficult-to-diagnose bugs—failures that are unacceptable in critical embedded applications, from automotive control units to medical devices.
This chapter introduces a powerful and classic synchronization primitive: the semaphore. Unlike a mutex, which acts as a simple lock for exclusive access (either locked or unlocked), a semaphore is a more versatile tool. It maintains a counter and is used to manage access to a pool of a specific number of resources. Think of it as a gatekeeper for a parking garage with a limited number of spaces. The semaphore ensures that no more cars (threads) enter than there are available spots, and it makes waiting cars queue up in an orderly fashion until a spot is free.
We will explore POSIX unnamed semaphores, which are lightweight and ideal for synchronizing threads within a single process. You will learn how to initialize a semaphore to represent a set of available resources, how threads can wait for a resource to become available, and how they signal that they have finished using it. Using the Raspberry Pi 5 as our development platform, we will build a practical application that demonstrates how semaphores can bring order to the potential chaos of concurrent execution, ensuring your embedded applications are both robust and efficient.
Technical Background
The Conceptual Foundation of Semaphores
The concept of the semaphore was first proposed by the Dutch computer scientist Edsger W. Dijkstra in the mid-1960s. At a time when operating systems were beginning to manage multiple concurrent processes, Dijkstra recognized the urgent need for a robust mechanism to manage shared resources without the pitfalls of busy-waiting, where a process wastes CPU cycles continuously checking for a condition to become true. His solution was elegant and powerful, providing a way for processes to block and wait for a resource without consuming the CPU, and to be woken up only when the resource became available.
A semaphore, at its core, is an integer variable that is shared between threads. However, it is more than just a simple integer. It is a protected variable that can only be accessed and modified through two special, atomic operations. Atomic operations are indivisible; they are guaranteed to execute to completion without being interrupted. This atomicity is the cornerstone of what makes semaphores a reliable synchronization tool. If a thread begins to modify the semaphore’s value, no other thread can interfere until the operation is complete. This prevents the very race conditions that semaphores are designed to eliminate.
The two primary operations defined by Dijkstra were P (from the Dutch proberen, “to test”) and V (from verhogen, “to increment”). In the modern POSIX standard, these operations are known as sem_wait() and sem_post(), respectively.
sem_wait()(ThePOperation): When a thread callssem_wait(), it attempts to decrement the semaphore’s internal counter. If the counter is greater than zero, the decrement is successful, and the thread continues its execution, having acquired a resource. If, however, the counter is zero, it means no resources are available. In this case, the thread is put into a blocked or waiting state. The operating system’s scheduler will not allocate any CPU time to this thread until it is unblocked. This is a crucial feature, as it avoids the inefficiency of busy-waiting.sem_post()(TheVOperation): When a thread has finished using a resource, it callssem_post(). This operation increments the semaphore’s counter, effectively returning a resource to the pool. If there are other threads blocked and waiting on this semaphore, thesem_post()call will wake up one of them. The newly awakened thread can then complete itssem_wait()call, decrement the counter, and proceed with its task.
This mechanism gives rise to the term counting semaphore, as the semaphore’s value can be any non-negative integer, representing a count of available resources. This is a key distinction from a mutex (which we explored in a previous chapter), which can be thought of as a special type of semaphore, a binary semaphore, whose count is restricted to 0 or 1. A mutex is for ensuring mutual exclusion—only one thread can hold the lock at a time. A counting semaphore, on the other hand, allows a specified number of threads to access a resource concurrently.
graph TD
subgraph "sem_wait()"
A["Start: Thread calls sem_wait()"] --> B{Is semaphore value > 0?};
B -- Yes --> C[Decrement semaphore value];
C --> D[Thread proceeds with task];
B -- No --> E[Thread is blocked];
end
subgraph "sem_post()"
F["Start: Thread calls sem_post()"] --> G[Increment semaphore value];
G --> H{Are other threads blocked?};
H -- Yes --> I[Wake up one blocked thread];
H -- No --> J[Continue];
I --> J;
end
E --> I;
classDef start fill:#1e3a8a,stroke:#1e3a8a,stroke-width:2px,color:#ffffff;
classDef process fill:#0d9488,stroke:#0d9488,stroke-width:1px,color:#ffffff;
classDef decision fill:#f59e0b,stroke:#f59e0b,stroke-width:1px,color:#ffffff;
classDef blocked fill:#ef4444,stroke:#ef4444,stroke-width:1px,color:#ffffff;
classDef end_node fill:#10b981,stroke:#10b981,stroke-width:2px,color:#ffffff;
class A,F start;
class C,G,I process;
class B,H decision;
class E blocked;
class D,J end_node;
POSIX Unnamed Semaphores in Linux
The POSIX standard (IEEE 1003.1) defines a standardized API for semaphores, ensuring that code written on one compliant system can be easily ported to another. There are two types of POSIX semaphores: named and unnamed.
