
Chapter 49: File I/O System Calls: read() and write()
Chapter Objectives
By the end of this chapter, you will be able to:
- Understand the central role of file descriptors in the Linux I/O model.
- Implement file reading operations using the
read()system call, correctly handling its return values. - Implement file writing operations using the
write()system call, managing potential partial writes. - Analyze and handle common error conditions associated with file I/O system calls.
- Develop robust C programs that perform fundamental I/O operations on a Raspberry Pi 5.
- Debug common pitfalls related to buffer management and system call return values in file I/O programming.
Introduction
In the world of embedded Linux, the ability to interact with the surrounding environment is paramount. Devices do not operate in a vacuum; they must read sensor data, log events, update configuration files, and communicate over various interfaces. At the heart of these interactions lies a simple yet powerful abstraction: the file. In Linux, and UNIX-like systems in general, nearly every source of input and destination for output—from actual files on a storage device to pipes, sockets, and hardware peripherals—is presented to the programmer as a file. This “everything is a file” philosophy provides a unified and consistent interface for data transfer.
This chapter delves into the two most fundamental operations at the core of this model: reading and writing. We will explore the read() and write() system calls, the primary conduits through which a user-space application requests the Linux kernel to move data. Understanding these low-level functions is not merely an academic exercise. For an embedded systems developer, mastering them is essential for writing efficient, reliable, and predictable code. Whether you are parsing data from a GPS module, controlling a motor driver via a serial port, or simply writing logs to an SD card, the underlying mechanism will be the read() and write() system calls. On the Raspberry Pi 5, these operations are the bedrock upon which higher-level libraries and applications are built, and direct control over them provides the power to optimize for performance and resource usage—critical concerns in any embedded project.
Technical Background
The File Descriptor: A Key to I/O
Before we can read from or write to a file, an application must first announce its intention to the kernel. This is typically done using the open() system call, which was discussed in the preceding chapter. Upon successfully opening a file, the kernel creates an entry in a per-process file descriptor table. It then returns a small, non-negative integer to the application called a file descriptor. This integer is not a memory pointer; it is an index, or a handle, into this kernel-managed table. From that point on, the application no longer refers to the file by its name. Instead, it uses this file descriptor to tell the kernel which open file it wishes to operate on.
This level of abstraction is profoundly important. It decouples the application from the underlying details of the file system or device. The program simply holds a number and uses it with read() or write(). The kernel, using the information it stored in the file descriptor table during the open() call, knows whether the descriptor refers to a file on an ext4 filesystem, a serial port (/dev/ttyS0), an I2C device, or a network socket. The kernel directs the data flow to the appropriate driver, and the application’s code remains blissfully ignorant of these complexities.
Every newly created process in Linux automatically inherits three open file descriptors:
- 0 (Standard Input): By default, this is connected to the keyboard.
- 1 (Standard Output): By default, this is connected to the terminal display.
- 2 (Standard Error): By default, this is also connected to the terminal display.
These standard descriptors are why simple command-line tools can be chained together so effectively using pipes and redirection, a cornerstone of the UNIX philosophy. They are, for all intents and purposes, identical to file descriptors returned by an open() call.
graph TD
subgraph User Space Process
direction LR
A[Process Memory] --> B{"File Descriptor Table<br>(Array managed by Kernel)"};
end
subgraph Kernel Space
direction LR
subgraph "Kernel VFS (Virtual File System)"
K_STDIN[struct file<br><b>Device:</b> Keyboard Driver];
K_STDOUT[struct file<br><b>Device:</b> Terminal Driver];
K_FILE[struct file<br><b>Device:</b> Filesystem Driver<br><b>Path:</b> /home/pi/data.txt];
end
end
subgraph "Hardware / Resources"
direction LR
HW_KBD[Keyboard];
HW_TERM[Terminal Display];
HW_DISK[Physical Disk Drive];
end
B -- "0 (stdin)" --> K_STDIN;
B -- "1 (stdout)" --> K_STDOUT;
B -- "2 (stderr) --> K_STDOUT" --> K_STDOUT;
B -- "3 = open('data.txt', ...)" --> K_FILE;
K_STDIN --> HW_KBD;
K_STDOUT --> HW_TERM;
K_FILE --> HW_DISK;
classDef user fill:#e0f2fe,stroke:#0ea5e9,stroke-width:2px,color:#0c4a6e;
classDef kernel fill:#ede9fe,stroke:#8b5cf6,stroke-width:2px,color:#5b21b6;
classDef hw fill:#f1f5f9,stroke:#64748b,stroke-width:2px,color:#1e2937;
class A,B user;
class K_STDIN,K_STDOUT,K_FILE kernel;
class HW_KBD,HW_TERM,HW_DISK hw;
The read() System Call: Ingesting Data
The read() system call is the fundamental mechanism for requesting data from an open file. Its purpose is to ask the kernel to copy a specified number of bytes from a file, as identified by its file descriptor, into a memory buffer provided by the application.
