
Chapter 53: Advanced File I/O: Scatter/Gather I/O (readv, writev)
Chapter Objectives
By the end of this chapter, you will be able to:
- Understand the fundamental principles of scatter/gather I/O and its advantages over traditional I/O models.
- Explain the role of the
iovecstructure and how it enables operations on non-contiguous memory buffers. - Implement C programs that utilize the
readvandwritevsystem calls to perform efficient, multi-buffer I/O on a Raspberry Pi 5. - Analyze the performance benefits of vectored I/O and identify use cases where it is most effective.
- Debug common issues related to the implementation of
readvandwritev, such as incorrect buffer management and misunderstanding atomicity. - Configure a development environment and build process for cross-compiling and testing system-level C applications for an embedded Linux target.
Introduction
Performance is not merely a feature in embedded Linux; it is often a fundamental design constraint. Whether processing high-throughput network data, managing complex sensor inputs, or manipulating structured file formats, the efficiency of data movement between user space and the kernel is paramount. Previous chapters have explored the standard I/O system calls—read(), write(), and lseek()—which form the bedrock of Linux file operations. These calls, however, operate on single, contiguous blocks of memory. While sufficient for many tasks, this model introduces significant overhead when an application needs to read or write data that is naturally scattered across different memory buffers.
Consider a network server application. A typical network packet is not a monolithic block of data but is composed of distinct parts: a fixed-size header, a variable-length payload, and perhaps a footer or checksum. An application might store these components in separate data structures for easier management. To send this packet using a standard write() call, the developer has two inefficient choices: either copy all the scattered parts into a single, contiguous temporary buffer before making the system call, or make multiple write() calls, one for each part. The first approach consumes extra CPU cycles and memory bandwidth for the copy operation. The second approach incurs the overhead of multiple kernel transitions, each context switch adding latency.
This is precisely the problem that scatter/gather I/O, also known as vectored I/O, is designed to solve. The readv() (“read vector”) and writev() (“write vector”) system calls provide a powerful and elegant mechanism to read data from a single source into multiple, non-contiguous memory buffers (a “gather” operation) or write data from multiple buffers to a single destination (a “scatter” operation) in a single, atomic system call. By passing a vector of buffer descriptions to the kernel, the application can eliminate intermediate data copying and reduce the number of system calls, leading to substantial performance gains. This chapter delves into the theory and practice of scatter/gather I/O, providing the technical foundation and hands-on examples needed to master this essential system programming technique on your Raspberry Pi 5.
Technical Background
The Inefficiency of Traditional I/O Models
To fully appreciate the elegance of scatter/gather I/O, we must first dissect the limitations of the standard read() and write() system calls when dealing with structured data. As introduced in previous chapters, the prototypes for these calls are straightforward:
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
Both functions operate on a single buffer (buf) of a given size (count). This model is perfectly efficient when the data to be read or written resides in a contiguous block of memory. However, in many real-world applications, data is often logically structured but physically fragmented in memory.
Let’s return to our network packet example. A packet might be defined by a structure containing a header and a pointer to a dynamically allocated payload:
struct network_packet {
packet_header_t header; // A fixed-size struct
char *payload; // A pointer to the data
size_t payload_size;
};
Here, header and the data pointed to by payload are not in adjacent memory locations. To write this packet to a socket using write(), the programmer is faced with a dilemma.
The first option is to serialize the data. This involves allocating a new, temporary buffer large enough to hold both the header and the payload, and then copying both components into it.
// Option 1: Copying to a contiguous buffer
void send_packet_inefficient_copy(int sockfd, struct network_packet *pkt) {
size_t total_size = sizeof(pkt->header) + pkt->payload_size;
char *temp_buffer = malloc(total_size);
if (!temp_buffer) { /* handle error */ return; }
// Copy header
memcpy(temp_buffer, &pkt->header, sizeof(pkt->header));
// Copy payload
memcpy(temp_buffer + sizeof(pkt->header), pkt->payload, pkt->payload_size);
// Single system call, but with preceding memory copies
write(sockfd, temp_buffer, total_size);
free(temp_buffer);
}
This approach has the advantage of using only one system call, which minimizes the overhead of kernel context switching. However, the memcpy() operations introduce their own costs. Copying data is a CPU-intensive task that consumes memory bandwidth and can pollute the CPU caches, potentially slowing down other parts of the application. In high-throughput scenarios, this overhead can become a significant bottleneck.