- Named Semaphores: These are identified by a name (e.g.,
/my_semaphore) and have persistence in the filesystem. This allows them to be shared between different, unrelated processes. They are created withsem_open()and are generally used for inter-process communication (IPC). - Unnamed (or Memory-Based) Semaphores: These exist only in memory and do not have a filesystem name. They are created and managed within the address space of a single process and are primarily used for synchronizing the threads within that process. They are lighter-weight and often more efficient than named semaphores for this purpose. For the remainder of this chapter, we will focus exclusively on unnamed semaphores, as they are the most common choice for thread synchronization in embedded applications.
The life cycle of an unnamed semaphore is managed by a set of four key functions, all declared in the <semaphore.h> header file.
sem_init(): Creating the Semaphore
Before a semaphore can be used, it must be initialized. This is done with the sem_init() function.
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
The function takes three arguments:
sem_t *sem: This is a pointer to asem_tobject, which is the data structure that holds all the information about the semaphore. You must declare a variable of typesem_tin your program and pass its address to this function.int pshared: This integer flag determines the semaphore’s scope. Ifpsharedis 0, the semaphore is unnamed and shared only among the threads of the process that created it. This is the setting we will use. Ifpsharedis non-zero, the semaphore can be shared between processes, provided it is located in a region of shared memory accessible to those processes.unsigned int value: This is the crucial initial value of the semaphore’s counter. This value represents the number of resources that are initially available. For example, if you are managing a pool of 5 network connections, you would initialize the semaphore withvalueset to 5. If you are using the semaphore as a simple lock (a binary semaphore), you would initialize it to 1.
sem_init() returns 0 on success and -1 on failure, setting errno to indicate the error. A common failure is EINVAL if the value exceeds the system’s maximum semaphore value (SEM_VALUE_MAX).
sem_wait() and sem_trywait(): Acquiring a Resource
As discussed, sem_wait() is the function a thread calls to request a resource.
int sem_wait(sem_t *sem);
If the semaphore’s value is positive, it is decremented, and the function returns immediately. If the value is zero, the calling thread blocks until another thread calls sem_post().
There is also a non-blocking variant, sem_trywait().
int sem_trywait(sem_t *sem);<br>sem_trywait() behaves like sem_wait() if the semaphore’s value is positive. However, if the value is zero, it does not block. Instead, it returns immediately with an error (-1) and sets errno to EAGAIN. This is useful in scenarios where a thread needs to check for a resource but has other work it can do if one isn’t immediately available.
sem_post(): Releasing a Resource
When a thread is finished with a resource, it must release it for other threads to use. This is accomplished with sem_post().
int sem_post(sem_t *sem);This function increments the semaphore’s value. If any threads are blocked on a sem_wait() call for this semaphore, one of them will be unblocked and allowed to proceed. The POSIX standard does not specify which thread will be unblocked if multiple are waiting; typically, it is the one that has been waiting the longest (a FIFO policy), but this is implementation-dependent.
sem_destroy(): Cleaning Up
When a semaphore is no longer needed, the resources associated with it should be released back to the system. This is done with sem_destroy().
int sem_destroy(sem_t *sem);
This function cleans up the semaphore object. It is a critical step; failing to destroy a semaphore can lead to resource leaks. It is important to note that sem_destroy() should only be called on a semaphore after all threads have finished using it. Attempting to destroy a semaphore while a thread is blocked on it results in undefined behavior.
stateDiagram-v2
direction TB
[*] --> Uninitialized: Program Start
Uninitialized --> Initialized: sem_init(sem, 0, value)
note right of Initialized
Semaphore object exists in memory
but is not yet in active use.
<b>value</b> sets the initial count.
end note
Initialized --> In_Use: First sem_wait() or sem_post()
In_Use --> In_Use: sem_wait() / sem_post()
note left of In_Use
Threads actively wait on and post to
the semaphore to manage resources.