The function prototype, found in <unistd.h>, is as follows:
ssize_t read(int fd, void *buf, size_t count);
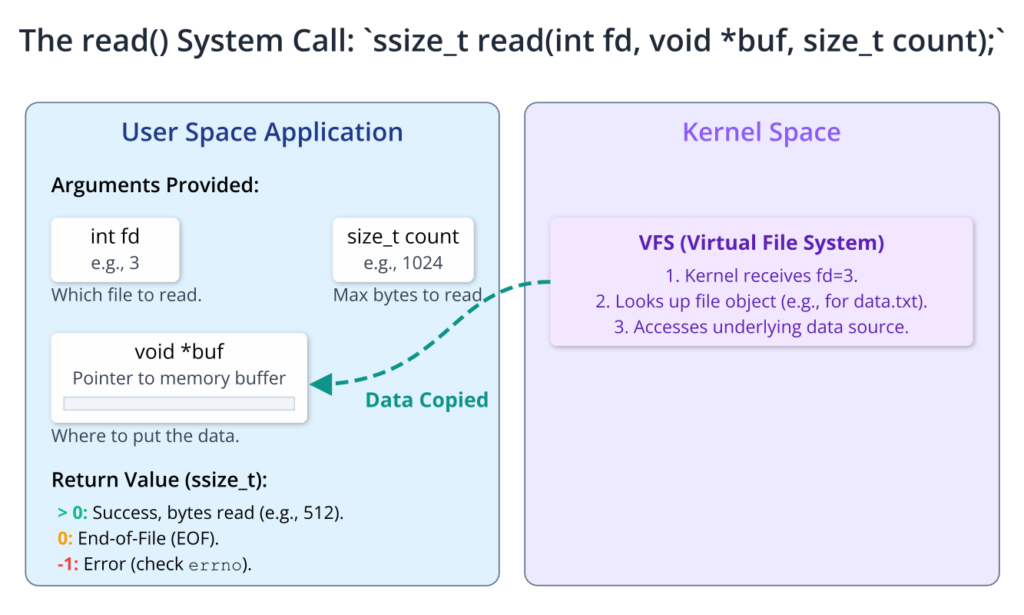
Let’s dissect its components. The first argument, int fd, is the file descriptor obtained from a prior open() call. This tells the kernel which open file to read from. The second argument, void *buf, is a pointer to a region of memory—a buffer—that the application has allocated. This is the destination where the kernel will place the data it reads. The third argument, size_t count, specifies the maximum number of bytes the application wants to read. It is crucial to understand that read() is not guaranteed to read exactly count bytes, a point we will return to shortly.
The return value of read() is of type ssize_t, a signed integer type. Its value is critical for determining the outcome of the operation and must always be checked.
- A positive value: This indicates success. The value returned is the number of bytes that were actually read from the file and copied into the buffer
buf. This can be less than thecountrequested. - Zero (0): This is not an error. A return value of zero signifies end-of-file (EOF). The application has tried to read from a file that has no more data to offer. Any subsequent calls to
read()on this file descriptor will also return 0. - Negative one (-1): This indicates that an error occurred. When
read()returns -1, the global variableerrnois set to a value that provides more specific information about the nature of the failure. For example,errnomight be set toEBADFiffdis not a valid file descriptor, orEIOfor a low-level input/output error on the physical device.