The second option is to make multiple system calls, one for each data segment.
// Option 2: Multiple system calls
void send_packet_inefficient_syscalls(int sockfd, struct network_packet *pkt) {
// First system call for the header
write(sockfd, &pkt->header, sizeof(pkt->header));
// Second system call for the payload
write(sockfd, pkt->payload, pkt->payload_size);
}
This approach avoids the memcpy() overhead, as no temporary buffer is needed. However, it introduces a different kind of performance penalty: the cost of multiple system calls. Each call to write() triggers a transition from user mode to kernel mode and back, a process known as a context switch. This is a computationally expensive operation involving saving the user process’s state, executing the kernel code, and then restoring the user process’s state. For small, frequent writes, the cumulative cost of these context switches can easily outweigh the benefit of avoiding memory copies.
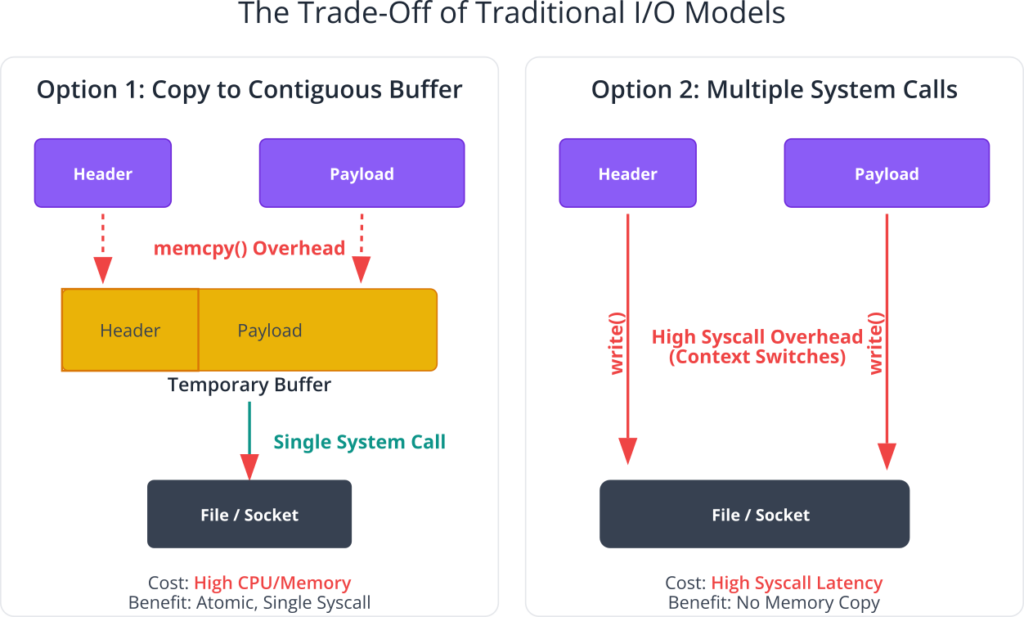
Furthermore, the multiple-call approach breaks the atomicity of the operation. If the file descriptor refers to a network socket, the two separate write() calls could result in two separate packets being sent on the network, which is likely not the intended behavior. The receiving end would see the header and payload as distinct arrivals, potentially breaking the application protocol. Even with file I/O, another process could potentially write to the file between the two calls, corrupting the data structure.
Scatter/gather I/O was introduced into Unix-like systems to resolve this very trade-off, providing a mechanism to achieve the atomicity and single-call efficiency of the first approach without the memory-copying overhead of the second.