The internal counter changes,
and threads may block or wake up.
end note
In_Use --> Destroyed: sem_destroy(sem)
note right of Destroyed
All resources associated with the
semaphore are released.
<b>CRITICAL:</b> Must only be called when
no threads are using or blocked on
the semaphore.
end note
Initialized --> Destroyed: sem_destroy(sem)
Destroyed --> [*]: Program End
state "Error Condition" as Error
In_Use --> Error: sem_destroy() called while in use
note right of Error
Undefined Behavior!
(e.g., crash, resource leak)
end note
Error --> [*]
Warning: Never attempt to copy a
sem_tobject directly (e.g.,sem_t sem2 = sem1;). A semaphore contains internal state, including pointers to waiting threads, that cannot be safely duplicated. Always pass semaphores by reference (i.e., using a pointer).
Semaphores vs. Mutexes: Choosing the Right Tool
It is common for beginners to be confused about when to use a semaphore versus a mutex. The choice depends entirely on the problem you are trying to solve.
- Use a mutex for mutual exclusion. A mutex is a lock. Its purpose is to protect a critical section of code—a section that must not be executed by more than one thread at a time. The classic example is updating a shared variable or data structure. The thread that locks the mutex “owns” it and is the only thread that should unlock it.
- Use a semaphore for resource counting and signaling. A semaphore manages access to a pool of identical resources. The
sem_wait()andsem_post()operations are not tied to a specific thread’s ownership. Any thread can “post” to a semaphore to signal that a resource is now available, even if it wasn’t the thread that last “waited” on it. This makes semaphores ideal for signaling between threads. For example, a producer thread can add an item to a buffer and then callsem_post()to signal to a consumer thread that an item is ready.

In summary, if you need to protect a single shared entity and enforce ownership of the lock, a mutex is the correct tool. If you need to manage a pool of N resources or signal between threads about the availability of data or tasks, a semaphore is the superior choice.
Practical Examples
To solidify our understanding, let’s build a practical project on the Raspberry Pi 5. We will simulate a common embedded systems scenario: a logging service that receives log messages from multiple “sensor” threads and writes them to a shared buffer. To prevent the sensor threads from overflowing the buffer and to ensure they don’t write at the same time, we will use semaphores.
This classic problem is a variation of the Producer-Consumer Problem. The sensor threads are the “producers” (creating log messages), and a dedicated logging thread will be the “consumer” (processing the messages from the buffer).
Project Goal
We will create a C program with the following components:
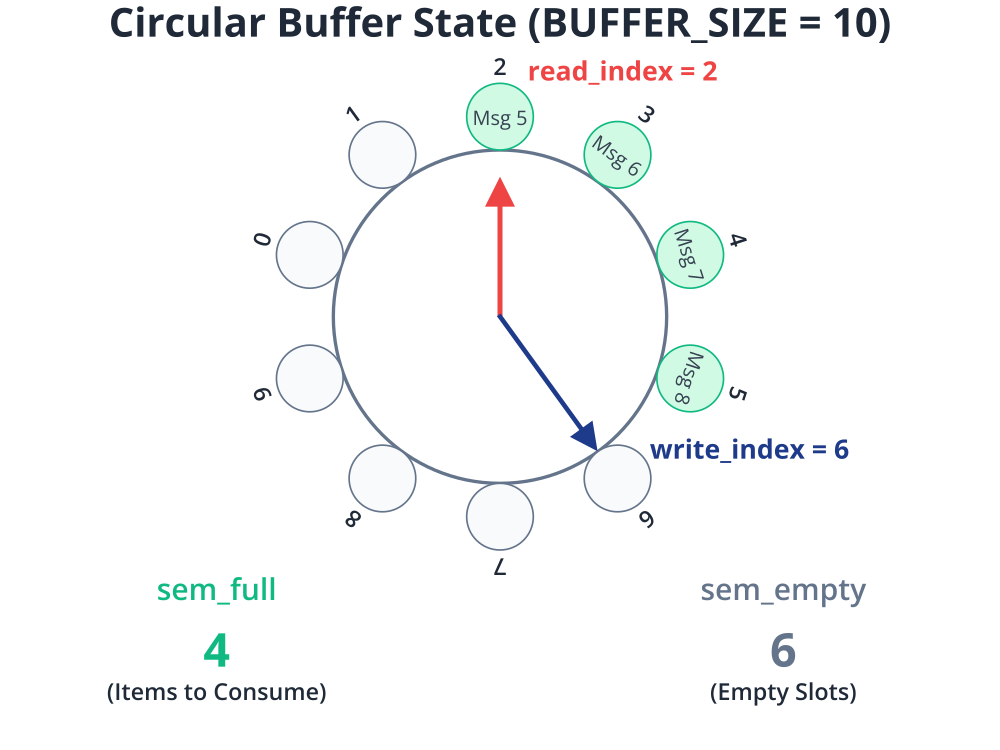
- A fixed-size circular buffer to store log messages.