flowchart TD
A("Start: Call read(fd, buf, count)") --> B{Is fd valid and open for reading?};
style A fill:#1e3a8a,stroke:#1e3a8a,stroke-width:2px,color:#ffffff
style B fill:#f59e0b,stroke:#f59e0b,stroke-width:1px,color:#ffffff
B -- "No" --> C[Return -1<br>Set errno = EBADF];
B -- "Yes" --> D{Is there data available in file/buffer?};
style C fill:#ef4444,stroke:#ef4444,stroke-width:1px,color:#ffffff
style D fill:#f59e0b,stroke:#f59e0b,stroke-width:1px,color:#ffffff
D -- "No (End-of-File)" --> E[Return 0];
style E fill:#eab308,stroke:#eab308,stroke-width:1px,color:#1f2937
D -- "Yes" --> F{Attempt to read 'count' bytes};
style F fill:#0d9488,stroke:#0d9488,stroke-width:1px,color:#ffffff
F --> G{"Low-level I/O Error?<br>(e.g., disk failure)"};
style G fill:#f59e0b,stroke:#f59e0b,stroke-width:1px,color:#ffffff
G -- "Yes" --> H[Return -1<br>Set errno = EIO];
style H fill:#ef4444,stroke:#ef4444,stroke-width:1px,color:#ffffff
G -- "No" --> I[Copy data to user's buffer];
style I fill:#0d9488,stroke:#0d9488,stroke-width:1px,color:#ffffff
I --> J["Return number of bytes read<br><i>(Can be < count)</i>"];
style J fill:#10b981,stroke:#10b981,stroke-width:2px,color:#ffffff
A common scenario where read() returns fewer bytes than requested is when reading from a terminal or a pipe. If the user only types 10 characters and presses Enter, a read() call requesting 100 bytes will return 10. It will not wait for more data. Similarly, when reading near the end of a regular file, if there are only 20 bytes left and the application requests 50, read() will successfully read the remaining 20 bytes and return the value 20. The next call will then return 0 to signal EOF. This behavior means that robust code must not assume a single read() call will fill its buffer. It should be prepared to call read() in a loop until all required data is received.
The write() System Call: Sending Data
The write() system call is the counterpart to read(). It requests that the kernel copy a specified number of bytes from an application’s memory buffer to an open file.
Its prototype is symmetric to read():
ssize_t write(int fd, const void *buf, size_t count);
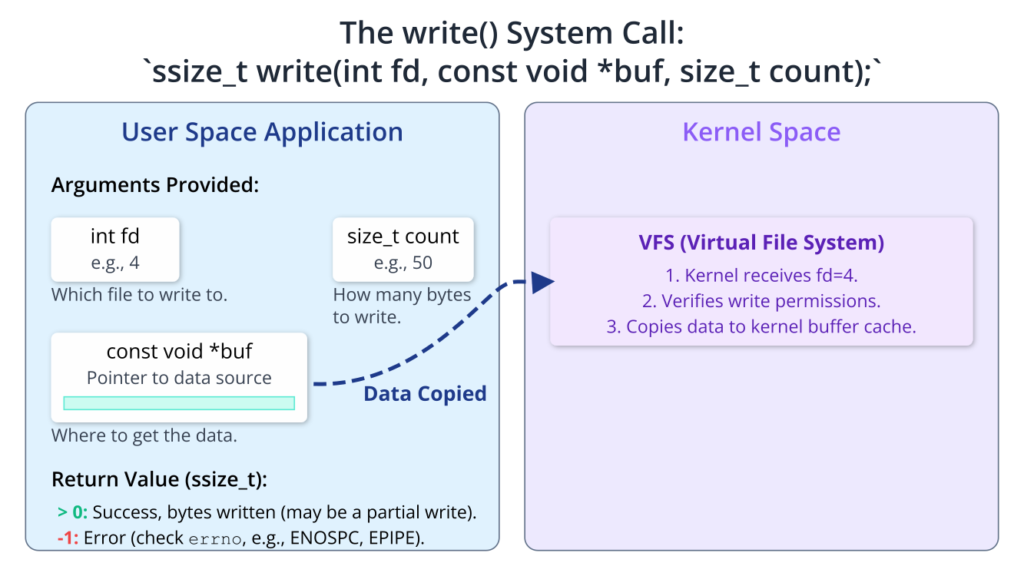
Here, fd is the file descriptor for the destination file, which must have been opened with write permissions. The const void *buf argument is a pointer to the buffer containing the data the application wants to write. The const keyword indicates that the function will not modify this buffer. Finally, size_t count is the number of bytes to be written from the buffer.