The iovec Structure: A Vector of Buffers
The core of the scatter/gather mechanism is the iovec structure, which acts as a descriptor for a single, contiguous block of memory. The readv() and writev() system calls don’t take a single buffer and size as arguments; instead, they take an array of iovec structures. This array, or “vector,” describes the collection of memory buffers that will participate in the I/O operation.
The iovec structure is defined in <sys/uio.h> and is remarkably simple:
struct iovec {
void *iov_base; /* Starting address of the buffer */
size_t iov_len; /* Number of bytes to transfer from this buffer */
};
iov_base: This is a pointer (void *) to the beginning of a memory buffer.iov_len: This is the size (size_t) of that buffer.
An application prepares for a scatter/gather operation by creating an array of these iovec structures. Each element in the array points to a different piece of data that needs to be read or written. For our network packet example, we would set up an array of two iovec structures: one for the header and one for the payload.

This array of iovecs acts as a map, telling the kernel where to find the data to be written (for writev) or where to place the data being read (for readv). The kernel can then iterate through this vector and perform the I/O directly between the file descriptor and the user-space buffers, completely eliminating the need for an intermediate, contiguous buffer.
The readv() and writev() System Calls
With the iovec structure understood, the prototypes for readv() and writev() become clear:
#include <sys/uio.h>
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
Let’s break down the arguments:
fd: The file descriptor for the file, socket, or pipe to operate on. This is identical to its role inread()andwrite().iov: A pointer to an array ofiovecstructures. This is the vector that describes the memory buffers.iovcnt: An integer specifying the number ofiovecstructures in the array pointed to byiov.
The return value, ssize_t, is the total number of bytes read or written. On error, it returns -1 and sets errno to indicate the cause.
When writev() is called, the kernel processes the buffers in the order they appear in the iov array. It writes the iov_len bytes from the first buffer (iov[0].iov_base), then the bytes from the second buffer (iov[1].iov_base), and so on, until all iovcnt buffers have been written. Crucially, this is performed as a single, atomic operation. From the perspective of other processes or the underlying file system, the data from all buffers appears to be written simultaneously. This atomicity is a key advantage, ensuring data integrity for structured records.
sequenceDiagram
actor User as User Application
participant Kernel
participant Device as File/Device Driver
User->>Kernel: writev(fd, iov, 3)
activate Kernel
Note over Kernel: Single System Call Transition
Kernel->>Kernel: 1. Validate fd and iov pointers
Kernel->>Kernel: 2. Lock file/socket for atomic operation
loop For each iovec in iov array (i=0 to 2)
Kernel->>User: 3a. Access iov[i].iov_base (User Memory)
Note right of Kernel: No intermediate copy!
Kernel->>Device: 3b. Write iov[i].iov_len bytes to device
end
Kernel->>Kernel: 4. Unlock file/socket
deactivate Kernel
Kernel-->>User: Return total bytes writtenSimilarly, when readv() is called, the kernel reads data from the file descriptor and fills the buffers in order. It first fills the buffer described by iov[0] with iov[0].iov_len bytes, then fills iov[1] with iov[1].iov_len bytes, and continues until all buffers are full or the end of the file is reached. The total number of bytes read is returned.
The maximum number of iovec structures that can be passed in a single call is limited by IOV_MAX, which is defined in <limits.h>. On modern Linux systems, this value is typically 1024, which is more than sufficient for most applications.
Atomicity and Performance Implications
The concept of atomicity is central to the utility of writev(). An atomic operation is one that appears to the rest of the system as occurring instantaneously and indivisibly. When writev() writes data from multiple buffers, it guarantees that the entire sequence of writes will not be interleaved with writes from other processes to the same file descriptor.
Imagine a logging application where each log entry consists of a timestamp, the hostname, the process ID, and the log message itself. Each of these components might be generated and stored separately.