- Multiple producer threads, each simulating a sensor generating data.
- A single consumer thread that reads messages from the buffer and prints them to the console.
- Two semaphores to manage the buffer:
sem_empty: Counts the number of empty slots in the buffer. Producers will wait on this.sem_full: Counts the number of filled slots in the buffer. The consumer will wait on this.
- A mutex to protect the buffer itself during read/write operations, ensuring that only one thread modifies the buffer indices at a time.
Hardware and Software Setup
- Hardware: Raspberry Pi 5
- Operating System: Raspberry Pi OS (or any other Linux distribution)
- Compiler:
gcc - Dependencies: No special hardware is needed, just a standard Raspberry Pi 5 setup with terminal access.
File Structure
We will create a single source file for this project.
/home/pi/projects/semaphore_logger/
└── logger.c
The C Code (logger.c)
Here is the complete, commented C code for our logging system.
// logger.c
// A multi-threaded logging system using POSIX semaphores and mutexes.
// Demonstrates the producer-consumer problem.
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
#include <string.h>
// --- Configuration ---
#define BUFFER_SIZE 10
#define NUM_PRODUCERS 3
#define MAX_MESSAGES 20 // Total messages to process before shutting down
// --- Shared Resources ---
char buffer[BUFFER_SIZE][256];
int write_index = 0;
int read_index = 0;
int messages_produced = 0;
// --- Synchronization Primitives ---
sem_t sem_empty; // Counts empty buffer slots
sem_t sem_full; // Counts filled buffer slots
pthread_mutex_t buffer_mutex; // Protects access to the buffer indices
// --- Producer Thread Function ---
// Simulates a sensor generating log messages.
void* producer_thread(void* arg) {
int thread_id = *(int*)arg;
free(arg); // Free the allocated memory for the thread ID
while (1) {
// --- Produce an item (a log message) ---
char message[256];
int current_msg_num;
// Safely check and increment the global message counter
pthread_mutex_lock(&buffer_mutex);
current_msg_num = ++messages_produced;
if (current_msg_num > MAX_MESSAGES) {
pthread_mutex_unlock(&buffer_mutex);
// Signal consumer one last time in case it's waiting
sem_post(&sem_full);
break; // Exit loop if we've reached the message limit
}
pthread_mutex_unlock(&buffer_mutex);
sprintf(message, "Log message %d from Sensor %d", current_msg_num, thread_id);
// --- Wait for an empty slot in the buffer ---
// This will block if the buffer is full.
sem_wait(&sem_empty);
// --- Critical Section: Add the message to the buffer ---
pthread_mutex_lock(&buffer_mutex);
strcpy(buffer[write_index], message);
printf("Producer %d: Wrote to buffer at index %d\n", thread_id, write_index);
write_index = (write_index + 1) % BUFFER_SIZE;
pthread_mutex_unlock(&buffer_mutex);
// --- End of Critical Section ---
// --- Signal that a slot is now full ---
sem_post(&sem_full);
// Simulate some work
usleep((rand() % 500 + 100) * 1000);
}
printf("Producer %d: Shutting down.\n", thread_id);
return NULL;
}
// --- Consumer Thread Function ---
// Reads log messages from the buffer and processes them.
void* consumer_thread(void* arg) {
int messages_consumed = 0;
while (messages_consumed < MAX_MESSAGES) {
// --- Wait for a filled slot in the buffer ---
// This will block if the buffer is empty.
