
Chapter 67: Thread Synchronization: The Need for Synchronization
Chapter Objectives
Upon completing this chapter, you will be able to:
- Understand the fundamental concepts of concurrent execution and shared resources in a multi-threaded Linux environment.
- Identify and explain the cause and effect of race conditions in C programs.
- Implement mutexes (mutual exclusion locks) using the POSIX threads library to protect critical sections and prevent data corruption.
- Analyze and describe the four necessary conditions that lead to a deadlock situation.
- Debug common synchronization problems using practical examples on a Raspberry Pi 5.
- Develop a foundational understanding of why synchronization is a critical aspect of reliable embedded systems programming.
Introduction
Welcome to the world of concurrent programming, a domain where the elegance of parallel execution meets the peril of shared resources. In previous chapters, we explored how the Linux kernel manages processes and threads, giving us the power to perform multiple tasks seemingly at once. This capability is the bedrock of modern, responsive embedded systems. An automotive infotainment system, for instance, must simultaneously navigate, play media, and handle Bluetooth phone calls. A factory automation controller must monitor hundreds of sensors while actuating motors and valves. None of this would be possible without concurrency.
However, this power comes with a profound challenge. When multiple threads of execution attempt to read and write to the same piece of data—a shared memory buffer, a global variable, a hardware register—chaos can ensue. Without a coordinating mechanism, threads can interrupt each other at unpredictable times, leading to corrupted data, incorrect calculations, and system crashes. This scenario, known as a race condition, is one of the most insidious and difficult-to-debug problems in concurrent programming.
This chapter confronts this challenge head-on. We will move beyond simply creating threads to managing their interactions. You will learn why synchronization is not an optional extra but an absolute necessity for robust system design. We will dissect the anatomy of a race condition, exploring how the kernel’s scheduler can turn an innocent-looking piece of code into a source of intermittent, non-reproducible failures. We will then introduce the fundamental tool for imposing order: the mutex. Finally, we will explore a more complex multi-threaded pitfall: deadlock, a situation where threads grind to a halt, each waiting for a resource held by another. Using your Raspberry Pi 5, you will write code that fails, and then you will write code that succeeds, gaining a practical, hands-on understanding of the problems and their solutions.
Technical Background
The Illusion of Parallelism: Concurrency on a Single Core
Before we delve into the problems of concurrency, we must first solidify our understanding of how a Linux system executes multiple threads. Even on a single-core processor, the kernel creates the illusion of simultaneous execution through a process called preemptive multitasking. The kernel’s scheduler allocates tiny slices of CPU time, typically mere milliseconds, to each running thread. It lets one thread run for its time slice, then forcibly preempts it—suspending its execution and saving its state (the values in the CPU registers, the program counter, etc.). The scheduler then selects another thread, restores its state, and lets it run for its time slice. This context switching happens so rapidly that, from a human perspective, the threads appear to be running in parallel.

With the advent of multi-core processors, such as the quad-core Arm Cortex-A76 in the Raspberry Pi 5, this parallelism becomes real. The system can execute multiple threads truly simultaneously, one on each core.

However, this does not eliminate the problems of concurrency; it exacerbates them. With true parallelism, the window of opportunity for threads to interfere with one another is wider and the timing of these interactions becomes even more unpredictable. Furthermore, even on a multi-core system, the number of threads often exceeds the number of cores, so preemptive multitasking is still very much in play.
The core issue arises not from the act of running multiple threads, but from the fact that these threads often need to share resources. A resource can be anything from a global variable in your C program, a block of memory allocated on the heap, a file on the filesystem, or a hardware device accessed via a peripheral register (like a GPIO pin). When a piece of code accesses and modifies a shared resource, that section of code is known as a critical section. The fundamental rule of concurrent programming is that only one thread can be allowed to execute within a critical section at any given time. If this rule is violated, we get a race condition.

The Anatomy of a Race Condition
Imagine a simple program designed to count the number of times a sensor has been triggered. A global variable, sensor_count, is used to store this value. Two threads are running: one thread’s job is to increment this counter every time the sensor fires, and another thread’s job is to periodically read the counter and report it.
Let’s examine the seemingly atomic operation of incrementing the counter: sensor_count++;. In a high-level language like C, this looks like a single, indivisible instruction. However, when compiled into machine code for the ARM processor, it is actually a sequence of three distinct instructions:
- LOAD: Load the current value of
sensor_countfrom memory into a CPU register (e.g., registerR0). - ADD: Add 1 to the value in the register (
R0). - STORE: Store the new value from the register (
R0) back into the memory location ofsensor_count.