---
title: Atomicity Guarantee of writev()
---
flowchart TD
subgraph "Scenario 1: Multiple write() Calls (Non-Atomic)"
direction TB
A_Write1("A: write(fd, &ts)"):::check
B_Write1("B: write(fd, &ts)"):::check
A_Write2("A: write(fd, &msg)"):::check
B_Write2("B: write(fd, &msg)"):::check
Corrupted_File("[Corrupted Log File [TS_A][TS_B][MSG_A][MSG_B]]"):::check
end
subgraph "Scenario 2: Single writev() Call (Atomic)"
direction TB
A_iov["A: iov = {&ts, &msg}"]:::proc
B_iov["B: iov = {&ts, &msg}"]:::proc
A_WriteV("A: writev(fd, iov, 2)"):::success
B_WriteV("B: writev(fd, iov, 2)"):::success
Good_File("[Correct Log File [TS_A][MSG_A][TS_B][MSG_B]]"):::success
end
Process_A_Group --> A_Write1
Process_B_Group --> B_Write1
A_Write1 --> B_Write1
B_Write1 --> A_Write2
A_Write2 --> B_Write2
B_Write2 --> Corrupted_File
Process_A_Group --> A_iov
Process_B_Group --> B_iov
A_iov --> A_WriteV
B_iov --> B_WriteV
A_WriteV --> B_WriteV
B_WriteV --> Good_File
%% Styling
classDef proc fill:#0d9488,stroke:#0d9488,stroke-width:1px,color:#ffffff
classDef check fill:#ef4444,stroke:#ef4444,stroke-width:1px,color:#ffffff
classDef success fill:#10b981,stroke:#10b981,stroke-width:2px,color:#ffffffWithout writev(), if two processes were logging to the same file concurrently using multiple write() calls, their output could become garbled:
// Process A writes timestamp
// Process B writes timestamp
// Process A writes hostname
// Process B writes hostname
// ... resulting in a corrupted log file
By using writev(), each process can assemble its log entry in a vector of iovecs and write it with a single call. The kernel ensures that the entire log entry from one process is written before the log entry from another process begins, preserving the integrity of each record.
The performance benefits are equally compelling. The primary gain comes from the reduction in the number of system calls. As discussed, each system call has a non-trivial overhead. By consolidating what would have been multiple write() or read() calls into a single writev() or readv() call, this overhead is paid only once.
Furthermore, by providing the vector of buffers directly to the kernel, the application allows the kernel to optimize the data transfer. The kernel can work directly with the user-space pages, avoiding the need to allocate a kernel-space buffer and perform a data copy. For writev(), the kernel can gather the data from the various user-space locations and pass it directly to the underlying device driver. For readv(), it can scatter the incoming data from the device directly into the specified user-space buffers. This “zero-copy” characteristic (or more accurately, “reduced-copy”) is a hallmark of high-performance I/O frameworks and is a key reason why readv() and writev() are heavily used in performance-critical software like web servers (e.g., Nginx), databases, and scientific computing applications.
xychart-beta
x-axis ["Multiple write()", "memcpy() + write()", "Single writev()"]
y-axis "Relative Overhead" 0 --> 100
bar [90, 65, 20];
line [90, 65, 20];
In summary, the technical foundation of scatter/gather I/O rests on a simple yet powerful abstraction: the iovec. This structure allows applications to describe complex, non-contiguous data layouts to the kernel, which can then perform I/O operations in a single, atomic, and highly efficient manner. This avoids the classic trade-off between expensive memory copies and expensive multiple system calls, providing the best of both worlds for sophisticated I/O tasks.
Practical Examples
This section provides hands-on examples to solidify your understanding of scatter/gather I/O. We will use the Raspberry Pi 5 as our target platform. The examples will be written in C and compiled using the standard GCC toolchain. We will first demonstrate writev by creating a structured log file, and then use readv to parse that same file.
Setting Up the Development Environment
Before we begin, ensure your Raspberry Pi 5 is running a standard Raspberry Pi OS (or a similar Debian-based distribution). You will need the build-essential package, which includes gcc and make.
# On your Raspberry Pi 5
sudo apt update
sudo apt install build-essential
For these examples, we will perform development and compilation directly on the Raspberry Pi. This simplifies the workflow, though in a professional setting, cross-compilation from a more powerful host machine is common.
Example 1: Writing Structured Data with writev
Our first goal is to create a simple application that writes structured log entries to a file. Each entry will consist of three parts:
- A 32-bit integer representing the log level.