The return value of write() is also of type ssize_t and follows a similar logic:
- A positive value: On success,
write()returns the number of bytes that were actually written. Just likeread(), this value might be less thancount. This is known as a partial write. - Negative one (-1): This indicates an error occurred. As with
read(), theerrnovariable will be set to indicate the specific error. Common errors includeEBADF(bad file descriptor),ENOSPC(no space left on device), orEPIPE(writing to a pipe or socket that the reading end has closed).
Partial writes are a critical concept. While writing to a regular file on a modern filesystem will often write all requested bytes in one go, this is not a guarantee. For instance, if the write operation is interrupted by a signal, a partial write may occur. More commonly, when writing to slow devices or network sockets, the kernel’s internal buffers might fill up, causing write() to transfer only a portion of the data before returning. A robust program must handle this possibility by placing the write() call inside a loop that continues until all bytes have been successfully written. The loop would need to adjust the buffer pointer and the remaining byte count after each partial write.
flowchart TD
A("Start: robust_write(fd, buffer, total_to_write)");
style A fill:#1e3a8a,stroke:#1e3a8a,stroke-width:2px,color:#ffffff
A --> B[Initialize:<br>bytes_left = total_to_write<br>ptr = buffer];
style B fill:#0d9488,stroke:#0d9488,stroke-width:1px,color:#ffffff
B --> C{bytes_left > 0?};
style C fill:#f59e0b,stroke:#f59e0b,stroke-width:1px,color:#ffffff
C -- "No" --> D(Success: All bytes written);
style D fill:#10b981,stroke:#10b981,stroke-width:2px,color:#ffffff
C -- "Yes" --> E["Call write(fd, ptr, bytes_left)"];
style E fill:#8b5cf6,stroke:#8b5cf6,stroke-width:1px,color:#ffffff
E --> F{bytes_written == -1?};
style F fill:#f59e0b,stroke:#f59e0b,stroke-width:1px,color:#ffffff
F -- "Yes" --> G{"errno == EINTR? <br><i>(Interrupted by signal)</i>"};
style G fill:#f59e0b,stroke:#f59e0b,stroke-width:1px,color:#ffffff
G -- "Yes" --> E;
G -- "No" --> H(Error: Handle failure);
style H fill:#ef4444,stroke:#ef4444,stroke-width:1px,color:#ffffff
F -- "No" --> I[Update state:<br>bytes_left -= bytes_written<br>ptr += bytes_written];
style I fill:#0d9488,stroke:#0d9488,stroke-width:1px,color:#ffffff
I --> C;
Atomicity and Buffering
An operation is atomic if it happens entirely or not at all, without the possibility of being interrupted in the middle. The read() and write() system calls themselves are atomic at the system call level. When your process executes a write() call, the kernel guarantees that it will not be interrupted midway through its internal processing to let another process’s write() call to the same file descriptor intercede.
However, this does not guarantee that the data from a single write() call will be written contiguously if multiple processes are writing to the same file using different file descriptors (obtained from separate open() calls). For writes up to PIPE_BUF bytes (a system-defined constant, often 4096 bytes on Linux), writes to a pipe are guaranteed to be atomic. This means if two processes write messages smaller than PIPE_BUF to the same pipe, the data from each message will not be interleaved. For larger writes, the kernel may break the data into smaller chunks, and interleaving can occur.
sequenceDiagram
actor P_A as Process A
actor P_B as Process B
participant Pipe as Pipe Kernel Buffer
P_A->>Pipe: write(pipe_fd, "AAAA", 4)
P_B->>Pipe: write(pipe_fd, "BBBB", 4)
Note over Pipe: Writes are < PIPE_BUF (e.g., 4096 bytes).<br>Kernel guarantees atomicity.
loop Uninterleaved Read
participant R as Reading Process
R->>Pipe: read() -> "AAAABBBB" or "BBBBAAAA"
end
par
P_A->>Pipe: write(pipe_fd, "LONG_MESSAGE_A", 8192)
and
P_B->>Pipe: write(pipe_fd, "SHORT_B", 7)
end
Note over Pipe: Write from P_A is > PIPE_BUF.<br>Kernel may break it up.<br>Interleaving is now possible.