sem_wait(&sem_full);
// The producer might have exited after signaling, check the condition again
if (messages_consumed >= MAX_MESSAGES) {
break;
}
// --- Critical Section: Read the message from the buffer ---
pthread_mutex_lock(&buffer_mutex);
char message[256];
strcpy(message, buffer[read_index]);
// Clear the buffer slot for clarity (optional)
strcpy(buffer[read_index], "");
read_index = (read_index + 1) % BUFFER_SIZE;
messages_consumed++;
pthread_mutex_unlock(&buffer_mutex);
// --- End of Critical Section ---
// --- Signal that a slot is now empty ---
sem_post(&sem_empty);
// --- Process the item (print it) ---
printf("Consumer: Processing -> \"%s\" (Total consumed: %d)\n", message, messages_consumed);
// Simulate processing work
usleep((rand() % 100 + 50) * 1000);
}
printf("Consumer: All messages processed. Shutting down.\n");
return NULL;
}
// --- Main Function ---
int main() {
pthread_t producers[NUM_PRODUCERS];
pthread_t consumer;
printf("Starting logging system...\n");
// --- Initialization ---
// Initialize the semaphores
// sem_empty starts at BUFFER_SIZE because all slots are empty.
// sem_full starts at 0 because no slots are full.
sem_init(&sem_empty, 0, BUFFER_SIZE);
sem_init(&sem_full, 0, 0);
// Initialize the mutex
pthread_mutex_init(&buffer_mutex, NULL);
srand(time(NULL)); // Seed the random number generator
// --- Create Threads ---
// Create consumer thread
if (pthread_create(&consumer, NULL, consumer_thread, NULL) != 0) {
perror("Failed to create consumer thread");
return 1;
}
// Create producer threads
for (int i = 0; i < NUM_PRODUCERS; i++) {
int* thread_id = malloc(sizeof(int));
*thread_id = i + 1;
if (pthread_create(&producers[i], NULL, producer_thread, thread_id) != 0) {
perror("Failed to create producer thread");
return 1;
}
}
// --- Wait for Threads to Finish ---
// Join producer threads
for (int i = 0; i < NUM_PRODUCERS; i++) {
pthread_join(producers[i], NULL);
}
printf("All producers have finished.\n");
// After producers are done, we need to make sure the consumer doesn't
// wait forever if it's blocked on an empty buffer.
// Posting to sem_full one last time will unblock it if it's waiting.
sem_post(&sem_full);
// Join consumer thread
pthread_join(consumer, NULL);
printf("Consumer has finished.\n");
// --- Cleanup ---
sem_destroy(&sem_empty);
sem_destroy(&sem_full);
pthread_mutex_destroy(&buffer_mutex);
printf("Logging system shut down cleanly.\n");
return 0;
}
Code Explanation
- Configuration and Shared Resources: We define constants for the buffer size, number of producer threads, and the total number of messages to process. The shared resources—the
bufferitself and theread_index/write_index—are declared as global variables. - Synchronization Primitives: We declare our three synchronization tools:
sem_empty,sem_full, andbuffer_mutex. producer_thread:- It runs in an infinite loop until the
MAX_MESSAGESlimit is reached. sem_wait(&sem_empty): Before writing, the producer must acquire an “empty” slot. If the buffer is full (sem_emptyis 0), this call will block the thread until the consumer frees up a slot.- Critical Section: Access to the
bufferandwrite_indexis protected bypthread_mutex_lockandpthread_mutex_unlock. This is vital because even with semaphores managing the count, the act of updating the index and copying data must be atomic to prevent two producers from writing to the same slot. sem_post(&sem_full): After successfully writing to the buffer, the producer signals that a “full” slot is now available for the consumer.
- It runs in an infinite loop until the
consumer_thread:- It runs in a loop until it has processed
MAX_MESSAGES. sem_wait(&sem_full): The consumer must wait for a “full” slot. If the buffer is empty (sem_fullis 0), this call will block the thread until a producer adds a message.- Critical Section: Similar to the producer, the consumer locks the mutex before reading from the buffer and updating the
read_index. sem_post(&sem_empty): After consuming a message, the consumer signals that an “empty” slot is now available for the producers.
- It runs in a loop until it has processed
mainfunction:- Initialization: This is a critical step.
sem_init(&sem_empty, 0, BUFFER_SIZE)initializes the empty-slot counter to the total capacity of the buffer.sem_init(&sem_full, 0, 0)initializes the full-slot counter to zero, as the buffer starts empty. The mutex is also initialized. - Thread Creation: It creates the single consumer and multiple producer threads.
- Joining: The
mainthread waits for all producer threads to complete usingpthread_join. It then waits for the consumer to finish. The finalsem_post(&sem_full)is a safeguard to wake the consumer if it’s waiting on an empty buffer after all producers have exited. - Cleanup:
sem_destroyandpthread_mutex_destroyare called to release all resources.