- A 64-bit integer for a high-precision timestamp (e.g., microseconds since epoch).
- A variable-length string for the log message.
We will store these parts in separate variables and use writev to write them as a single, atomic record.
The C Code (writev_logger.c)
Create a file named writev_logger.c and enter the following code. The comments explain each step of the process.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/uio.h>
#include <sys/time.h>
#include <stdint.h>
#define LOG_FILE "structured.log"
// A simple function to get microseconds since epoch
uint64_t get_timestamp_us() {
struct timeval tv;
gettimeofday(&tv, NULL);
return (uint64_t)tv.tv_sec * 1000000 + tv.tv_usec;
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s \"<log message>\"\n", argv[0]);
return EXIT_FAILURE;
}
// 1. Prepare the data components in separate variables
uint32_t log_level = 2; // 0=DEBUG, 1=INFO, 2=WARNING, 3=ERROR
uint64_t timestamp = get_timestamp_us();
char *message = argv[1];
size_t message_len = strlen(message);
printf("Preparing to write log entry:\n");
printf(" Level: %u\n", log_level);
printf(" Timestamp: %lu us\n", timestamp);
printf(" Message: '%s' (length: %zu)\n", message, message_len);
// 2. Open the log file for writing, create if it doesn't exist, append.
// O_APPEND is crucial for ensuring multiple processes can write without overwriting.
int fd = open(LOG_FILE, O_WRONLY | O_CREAT | O_APPEND, 0644);
if (fd == -1) {
perror("open");
return EXIT_FAILURE;
}
// 3. Set up the iovec structure array
struct iovec iov[3];
// First buffer: log level
iov[0].iov_base = &log_level;
iov[0].iov_len = sizeof(log_level);
// Second buffer: timestamp
iov[1].iov_base = ×tamp;
iov[1].iov_len = sizeof(timestamp);
// Third buffer: the log message string
iov[2].iov_base = message;
iov[2].iov_len = message_len;
// 4. Perform the scatter write operation
ssize_t bytes_written = writev(fd, iov, 3);
if (bytes_written == -1) {
perror("writev");
close(fd);
return EXIT_FAILURE;
}
printf("\nSuccessfully wrote %zd bytes to %s\n", bytes_written, LOG_FILE);
// Verify the total size
size_t expected_size = sizeof(log_level) + sizeof(timestamp) + message_len;
if (bytes_written != expected_size) {
fprintf(stderr, "Warning: Mismatch in written bytes. Expected %zu, got %zd\n",
expected_size, bytes_written);
}
// 5. Clean up
close(fd);
return EXIT_SUCCESS;
}
flowchart TD
A[Start]:::start --> B{argc == 2?};
B -- No --> C[Print Usage Error & Exit]:::check;
B -- Yes --> D[Prepare Data<br><i>log_level, timestamp, message</i>]:::proc;
D --> E["Open Log File<br><i>O_WRONLY | O_CREAT | O_APPEND</i>"]:::proc;
E --> F{File Open OK?};
F -- No --> G["perror(open) & Exit"]:::check;
F -- Yes --> H["Setup iovec Array<br><b>iov[0]</b> -> &log_level<br><b>iov[1]</b> -> ×tamp<br><b>iov[2]</b> -> message"]:::sys;
H --> I["Call writev(fd, iov, 3)"]:::sys;
I --> J{writev OK?};
J -- No --> K["perror(writev) & Exit"]:::check;
J -- Yes --> L[Print Success Message]:::proc;
L --> M[Close File Descriptor]:::proc;
M --> N[End]:::success;
%% Styling
classDef start fill:#1e3a8a,stroke:#1e3a8a,stroke-width:2px,color:#ffffff
classDef success fill:#10b981,stroke:#10b981,stroke-width:2px,color:#ffffff
classDef decision fill:#f59e0b,stroke:#f59e0b,stroke-width:1px,color:#ffffff
classDef proc fill:#0d9488,stroke:#0d9488,stroke-width:1px,color:#ffffff
classDef check fill:#ef4444,stroke:#ef4444,stroke-width:1px,color:#ffffff
classDef sys fill:#8b5cf6,stroke:#8b5cf6,stroke-width:1px,color:#ffffffBuild and Run
Compile the code using gcc. The -o flag specifies the output executable name.
gcc writev_logger.c -o writev_logger
Now, run the program with a log message.