Now, consider what happens if two threads, Thread A and Thread B, try to increment the counter at roughly the same time. Let’s assume the initial value of sensor_count is 10. The following sequence of events is not just possible, but likely:
- Thread A: Executes the LOAD instruction. It loads the value
10into its CPU register. - Kernel Preemption: The kernel scheduler decides Thread A’s time slice is up. It saves Thread A’s state (including its register containing
10) and switches context to Thread B. - Thread B: Executes the LOAD instruction. It also loads the value
10from memory into its register. - Thread B: Executes the ADD instruction. It increments its register’s value to
11. - Thread B: Executes the STORE instruction. It writes
11back to thesensor_countvariable in memory. - Kernel Preemption: The scheduler now switches back to Thread A, restoring its saved state.
- Thread A: Resumes execution. It has no idea Thread B even ran. Its register still holds the value
10that it loaded earlier. It now executes the ADD instruction, incrementing its register’s value to11. - Thread A: Executes the STORE instruction. It writes
11back to thesensor_countvariable in memory.
The final result is that sensor_count is 11. We had two sensor events and two increment operations, but the final count is wrong. One of the increments has been completely lost. This is a classic read-modify-write race condition. The outcome of the program depends on the unpredictable “race” of which thread gets to execute its instructions in which order. The non-deterministic nature of the kernel scheduler makes these bugs incredibly difficult to reproduce. The program might work correctly a thousand times, only to fail on the thousand-and-first run when the timing of the context switch is just right (or wrong).
sequenceDiagram
participant TA as Thread A
participant TB as Thread B
participant Mem as sensor_count (in Memory)
rect rgba(248, 250, 252, 0.5)
note over Mem: Initial Value: 10
end
TA->>Mem: 1. LOAD value (10) into CPU Register
note over TA: Register A = 10
par
TB->>Mem: 3. LOAD value (10) into CPU Register
note over TB: Register B = 10
and
note over TA, TB: 2. KERNEL PREEMPTION<br>Scheduler switches from Thread A to Thread B
end
TB->>TB: 4. ADD 1 to register
note over TB: Register B = 11
TB->>Mem: 5. STORE register value (11) to memory
note over Mem: Value is now 11
par
TA->>TA: 7. ADD 1 to register
note over TA: Register A = 11
and
note over TA, TB: 6. KERNEL PREEMPTION<br>Scheduler switches back to Thread A
end
TA->>Mem: 8. STORE register value (11) to memory
note over Mem: Value is now 11
rect rgba(239, 68, 68, 0.2)
note over Mem: FINAL VALUE: 11<br>INCORRECT!<br>(Expected: 12)
end
The Solution: Mutual Exclusion with Mutexes
To prevent race conditions, we must enforce the rule of the critical section: only one thread at a time. We need a mechanism that allows a thread to declare, “I am entering this critical section now. No one else is allowed in until I am finished.” This mechanism is called a mutual exclusion lock, or mutex.
A mutex is one of the simplest synchronization primitives. Conceptually, it’s like a key to a room (the critical section). Before a thread can enter the room, it must acquire the key. If the key is available, the thread takes it, locks the door, and enters the room. If another thread arrives and finds the door locked, it must wait outside until the first thread finishes, comes out, and returns the key.
The POSIX threads (pthreads) library, the standard threading API in Linux, provides a simple set of functions for using mutexes:
By wrapping our critical section with pthread_mutex_lock() and pthread_mutex_unlock(), we can guarantee that the read-modify-write sequence is atomic. Atomicity, in this context, means that the sequence of operations appears to the rest of the system as a single, indivisible operation.
Let’s revisit our counter example with a mutex in place:
- Thread A: Calls
pthread_mutex_lock(). It successfully acquires the lock. - Thread A: Executes the LOAD instruction (loads
10). - Thread A: Executes the ADD instruction (register is now
11). - Kernel Preemption: The scheduler preempts Thread A.
- Thread B: Attempts to run. It calls
pthread_mutex_lock(). - Thread B Blocks: The mutex is currently held by Thread A. The kernel puts Thread B into a waiting (or “blocked”) state. It will not be scheduled to run again until the mutex is available.
- Kernel Resumes A: The scheduler eventually resumes Thread A.
- Thread A: Executes the STORE instruction (writes
11tosensor_count). - Thread A: Calls
pthread_mutex_unlock(). It releases the lock. - Kernel Unblocks B: Now that the mutex is free, the kernel can “wake up” Thread B.