- Initialization: This is a critical step.
Build, Flash, and Boot Procedures
Since this is a software-only example, there is no “flashing” involved. We will compile and run the program directly on the Raspberry Pi 5.
1. Open a terminal on your Raspberry Pi 5.
2. Create the project directory and navigate into it:
mkdir -p ~/projects/semaphore_logger cd ~/projects/semaphore_logger3. Create the source file using a text editor like nano or vim:
nano logger.cCtrl+X, then Y, then Enter in nano).
4. Compile the program: We use gcc to compile the code. The crucial flag here is -pthread. This tells the compiler to link against the POSIX threads library, which is where the implementations for pthread_* and sem_* functions reside.
gcc logger.c -o logger -pthread-pthread flag, you will get “undefined reference” errors for all the pthread_ and sem_ functions during the linking phase.
5. Run the executable:
./loggerExpected Output
The output will be an interleaved sequence of messages from the producers and the consumer. The exact order will vary on each run due to the non-deterministic nature of thread scheduling, but the logic will be sound. You will see producers waiting when the buffer is full and the consumer waiting when it’s empty.
Here is a sample of what the output might look like:
Starting logging system...
Producer 1: Wrote to buffer at index 0
Consumer: Processing -> "Log message 1 from Sensor 1" (Total consumed: 1)
Producer 2: Wrote to buffer at index 1
Producer 3: Wrote to buffer at index 2
Consumer: Processing -> "Log message 2 from Sensor 2" (Total consumed: 2)
Producer 1: Wrote to buffer at index 3
Consumer: Processing -> "Log message 3 from Sensor 3" (Total consumed: 3)
...
Producer 2: Wrote to buffer at index 9
Producer 1: Wrote to buffer at index 0
Producer 3: Wrote to buffer at index 1
(At this point, the buffer might be full, and producers will start blocking)
...
Consumer: Processing -> "Log message 19 from Sensor 2" (Total consumed: 19)
Consumer: Processing -> "Log message 20 from Sensor 1" (Total consumed: 20)
Consumer: All messages processed. Shutting down.
Producer 1: Shutting down.
Producer 2: Shutting down.
Producer 3: Shutting down.
All producers have finished.
Consumer has finished.
Logging system shut down cleanly.
This output clearly demonstrates the coordinated dance between the threads, orchestrated perfectly by our semaphores and mutex.
Common Mistakes & Troubleshooting
When working with semaphores, several common issues can arise. Understanding them is key to effective debugging.
Exercises
- Binary Semaphore for a Single Resource:
- Objective: Modify the provided
logger.ccode to use a semaphore as a binary semaphore (a lock) instead of a mutex. - Guidance:
- Remove the
pthread_mutex_t buffer_mutex. - Create a new semaphore,
sem_t mutex_sem;. - Initialize it with a value of 1:
sem_init(&mutex_sem, 0, 1);. - In the producer and consumer, replace
pthread_mutex_lock()withsem_wait(&mutex_sem)andpthread_mutex_unlock()withsem_post(&mutex_sem).
- Remove the
- Verification: The program should run correctly, just as it did with the mutex, demonstrating that a semaphore initialized to 1 behaves like a lock.
- Objective: Modify the provided
- Rate Limiting:
- Objective: Use a semaphore to limit the overall rate at which log messages can be produced by all sensors combined.
- Guidance:
- Introduce a new semaphore,
sem_t rate_limiter;. - Initialize this semaphore to a value, for example, 5. This means a maximum of 5 messages can be produced per second.
- Create a new “refill” thread that runs in a loop. Every second (
sleep(1)), it should callsem_post(&rate_limiter)five times (or use a loop) to add “tokens” to the rate limiter. - In the producer threads, before producing a message, they must call
sem_wait(&rate_limiter).
- Introduce a new semaphore,
- Verification: Run the program. Regardless of how fast the producers could run, the overall output should be limited to approximately 5 messages per second.
- Graceful Shutdown Signal:
- Objective: Implement a more robust shutdown mechanism using a semaphore as a signal.