./writev_logger "System initialized successfully."
Expected Output:
Preparing to write log entry:
Level: 2
Timestamp: 1679602800123456 us
Message: 'System initialized successfully.' (length: 29)
Successfully wrote 41 bytes to structured.log
(Note: Your timestamp will be different.)
The total bytes written should be 4 (for uint32_t) + 8 (for uint64_t) + 29 (for the message) = 41 bytes.
Run it a few more times with different messages:
./writev_logger "Sensor reading out of range."
./writev_logger "Network connection established."
Verifying the Output File
Because the log file contains binary data (the integers), you can’t simply view it with cat. Use a tool like hexdump or xxd to inspect its raw contents.
hexdump -C structured.log
Expected hexdump Output:
00000000 02 00 00 00 80 3e 8c 75 2d 54 01 00 53 79 73 74 |...>.u-T..Syst|
00000010 65 6d 20 69 6e 69 74 69 61 6c 69 7a 65 64 20 73 |em initialized s|
00000020 75 63 63 65 73 73 66 75 6c 6c 79 2e 02 00 00 00 |uccessfully.....|
00000030 ...and so on for the next records...
Let’s decode the first record (the first 41 bytes):
02 00 00 00: The 32-bit integer2(log level), in little-endian format as used by the Raspberry Pi’s ARM processor.80 3e 8c 75 2d 54 01 00: The 64-bit timestamp.53 79 73 74 ...: The ASCII representation of “System initialized successfully.”.
Notice how the data from our three separate C variables has been written contiguously into the file, exactly as intended.
Example 2: Reading Structured Data with readv
Now we will write a complementary program to read and parse the structured.log file we just created. This program will demonstrate how readv can “gather” data from a file directly into the appropriate fields of a C structure, without needing an intermediate buffer.
The C Code (readv_parser.c)
First, let’s define a structure to hold our log entry. This is a good practice for organizing the data we intend to read.
// In a header file like 'log_format.h' or at the top of the C file
#include <stdint.h>
#define MAX_MSG_LEN 256
struct log_entry {
uint32_t log_level;
uint64_t timestamp;
char message[MAX_MSG_LEN];
};
Now, create the main parser file, readv_parser.c.
#include <stdio.h>
#include <stdlib.hh>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/uio.h>
#include <stdint.h>
#define LOG_FILE "structured.log"
// This structure must match the data format we wrote
struct log_header {
uint32_t log_level;
uint64_t timestamp;
};
int main(int argc, char *argv[]) {
// 1. Open the log file for reading
int fd = open(LOG_FILE, O_RDONLY);
if (fd == -1) {
perror("open");
return EXIT_FAILURE;
}
// We need to know the size of the file to determine message length
struct stat sb;
if (fstat(fd, &sb) == -1) {
perror("fstat");
close(fd);
return EXIT_FAILURE;
}
// For this example, we assume the file contains only one record
// A real parser would loop.