- Thread B: Its call to
pthread_mutex_lock()now succeeds, and it acquires the lock. - Thread B: It proceeds to execute its LOAD (
11), ADD (12), and STORE (12) operations, safe from interference. - Thread B: It calls
pthread_mutex_unlock(), releasing the lock.
flowchart TD
subgraph "High-Level C Code"
A["sensor_count++;"]
end
subgraph "Compiled ARM Machine Code (Non-Atomic)"
direction LR
B["1- LOAD<br/>Load sensor_count from<br/>Memory into a CPU Register"] --> C["2- ADD<br/>Increment the value<br/>in the CPU Register"] --> D["3- STORE<br/>Write the new value from<br/>the Register back to Memory"]
end
A --> B
subgraph "Vulnerability"
direction TB
E{"Context Switch<br/>by Kernel Scheduler?"}
E -->|"YES!<br/>Another thread can run<br/>and interfere now!"| F(("RACE<br/>CONDITION"))
end
B -.-> E
C -.-> E
%% Styling
class A highlevel
class B,C,D machineCode
class E vulnerability
class F raceCondition
classDef default fill:#f8fafc,stroke:#64748b,stroke-width:1px
classDef highlevel fill:#1e3a8a,stroke:#1e40af,stroke-width:2px,color:#ffffff
classDef machineCode fill:#0d9488,stroke:#0f766e,stroke-width:1px,color:#ffffff
classDef vulnerability fill:#eab308,stroke:#ca8a04,stroke-width:1px,color:#1f2937
classDef raceCondition fill:#ef4444,stroke:#dc2626,stroke-width:2px,color:#ffffffThe final value of sensor_count is now 12, which is correct. The mutex serialized access to the shared variable, preventing the race condition and ensuring data integrity.
The Peril of Deadlock
While mutexes solve the problem of race conditions, they introduce a new, more complex challenge: deadlock. A deadlock is a state where two or more threads are blocked forever, each waiting for a resource that is held by another thread in the group.
The classic analogy for explaining deadlock is the Dining Philosophers Problem. Imagine five philosophers sitting around a circular table. In front of each philosopher is a plate of spaghetti, and between each pair of adjacent plates is a single chopstick. To eat, a philosopher needs two chopsticks: the one on their left and the one on their right.
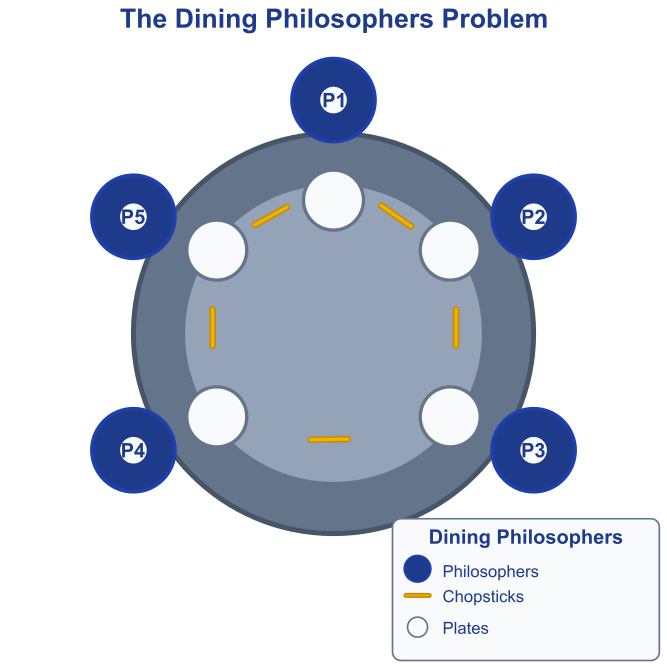
Now, imagine each philosopher is a thread, and each chopstick is a mutex-protected resource. A simple algorithm for a philosopher might be:
- Pick up the chopstick on your left.
- Pick up the chopstick on your right.
- Eat for a while.
- Put down the right chopstick.
- Put down the left chopstick.
- Think for a while, then repeat.
What happens if all five philosophers decide to start eating at exactly the same time? Every single one of them will execute step 1: they all pick up the chopstick on their left. Now, every philosopher tries to execute step 2: pick up the chopstick on their right. But the right chopstick is the left chopstick of their neighbor, who is currently holding it. So, every philosopher is now blocked, waiting for a resource (the right chopstick) that is held by another waiting philosopher. None of them can proceed, and they will wait forever in a state of deadlock.