- Guidance:
- Create a global
volatile int shutdown_flag = 0;. - In
main, after joining the producers, setshutdown_flag = 1. - Instead of the final
sem_post(&sem_full), post multiple times (e.g.,NUM_PRODUCERStimes) to ensure the consumer wakes up even if it’s waiting. - In the consumer’s
whileloop, change the condition towhile (!shutdown_flag || sem_getvalue(&sem_full, &val) == 0 && val > 0). (You’ll need to includesem_getvalue). This makes the consumer drain the buffer completely after the shutdown signal.
- Create a global
- Verification: The program should shut down cleanly, with the consumer processing every message that was produced before the shutdown was initiated.
- Bounded Task Queue:
- Objective: Adapt the producer-consumer model to a generic task queue.
- Guidance:
- Define a
struct Task { ... };. - The buffer should be an array of
Taskstructs. - Producers now generate
Taskobjects and add them to the queue. - The consumer’s job is to “execute” the task (e.g., print a message from the task struct).
- Define a
- Verification: The system should function as a generic task scheduler, where producer threads can offload work to a consumer thread via the synchronized queue.
- Deadlock Investigation:
- Objective: Intentionally create a deadlock and use debugging tools to understand it.
- Guidance:
- In the producer thread, swap the order of the
sem_waitandmutex_lock. That is, callpthread_mutex_lock(&buffer_mutex);beforesem_wait(&sem_empty);. - Run the program with the buffer size set to a small number (e.g., 3).
- In the producer thread, swap the order of the
- Verification: The program will hang (deadlock). Explain in comments exactly why the deadlock occurs. A producer will acquire the mutex, then block on
sem_waitbecause the buffer is full. The consumer, which needs the mutex to free up a slot, will be blocked forever.
sequenceDiagram
title Deadlock: Incorrect Lock Ordering
participant P as Producer
participant M as buffer_mutex
participant SE as sem_empty
participant C as Consumer
P->>M: 1. pthread_mutex_lock()
M-->>P: Lock Acquired
note right of P: Producer now owns the mutex.
P->>SE: 2. sem_wait(&sem_empty)
note right of P: Buffer is full (sem_empty is 0).<br>Producer BLOCKS, but still holds the mutex!
C->>M: 3. pthread_mutex_lock()
note left of C: Consumer needs the mutex<br> to read from<br>the buffer and free up a slot.
note over C,M: Consumer BLOCKS,<br> waiting for Producer to <br>release the mutex.
par
P-->>M: ...waits for Consumer <br>to post to sem_empty...
and
C-->>P: ...waits for Producer <br>to release mutex...
end
box "DEADLOCK" #ef4444
participant P
participant C
end
Summary
- Semaphores are a powerful synchronization primitive used for resource counting and signaling between threads.
- A counting semaphore maintains a non-negative integer counter representing available resources.
- The core POSIX semaphore operations are
sem_init,sem_wait,sem_post, andsem_destroy. sem_wait()decrements the semaphore’s counter, blocking the thread if the counter is zero.sem_post()increments the counter, potentially waking up a blocked thread.- Unnamed semaphores are lightweight and used for synchronizing threads within a single process.
- Semaphores are ideal for solving the producer-consumer problem, where they manage the state of a shared buffer (empty vs. full slots).
- While semaphores manage resource counts, a mutex is still required to protect critical sections where shared data structures (like buffer indices) are modified.
- Proper initialization, cleanup, and lock ordering are critical to avoiding common pitfalls like deadlocks and resource leaks.
Further Reading
- The Linux man-pages: The official and most authoritative source.
man sem_overviewman sem_initman sem_waitman sem_postman sem_destroy
- “The Little Book of Semaphores” by Allen B. Downey. (Available online for free). A fantastic, practical guide to solving concurrency problems with semaphores.
- POSIX.1-2017 Specification: The official standard from the IEEE and The Open Group. The section on semaphores provides the normative definition. (Accessible via the Open Group’s website). https://pubs.opengroup.org/onlinepubs/9699919799.2018edition/
- “Advanced Programming in the UNIX Environment” by W. Richard Stevens and Stephen A. Rago. A classic, comprehensive text covering all aspects of UNIX/Linux system programming, including detailed sections on IPC and synchronization.
- “Pthreads Programming” – A tutorial from the Lawrence Livermore National Laboratory. A concise and well-regarded introduction to Pthreads, including semaphores.
- LWN.net articles on futexes: For those interested in the underlying kernel mechanism, LWN.net has many deep-dive articles explaining how futexes (Fast Userspace Mutexes) are used to implement semaphores and mutexes efficiently in Linux. https://lwn.net/Articles/940944/