off_t file_size = sb.st_size;
size_t header_size = sizeof(struct log_header);
if (file_size < header_size) {
fprintf(stderr, "Log file is too small to contain a valid record.\n");
close(fd);
return EXIT_FAILURE;
}
size_t message_len = file_size - header_size;
// 2. Prepare the destination buffers
struct log_header header_data;
char *message_buffer = malloc(message_len + 1); // +1 for null terminator
if (!message_buffer) {
perror("malloc");
close(fd);
return EXIT_FAILURE;
}
// 3. Set up the iovec structure array
struct iovec iov[2];
// First buffer: the fixed-size header
iov[0].iov_base = &header_data;
iov[0].iov_len = sizeof(header_data);
// Second buffer: the variable-length message
iov[1].iov_base = message_buffer;
iov[1].iov_len = message_len;
// 4. Perform the gather read operation
ssize_t bytes_read = readv(fd, iov, 2);
if (bytes_read == -1) {
perror("readv");
free(message_buffer);
close(fd);
return EXIT_FAILURE;
}
// Null-terminate the message string
message_buffer[message_len] = '\0';
printf("Successfully read %zd bytes from %s\n\n", bytes_read, LOG_FILE);
printf("Parsed Log Entry:\n");
printf(" Level: %u\n", header_data.log_level);
printf(" Timestamp: %lu us\n", header_data.timestamp);
printf(" Message: '%s'\n", message_buffer);
// 5. Clean up
free(message_buffer);
close(fd);
return EXIT_SUCCESS;
}
Tip: The
readv_parser.cexample is simplified to read only the first record. A robust implementation would loop, reading the fixed-size header first to determine the length of the upcoming message, then performing a second read for the message body itself.readvis most useful when the sizes of all components are known in advance.
Build and Run
Compile the parser:
gcc readv_parser.c -o readv_parser
Now, run it. It will read the structured.log file created by our previous example.
./readv_parser
Expected Output:
Successfully read 41 bytes from structured.log
Parsed Log Entry:
Level: 2
Timestamp: 1679602800123456 us
Message: 'System initialized successfully.'
(The timestamp and message will correspond to the first record in your log file.)
This example perfectly illustrates the power of readv. The kernel read the 12 bytes of the header directly into the header_data struct and the remaining 29 bytes of the message directly into the message_buffer, all in a single system call. We avoided reading the entire record into one large buffer and then manually parsing and copying the fields into their respective structures. For applications that parse complex binary file formats or network protocols, this technique is invaluable.
Common Mistakes & Troubleshooting
While powerful, readv and writev have nuances that can trip up developers. Here are some common pitfalls and how to avoid them.
Exercises
These exercises are designed to be completed on your Raspberry Pi 5. They build upon the examples and concepts presented in this chapter.
- Robust Log Parser:
- Objective: Modify the
readv_parser.cexample to correctly parse the entirestructured.logfile, not just the first record. - Guidance: The current parser assumes a single record. Your new version should run in a loop. In each iteration, it should:
- Read the fixed-size header (
log_levelandtimestamp) first to determine how long the message is. Hint: This is a trick question. The current file format doesn’t store the message length. You’ll need to modify the writer first!
- Read the fixed-size header (
- Step 1 (Modify Writer): Change
writev_logger.cto include themessage_len(as auint32_t, for example) as part of the record. The new record structure should be:log_level,timestamp,message_len,message. - Step 2 (Modify Parser): Now, update
readv_parser.c. The loop should first read the fixed-size part (log_level,timestamp,message_len). Then, using themessage_lenit just read, it performs a secondread()call to get the message body. - Verification: The parser should correctly print every log entry from a file created by your new writer.
- Objective: Modify the
- Creating a Network Packet Assembler:
- Objective: Use
writevto assemble and send a simple network packet over a TCP socket. - Guidance:
- Create a server program that listens on a local port (e.g., 9999).
- Create a client program. In the client, define a packet structure with a header (e.g.,
uint16_t packet_type; uint16_t payload_len;) and a string payload. - Populate the header and payload in separate variables.
- Use
writevto send the header and payload to the server in a single, atomic operation. - The server should use
read()to receive the data and print the contents of the header and payload to confirm they were received correctly as a single stream.
- Verification: The server should display the packet data exactly as the client sent it. Run
tcpdumpon the loopback interface (lo) to observe that the data is sent in a single TCP segment.
- Objective: Use
- Configuration File Parser with
readv:- Objective: Use
readvto parse a simple, fixed-format configuration file. - Guidance:
- Create a text file named
app.confwith a strict format, for example:# 16 bytes for hostname, 4 bytes for port, 32 for API key server.local 9001my-secret-api-key-is-here-1234 - Write a C program that uses
readvto read this file. - Set up an
iovecarray with three elements. The first should point to a 16-byte char array for the hostname, the second to auint32_tfor the port (you’ll need to convert from ASCII later), and the third to a 32-byte char array for the API key. - Use
readvto populate these three buffers directly from the file.