This is not just a theoretical problem. In an embedded system, a deadlock might occur if, for example, a logging thread locks the serial port to write a message, and then tries to lock a data buffer to read some data. At the same time, a sensor processing thread might have locked the data buffer first and is now trying to lock the serial port to log a status update. Both threads will block, and the system will become unresponsive.
For a deadlock to occur, four conditions, known as the Coffman conditions, must be met simultaneously:
- Mutual Exclusion: At least one resource must be held in a non-sharable mode. That is, only one thread can use the resource at any given time. Our mutexes inherently satisfy this condition.
- Hold and Wait: A thread must be holding at least one resource while waiting to acquire additional resources that are currently held by other threads. In our example, each philosopher holds one chopstick while waiting for the second.
- No Preemption: A resource cannot be forcibly taken away from the thread that is holding it. The thread must release the resource voluntarily. Mutexes work this way; you cannot force another thread to unlock its mutex.
- Circular Wait: A set of waiting threads {T0, T1, …, Tn} must exist such that T0 is waiting for a resource held by T1, T1 is waiting for a resource held by T2, …, and Tn is waiting for a resource held by T0. This forms the unbreakable circle of dependencies.
Preventing deadlocks involves breaking at least one of these four conditions. The most common and practical strategy is to break the circular wait condition. This is typically achieved by enforcing a strict lock ordering policy. If all threads are required to acquire locks in the same predefined order, a circular dependency becomes impossible. For example, if we had two mutexes, mutex_A and mutex_B, the policy might be: “You must always lock mutex_A before you lock mutex_B.” If a thread already holds mutex_B and needs mutex_A, it must first release mutex_B before attempting to acquire mutex_A. This simple discipline prevents the deadlock scenario.
Practical Examples
Now, let’s translate this theory into practice on your Raspberry Pi 5. We will write, compile, and run C code that first demonstrates a race condition and then shows how to fix it with a mutex.
Tip: Ensure you have the build essentials package installed on your Raspberry Pi OS. You can install it by running
sudo apt-get update && sudo apt-get install build-essential.
This provides the GCC compiler and other tools needed for this section.
Example 1: Demonstrating a Race Condition
Our first program will create two threads that both increment a single global variable a large number of times. Without synchronization, we expect the final value to be incorrect due to the race condition we discussed.
File Structure
Create a directory for our chapter examples, for instance ~/ch67, and save the following code in a file named race_condition.c.
~/ch67/
└── race_condition.c
Code: race_condition.c
This program sets up a shared data structure containing a counter. Two threads are created, and each is passed a pointer to this shared data. The increment_task function, executed by both threads, loops 5 million times, incrementing the counter in each iteration. The main function waits for both threads to complete and then prints the final value of the counter.
// race_condition.c
// Demonstrates a race condition with two threads.
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
// The number of times each thread will increment the counter.
// A large number makes the race condition more likely to manifest.
#define INCREMENTS_PER_THREAD 5000000
// A struct to hold the shared data.
// Using a struct makes it easier to pass multiple shared variables to a thread.
typedef struct {
long long counter;
} shared_data_t;
// The function executed by each thread.
void* increment_task(void* arg) {
// Cast the void* argument back to our shared data struct type.
shared_data_t* data = (shared_data_t*)arg;
printf("Thread starting to increment.\n");
for (long long i = 0; i < INCREMENTS_PER_THREAD; ++i) {
// This is the critical section!
// The read-modify-write operation here is not atomic.
data->counter++;
}
printf("Thread finished.\n");
return NULL;
}
int main() {
// Create and initialize the shared data.
shared_data_t shared_data = { .counter = 0 };
// Thread identifiers
pthread_t thread1_id;
pthread_t thread2_id;
printf("Starting program. Expected counter value = %lld\n", 2LL * INCREMENTS_PER_THREAD);
// Create the first thread
if (pthread_create(&thread1_id, NULL, increment_task, &shared_data) != 0) {
perror("Failed to create thread 1");
return 1;
}
// Create the second thread
if (pthread_create(&thread2_id, NULL, increment_task, &shared_data) != 0) {
perror("Failed to create thread 2");
return 1;
}
// Wait for the first thread to finish
if (pthread_join(thread1_id, NULL) != 0) {
perror("Failed to join thread 1");
return 1;
}
// Wait for the second thread to finish
if (pthread_join(thread2_id, NULL) != 0) {
perror("Failed to join thread 2");
return 1;
}
// Print the final result
printf("----------------------------------\n");
printf("Final counter value: %lld\n", shared_data.counter);
printf("Expected value: %lld\n", 2LL * INCREMENTS_PER_THREAD);
printf("Difference: %lld\n", (2LL * INCREMENTS_PER_THREAD) - shared_data.counter);
printf("----------------------------------\n");
return 0;
}
Build and Run
- Open a terminal on your Raspberry Pi 5.