loop Interleaved Read
R->>Pipe: read() -> "LONG_MESSAGE_...SHORT_B...A"
end
Another important concept is buffering. When you call write(), the data is not necessarily sent immediately to the physical disk or network card. The kernel first copies the data from your user-space buffer into its own internal memory, known as the kernel buffer cache or page cache. It then returns control to your application, which can continue its work. The kernel writes the data from its cache to the physical device at a later, more opportune time (a process called write-behind caching). This dramatically improves performance by batching many small writes into larger, more efficient ones.
The downside is that if the system crashes (e.g., a power failure) after write() has returned but before the kernel has flushed its buffers to disk, the data will be lost. For critical data, applications can request an immediate, synchronous write to the physical media using system calls like fsync() or by opening the file with the O_SYNC flag. This forces the kernel to wait until the data is physically stored before write() returns, but it comes at a significant performance cost. Similarly, read() operations are also buffered. When you request to read from a file, the kernel may read a larger block from the disk into its cache, anticipating that you will soon request the subsequent data. The next read() call can then be satisfied directly from this fast kernel memory without needing a slow disk access.

Practical Examples
This section provides hands-on examples for the Raspberry Pi 5. You will need a Raspberry Pi 5 running Raspberry Pi OS (or a similar Linux distribution) and a C compiler (gcc), which is installed by default.
Example 1: Creating and Writing to a File
This first example demonstrates the fundamental sequence of opening a new file, writing a string of text to it, and then closing it. This is the “Hello, World” of file I/O.
Build and Configuration Steps
- Open a terminal on your Raspberry Pi 5.
- Create a new file named
writer.cusing a text editor likenanoorvim.nano writer.c - Enter the C code below into the file.
Code Snippet: writer.c
#include <stdio.h> // For perror()
#include <fcntl.h> // For open() and file constants
#include <unistd.h> // For write(), close()
#include <string.h> // For strlen()
#include <errno.h> // For errno
int main() {
const char *filepath = "greeting.txt";
const char *message = "Hello, Embedded Linux on Raspberry Pi 5!\n";
int fd; // File descriptor
// Open the file for writing.
// O_CREAT: Create the file if it doesn't exist.
// O_WRONLY: Open for writing only.
// O_TRUNC: Truncate the file to zero length if it exists.
// 0644: File permissions (owner can read/write, group/others can read).
fd = open(filepath, O_CREAT | O_WRONLY | O_TRUNC, 0644);
if (fd == -1) {
// If open() failed, print an error message and exit.
perror("Error opening file");
return 1;
}
printf("File '%s' opened successfully. File descriptor is %d.\n", filepath, fd);
// Write the message to the file.
size_t bytes_to_write = strlen(message);
ssize_t bytes_written = write(fd, message, bytes_to_write);
if (bytes_written == -1) {
// Handle write error.
perror("Error writing to file");
close(fd); // Attempt to close the file descriptor anyway.
return 1;
}
if (bytes_written != bytes_to_write) {
// This is a rare case for regular files but good practice to check.
fprintf(stderr, "Warning: Partial write occurred.\n");
}
printf("Successfully wrote %ld bytes to the file.\n", bytes_written);
// Close the file descriptor.
if (close(fd) == -1) {
perror("Error closing file");
return 1;
}
printf("File closed successfully.\n");
return 0;
}
Build, Flash, and Boot Procedures
This example runs directly on the Raspberry Pi, so there is no cross-compilation or flashing procedure.
- Compile the code: Use
gccto compile the C source file into an executable program namedwriter.gcc writer.c -o writer - Run the executable:
./writer - Verify the output: First, check the terminal output from the program.Expected Output:
File 'greeting.txt' opened successfully.File descriptor is 3.Successfully wrote 43 bytes to the file.File closed successfully.Tip: The file descriptor is likely to be 3 because 0, 1, and 2 are already in use for standard input, output, and error. - Check the file contents: Use the
catcommand to display the contents of the newly created file.cat greeting.txtExpected File Content:Hello, Embedded Linux on Raspberry Pi 5!