- Create a text file named
- Verification: The program should print the parsed hostname, port, and API key. This demonstrates using
readvto map a file format directly onto C structures.
- Objective: Use
- Performance Comparison:
- Objective: Quantitatively measure the performance difference between using
writev, multiplewritecalls, and a singlewritewithmemcpy. - Guidance:
- Create a large file (e.g., 100MB) of random data.
- Write a program that reads this file and writes its contents to
/dev/null. - Implement three writing strategies:a. writev: In a loop, read a chunk of data, but set up an iovec array that points to multiple, smaller (e.g., 1KB) segments within that chunk. Use writev to write these segments.b. Multiple writes: In a loop, read a chunk and then use multiple write calls to write the same small segments as in (a).c. memcpy and write: In a loop, read a chunk, memcpy the small segments into a single large buffer, and then use a single write call.
- Use
gettimeofdayorclock_gettimeto measure the total time taken for each strategy to process the entire 100MB file.
- Verification: Print the elapsed time for each of the three methods. You should observe that
writevis significantly faster than the multiplewriteapproach and competitive with, if not faster than, thememcpyapproach, especially as the number of vectors increases.
- Objective: Quantitatively measure the performance difference between using
Summary
This chapter provided a comprehensive exploration of scatter/gather I/O, a critical technique for high-performance system programming in embedded Linux.
- Core Problem: Standard
read()andwrite()are inefficient when dealing with data scattered across multiple memory buffers, forcing a choice between costly memory copies or multiple, high-overhead system calls. - The Solution: The
readv()andwritev()system calls solve this by allowing an application to perform I/O on a vector of non-contiguous buffers in a single, atomic operation. iovecStructure: Thestruct iovec, consisting of aiov_basepointer andiov_lensize, is the fundamental building block used to describe each buffer segment to the kernel.- Key Benefits: Scatter/gather I/O offers two primary advantages:
- Performance: It reduces system call overhead and eliminates the need for intermediate data copying, leading to lower CPU usage and higher throughput.
- Atomicity:
writevguarantees that all buffers in the vector are written as a single, indivisible unit, preventing data corruption from interleaved writes in multi-process or multi-threaded environments.
- Practical Application: We demonstrated how to use
writevto create structured binary logs andreadvto parse them efficiently, showcasing a common and powerful use case on the Raspberry Pi 5. - Common Pitfalls: Successful implementation requires careful handling of string lengths, understanding the scope of atomicity, preparing for short reads/writes, and respecting the
IOV_MAXlimit.
Mastering readv() and writev() is a significant step toward writing professional, efficient, and robust embedded Linux applications. The principles learned here are directly applicable to a wide range of tasks, from network programming and file format manipulation to device driver interaction.
Further Reading
- Official Linux Man Pages: The most authoritative source for these system calls.
man 2 readvman 2 writev
- The Single UNIX Specification (POSIX): The official standard defining how these functions should behave.
- The Open Group Base Specifications Issue 7, 2018 edition:
readv()andwritev()pages. (https://pubs.opengroup.org/onlinepubs/9699919799/)
- The Open Group Base Specifications Issue 7, 2018 edition:
- “The Linux Programming Interface” by Michael Kerrisk: An exhaustive and highly respected reference for Linux system programming. Chapter 5 provides an excellent in-depth discussion of
readv()andwritev(). - “Advanced Programming in the UNIX Environment” by W. Richard Stevens and Stephen A. Rago: A classic text that covers vectored I/O in the broader context of UNIX system calls.
- “Anatomy of a
writev()system call” – Julia Evans’ Blog: A practical, accessible blog post that walks through the mechanics of thewritevsystem call. (https://jvns.ca/) - Raspberry Pi Documentation: While not specific to
readv, the official hardware and software documentation is essential for any low-level development on the platform. (https://www.raspberrypi.com/documentation/)