- Navigate to the directory where you saved the file:
cd ~/ch67. - Compile the code. The
pthreadlibrary is not linked by default, so you must explicitly tell the GCC compiler to link it using the-pthreadflag.gcc -o race_condition race_condition.c -pthread - Run the executable.
./race_condition
Expected Output
Because of the non-deterministic nature of the scheduler, your exact output will likely vary with every run. However, it will almost certainly be incorrect.
Starting program. Expected counter value = 10000000
Thread starting to increment.
Thread starting to increment.
Thread finished.
Thread finished.
----------------------------------
Final counter value: 6481023
Expected value: 10000000
Difference: 3518977
----------------------------------
As you can see, the final result is not 10,000,000. Over 3.5 million increments were lost due to the race condition. The two threads repeatedly interfered with each other’s read-modify-write cycles, overwriting each other’s results. Run the program several times; you will get a different incorrect result each time, highlighting the non-deterministic nature of the bug.
Example 2: Fixing the Race Condition with a Mutex
Now, let’s fix the problem. We will modify the previous program to include a pthread_mutex_t. We will initialize it and then use pthread_mutex_lock() and pthread_mutex_unlock() to protect the critical section.
File Structure
Save this new version as mutex_fix.c in the same ~/ch67 directory.
~/ch67/
├── race_condition.c
└── mutex_fix.c
Code: mutex_fix.c
The key changes are adding a pthread_mutex_t to our shared data structure, initializing it in main, destroying it before exiting, and most importantly, locking and unlocking it around the data->counter++ line in the increment_task function.
// mutex_fix.c
// Fixes the race condition using a pthread mutex.
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <time.h>
#define INCREMENTS_PER_THREAD 5000000
// Add a mutex to our shared data structure.
typedef struct {
long long counter;
pthread_mutex_t lock; // The mutex lock
} shared_data_t;
// The function executed by each thread.
void* increment_task(void* arg) {
shared_data_t* data = (shared_data_t*)arg;
printf("Thread starting to increment.\n");
for (long long i = 0; i < INCREMENTS_PER_THREAD; ++i) {
// --- CRITICAL SECTION START ---
// Acquire the lock before accessing the shared counter.
pthread_mutex_lock(&data->lock);
data->counter++;
// Release the lock after we are done with the shared counter.
pthread_mutex_unlock(&data->lock);
// --- CRITICAL SECTION END ---
}
printf("Thread finished.\n");
return NULL;
}
int main() {
// Initialize shared data
shared_data_t shared_data = { .counter = 0 };
// Initialize the mutex.
// The second argument is for attributes, NULL means use defaults.
if (pthread_mutex_init(&shared_data.lock, NULL) != 0) {
perror("Mutex initialization failed");
return 1;
}
pthread_t thread1_id;
pthread_t thread2_id;
printf("Starting program. Expected counter value = %lld\n", 2LL * INCREMENTS_PER_THREAD);
// Create threads as before
pthread_create(&thread1_id, NULL, increment_task, &shared_data);
pthread_create(&thread2_id, NULL, increment_task, &shared_data);
// Join threads as before
pthread_join(thread1_id, NULL);
pthread_join(thread2_id, NULL);
// Clean up the mutex
pthread_mutex_destroy(&shared_data.lock);
printf("----------------------------------\n");
printf("Final counter value: %lld\n", shared_data.counter);
printf("Expected value: %lld\n", 2LL * INCREMENTS_PER_THREAD);
printf("Difference: %lld\n", (2LL * INCREMENTS_PER_THREAD) - shared_data.counter);
printf("----------------------------------\n");
return 0;
}
Build and Run
The compilation and execution steps are identical to the previous example.
- Compile the code:
gcc -o mutex_fix mutex_fix.c -pthread - Run the executable:
./mutex_fix
Expected Output
This time, the output will be correct, every single time.
Starting program. Expected counter value = 10000000
Thread starting to increment.
Thread starting to increment.
Thread finished.
Thread finished.