Example 2: Reading from a File
Now, let’s create a program that reads the content from the greeting.txt file we just created and prints it to the standard output. This example highlights the importance of using a loop to handle reads.
Build and Configuration Steps
- Create a new file named
reader.c.nano reader.c - Enter the following C code.
Code Snippet: reader.c
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <errno.h>
#define BUFFER_SIZE 32 // Use a small buffer to demonstrate looping
int main() {
const char *filepath = "greeting.txt";
int fd;
char buffer[BUFFER_SIZE];
ssize_t bytes_read;
// Open the file for reading only.
fd = open(filepath, O_RDONLY);
if (fd == -1) {
perror("Error opening file for reading");
return 1;
}
printf("File '%s' opened. Reading contents...\n---\n", filepath);
// Loop until read() returns 0 (EOF) or -1 (error).
while ((bytes_read = read(fd, buffer, BUFFER_SIZE)) > 0) {
// Successfully read some bytes. Now write them to standard output (fd 1).
ssize_t bytes_written = write(STDOUT_FILENO, buffer, bytes_read);
if (bytes_written != bytes_read) {
perror("Error writing to stdout");
close(fd);
return 1;
}
}
printf("\n---\nFinished reading file.\n");
// After the loop, check if an error occurred.
if (bytes_read == -1) {
perror("Error reading from file");
}
// Close the file.
if (close(fd) == -1) {
perror("Error closing file");
return 1;
}
return 0;
}
Build and Execution
- Compile the code:
gcc reader.c -o reader - Run the executable:
./readerExpected Output:File 'greeting.txt' opened.Reading contents...---Hello, Embedded Linux on Raspberry Pi 5!---Finished reading file.
This example intentionally uses a small buffer (BUFFER_SIZE of 32). Since our message is 43 bytes long, the read() loop will execute twice. The first call will read 32 bytes and return 32. The while condition is true, and those 32 bytes are written to standard output. The second call to read() will attempt to read another 32 bytes, but only 11 are left in the file. It will read those 11 bytes and return 11. The loop writes them to standard output. The third call to read() finds no more data and returns 0, terminating the loop.
Example 3: A Simple cp Utility
Let’s combine these concepts to create a simple version of the cp command. This program will take two command-line arguments: a source file and a destination file. It will read from the source and write to the destination.
File Structure
.
├── simple_cp.c
├── source.txt (We will create this)
└── destination.txt (The program will create this)
Code Snippet: simple_cp.c
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <errno.h>
#define BUFFER_SIZE 4096
int main(int argc, char *argv[]) {
if (argc != 3) {
fprintf(stderr, "Usage: %s <source_file> <destination_file>\n", argv[0]);
return 1;
}
const char *source_path = argv[1];
const char *dest_path = argv[2];
int src_fd = open(source_path, O_RDONLY);
if (src_fd == -1) {
perror("Error opening source file");
return 1;
}
// Create destination file with permissions rw-r--r--
int dest_fd = open(dest_path, O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (dest_fd == -1) {
perror("Error opening destination file");
close(src_fd);
return 1;
}
char buffer[BUFFER_SIZE];
ssize_t bytes_read;
// The core copy loop
while ((bytes_read = read(src_fd, buffer, BUFFER_SIZE)) > 0) {
// We read bytes_read bytes, now we must write exactly that many.
ssize_t bytes_written = write(dest_fd, buffer, bytes_read);
if (bytes_written != bytes_read) {
perror("Error writing to destination file (or partial write)");
// Clean up and exit on error
close(src_fd);
close(dest_fd);
return 1;
}
}
// Check for a read error after the loop
if (bytes_read == -1) {
perror("Error reading from source file");
}
printf("File copy successful.\n");
// Close both files
close(src_fd);
close(dest_fd);
return 0;
}
Build and Execution
- Create a sample source file:
echo "This is a test file for our simple_cp utility." > source.txtecho "It contains multiple lines of text." >> source.txt - Compile the program:
gcc simple_cp.c -o simple_cp - Run the copy utility:
./simple_cp source.txt destination.txt - Verify the result:
cat destination.txtExpected Content ofdestination.txt:This is a test file for our simple_cp utility.It contains multiple lines of text.Now, compare it with the original using thediffcommand.diff source.txt destination.txtIf the files are identical,diffwill produce no output, confirming our utility worked correctly.