----------------------------------
Final counter value: 10000000
Expected value: 10000000
Difference: 0
----------------------------------
Notice that the program might run slightly slower. This is the performance cost of synchronization. The pthread_mutex_lock() call can involve a system call into the kernel if there is contention (i.e., if a thread tries to lock a mutex that’s already held), which adds overhead. However, this small performance penalty is the necessary price for correctness and data integrity, which is non-negotiable in a reliable embedded system.
Common Mistakes & Troubleshooting
When working with mutexes, several common pitfalls can lead to bugs that are just as frustrating as race conditions, or worse, cause your application to freeze entirely.
Exercises
These exercises are designed to be completed on your Raspberry Pi 5. They will reinforce the concepts from this chapter and test your understanding of synchronization issues.
- Measure the Performance Cost: Modify the
mutex_fix.cprogram to measure the time it takes to execute. Use theclock_gettime()function withCLOCK_MONOTONICto record the time before creating the threads and after joining them. Run the program and record the time. Now, comment out thepthread_mutex_lock()andpthread_mutex_unlock()calls (re-introducing the race condition) and run it again. How much faster does the incorrect version run? Write a brief analysis of the trade-off between performance and correctness. - Create a Deadlock: Write a new C program named
deadlock.c. In this program, create two mutexes,lock_Aandlock_B. Create two threads. The first thread’s task function should locklock_A, sleep for a short time (e.g.,usleep(100)), and then attempt to locklock_B. The second thread’s task function should do the opposite: locklock_B, sleep, and then attempt to locklock_A. Inmain, after creating the threads, join them. Your program should hang and never exit. Useprintfstatements to show which locks are being acquired. Explain in comments in your code why the deadlock occurs. - Fix the Deadlock: Take your
deadlock.cprogram and fix it by enforcing a lock ordering policy. Modify the code so that both threads always acquire the locks in the same order (e.g., alwayslock_Athenlock_B). Verify that the program now runs to completion without hanging. - Producer-Consumer Problem: Implement a simple bounded buffer problem. Create a global array (the “buffer”) of a fixed size (e.g., 10 integers) and a global counter for the number of items in the buffer. Create one “producer” thread that adds items (e.g., random numbers) to the buffer and one “consumer” thread that removes them. You will need one mutex to protect access to the buffer and the counter. The producer should not add to the buffer if it is full, and the consumer should not take from it if it is empty. (Note: This simple version will involve “busy-waiting”. In a future chapter, we will learn a more efficient method using condition variables).
Summary
- Concurrency is the execution of multiple threads of control, which can be truly parallel on multi-core systems or an illusion created by rapid context switching on single-core systems.
- A critical section is a piece of code that accesses a shared resource. To prevent data corruption, only one thread should execute in a critical section at a time.
- A race condition occurs when the outcome of a program depends on the unpredictable timing and interleaving of operations from multiple threads accessing a shared resource. This often happens with non-atomic read-modify-write operations.
- A mutex (mutual exclusion lock) is a synchronization primitive used to protect a critical section. By locking the mutex before entering the section and unlocking it after, we ensure atomic access to the shared resource.
- A deadlock is a state where two or more threads are blocked indefinitely, each waiting for a resource held by another thread in the same group.
- Deadlocks can be prevented by breaking one of the four Coffman conditions, most commonly by enforcing a strict lock ordering policy to break the circular wait condition.
- Synchronization introduces a performance overhead, but it is essential for the correctness and reliability of concurrent programs.
Further Reading
- The Single UNIX Specification, Issue 7 (POSIX.1-2008): The official standard for the
pthreadslibrary. The pages forpthread_mutex_lock,pthread_mutex_init, etc., are the ultimate authority. Available from The Open Group. https://pubs.opengroup.org/onlinepubs/9799919799/ - “Is Parallel Programming Hard, And, If So, What Can You Do About It?” by Paul E. McKenney. A comprehensive and deeply technical resource on the complexities of concurrency, written by a Linux kernel expert.
- “An Introduction to Programming with Threads” by Andrew D. Birrell. A classic and highly influential paper that clearly articulates the fundamental concepts and pitfalls of concurrent programming.
- Linux Kernel Locking Guide: While focused on kernel development, this document provides excellent explanations of the various locking primitives and the problems they solve. It offers a professional perspective on why robust locking is critical. Available in the Linux kernel documentation. https://www.kernel.org/doc/html/v4.13/kernel-hacking/locking.html
- “Modern Operating Systems” by Andrew S. Tanenbaum and Herbert Bos. The chapters on processes, threads, and interprocess communication provide a strong academic foundation for the topics discussed here.