Common Mistakes & Troubleshooting
When working with low-level I/O, several common pitfalls can lead to bugs that are often subtle and hard to diagnose. Understanding these in advance can save hours of debugging.
Exercises
- Simple
catUtility: Write a C program namedsimple_catthat takes one command-line argument: a filename. The program should open the specified file, read its contents, and write them to standard output (file descriptor 1). If no filename is provided, it should read from standard input (file descriptor 0) until end-of-file is reached (Ctrl+D in the terminal). This will mimic the basic behavior of thecatcommand. - Robust
writeLoop: Modify thewriter.cexample to use a dedicated function,robust_write(), that takes a file descriptor, a buffer, and a byte count as arguments. This function must contain a loop that repeatedly callswrite()to handle any potential partial writes, ensuring that all data is written. It should return 0 on success and -1 on failure. Test this function by writing a large block of data (e.g., 1MB) to a file. - Appending to a File: Create a program named
log_messagethat takes a single string argument from the command line. The program should open a file namedsystem.login append mode (O_APPEND). It should then write the message from the command line to the end of the file, followed by a newline character. Run the program multiple times with different messages and verify withcat system.logthat each message is added to the end of the file. - Error Reporting to
stderr: Create a program that attempts to open a non-existent file for reading. When theopen()call fails, it should usedprintf()orfprintf(stderr, ...)to write a user-friendly error message to standard error (file descriptor 2), not standard output. The message should include the name of the file that failed to open. Demonstrate the difference by redirecting standard output and standard error separately (e.g.,./my_program > out.txt 2> err.txt). - Reversing a File’s Contents: Write a program that takes two arguments, an input file and an output file. The program should read the entire contents of the input file into a dynamically allocated buffer in memory. Then, it should write the contents of that buffer to the output file in reverse order (last byte first). This exercise requires careful management of file offsets and memory. (Hint: Use
lseek()to find the file size to allocate the buffer, then read the whole file. Then, write the buffer out byte-by-byte in a reverse loop).
Summary
- File Descriptors are Handles: In Linux, all I/O operations are performed using file descriptors, which are small integers that act as handles to kernel-managed file objects.
- Standard I/O: Every process starts with three open file descriptors: 0 (stdin), 1 (stdout), and 2 (stderr).
read()for Input: Theread(fd, buf, count)system call is used to read up tocountbytes fromfdintobuf. Its return value indicates the number of bytes read, end-of-file (0), or an error (-1).write()for Output: Thewrite(fd, buf, count)system call is used to writecountbytes frombuftofd. Its return value indicates the number of bytes written or an error (-1).- Handling Incomplete Operations: Code must be robust against partial reads and writes. A single call to
read()orwrite()is not guaranteed to transfer the full number of bytes requested. Looping is the standard technique to ensure completeness. - Error Checking is Mandatory: The return values of all system calls, especially I/O calls, must be checked to detect and handle errors. The
errnovariable provides specific details after a call fails. - Resource Management: File descriptors are a finite resource. Every file descriptor obtained from
open()must be released withclose()to prevent resource leaks.
Further Reading
- Linux man-pages: The authoritative source. On your Raspberry Pi, you can type
man 2 read,man 2 write, andman 2 open. - The Linux Programming Interface by Michael Kerrisk. Chapters 4 and 5 provide an exhaustive and highly respected treatment of file I/O.
- Advanced Programming in the UNIX Environment by W. Richard Stevens and Stephen A. Rago. A classic text that provides deep insights into the UNIX I/O model.
- Raspberry Pi Documentation – The Linux kernel: https://www.raspberrypi.com/documentation/computers/linux_kernel.html – For understanding the underlying OS on the target hardware.
- LWN.net: A premier source for in-depth articles on Linux kernel development, including the intricacies of the I/O subsystems. Search for articles related to the VFS (Virtual File System).
- Buildroot Manual: https://buildroot.org/downloads/manual/manual.html – While not directly about system calls, understanding how an embedded Linux system is built provides context for file system and device driver integration.
- Yocto Project Mega-Manual: https://docs.yoctoproject.org – Similar to Buildroot, provides essential context for professional embedded Linux development environments.
